

���̃y�[�W�ł́A���ЂŊJ������IP��g�����X���[�^���g����VHDL�R�A��Verilog�ɖ|�����́AOpencores��Verilog�����Љ�Ă����܂��B
�Ƃ肠�����A�����̐v���ʂ��āACPU�A�[�L�e�N�`���AHDL�R�[�f�B���O�Z�@�̌����ɂ����ɂȂ�K���ł��B
1.�x���`�}�[�N�e�X�g
�@�@����C�\�[�X�v���O�������V�~�����[�^��œ������đ��N���b�N����]�����Ă݂܂��BC�\�[�X�v���O�����́A���[�h�\�������i�T�C���^�[���[�u�A3�d�����j�ł��B���L�I�[�v���\�[�X�R�A�ɂ��čs���܂����B
�쓮���g���̔�r�ł͂Ȃ�CPI�̔�r�ł��邱�ƂƁA�I���W�i���Ƃ̔�r�ł͂Ȃ��AOpencores��ł̔�r�ł��邱�Ƃɒ��ӂ��Ă��������B
- SH2
- T80( translated to Verilog by automatically with Veritak Translator)
- TV80 (T80�̉��ɂ���܂��B�j
- WB_Z80(T80�̉��ɂ���܂��B�j
- FZ80(T80 �̉��ɂ���܂��B�j
- AVR
- 8051�iREV.1.01�j
- MIPS R3000�iMay.12.2004 Update�F Synthesizable on Altera CYCLONE)
- H8300H( Jun.9.2004)
- Openrisc (May.6.2005�j
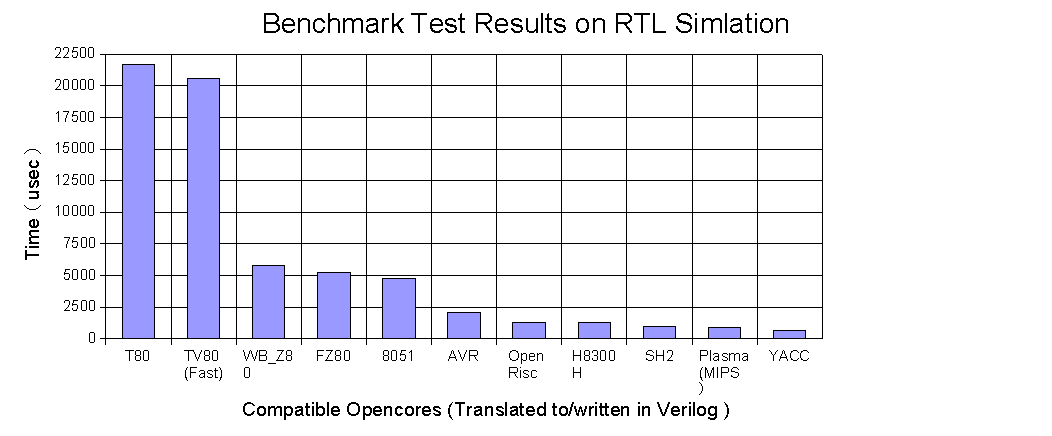
���ӁF�R���p�`�u���R�A�́A�I���W�i���Ɩ��߂̎��s�X�e�[�g�����قȂ�܂��B�����܂ŃI�[�v���\�[�X�R�A��̎��s���Ԕ�r�ł��邱�Ƃɒ��ӂ��Ă��������B
���̕]���̊ϓ_�Ƃ��ẮA�����N���b�N���g���ŋ쓮���Ă��܂��̂ŁiRTL�V�~�����[�V�����A���z�T�OMH���j�A���ԁ��N���b�N���ł悢�Ǝv���܂��BC�R���p�C�����܂߂�CPI�̕]���ɋ߂����ƂɂȂ�܂��B
�܂��A8�r�b�g���Z����̂Ȃ̂ŁA8�r�b�gCPU�ɂƂ��ĕs���ɂ͂Ȃ�Ȃ��i8�r�b�gCPU�����ӂȂ͂��́j�x���`�}�[�N�ɂȂ��Ă��܂��B
�@�ʔ����̂́A��̐v���㏇�ɕ���ł��邱�Ƃł��B
H8300H�́A�M�҂ɂ��vVersion�ł����A�I���W�i�����R0%�ȏ�CPI�����������Ă��邽��AVR��葬�����ʂɂȂ��Ă��܂����A�I���W�i���̎��s�X�e�[�g���ł�AVR�Ɠ����ł͂Ȃ����Ɛ��@���܂��B
����ɁAAVR�͔�r�I�ŋ߂̐ł��Q�[�g����H8�R�O�OH���͂��Ȃ菭�Ȃ��ƌ����܂��BCISC����RISC�̗���A�A�[�L�e�N�`���̐i�������̃O���t����ǂ݂Ƃ��Ǝv���܂��B
����ȗ���̒��ŁARISC�̑������I���݂ł���MIPS��80�N��̐v�ł��B
MIPS�̐挩������Ă��܂��ˁB�I���W�i��CPU��v����ɂ������Ăǂ���K�͂ɂ���ׂ����Q�l�ɂȂ�̂ł͂Ȃ��ł��傤���H
�@�Ȃ��AYACC�͕M�҂ɂ��v�ł�͂�PLASMA�Ɠ���MIPS�A�[�L�e�N�`�����K�͂ɂ��Ă��܂��B
�ڍׂ��AYACC�v���W�F�N�g�̃y�[�W�����Q�Ƃ��������B
�܂��A�I���W�i��CPU������Ă�����������܂����BYACC�Ɣ�r���Ă��������Ă��܂��B�Ȃ��200MHz�I�[�o�Ƃ�����������ł��B�������ADMIPS/MHz��1���鎖��_���Ă���Ƃ����������2�{�ł��B
�i�V���O���łP����̂́A���Ȃ�̍œK���R���p�C�����Ȃ��ƁA�������������܂��B�j
�ł��A�A�C�f�A��������ŁACPU������Ă��܂��B�B���̏��́A�����D���Ō��Ă��Ă��y�����ł��B�A�[�L�e�N�`�����玩�삷��̂́A�{���Ɋy�������̂ł��B
MAX2�œ����A�I���W�i��CPU�삵�Ă݂܂����B�͂�240�Z���œ��삵�܂��BCPU�v�̓���҂Ƃ��������ł����A16�r�b�g���Z�Ńp�^�[���������ł��A���p�����Nj����Ă��܂��B
�B�܂��AVPI�ō쐬�������͂�Visual�f�o�b�K���t�����Ă���ACPU�̓��쌴���̗����ɖ𗧂Ǝv���܂��B
<Z80�ɂ���>
PC8001�ŗL����FZ80�R�A��lj����܂����B
FZ80���AWB_Z80���čő���CPI�AZ80�R�A�ƂȂ�܂����B4�{��Z80�R�A�����낢�܂����B�����@�\������������̂ł���Ȃ���A����Coding���@�̈Ⴂ������Ɩʔ����ł��傤�BT80��TV80�́ABehavior�ŏ����Ă��܂��B
����AWB_Z80/FZ80�̓Q�[�g���x���ɋ߂������������Ă��܂��B������̍����o�₷���̂́A���ۓx�̍���Behaivor�ŁA�_�������\�ƃQ�[�g���Ō��ʂ����悢�̂́A
�Q�[�g���x���ɋ߂��i��H�}�ɋ߂��j�����������Ă�����ł��傤�BFZ80�́A�R���p�C���̕n�㐫������8051�ɔ��鐦�����̂�����܂��B�������A���̃R�A���AVersion1.04�ȑO�ł́A���̃x���`������܂���ł����B
���J�������ۂɎg���遁��Feedback�Ƃ����T�C�N���̐}��������悤�Ɏv���܂��B���̗���ɂ��܂����Ǝ��R�Ɗ����x���オ���Ă����̂ł́H�Ǝv���܂����B
���̂ق���6502���g�����R�A������̂ł����A�K����C�R���p�C���������炸�A���ۏ�ԂɂȂ��Ă��܂��B
CPU�A�[�L�e�N�`���̌����ɂ́AMIPS�A�[�L�e�N�`������͂��邱�Ƃ������߂��Ă��܂��B
Z80���͂邩�ɃV���v���ȃf�R�[�_�́A����Ƃ��čł��K���Ă���Ǝv���܂��BSimple�@is�@best�̐v�v�z���т��ꂽ�A�[�L�e�N�`���ɂȂ��Ă��܂��B���Ƃ��AH�W��ALU�L�q��YACC��ALU�L�q�A�f�R�[�_���r���Ă݂Ă��������B�@
�f�R�[�_�̔�r�́AYACC��5�i�p�C�v���C�����A������̑��x�ő����ӎ��O�ꂵ���������ɂȂ��Ă���̂ŒP���Ȕ�r�͂ł��Ȃ��̂ł����A�\�[�X�����Ă�����������̃V���v��������������ł��傤�B�@
�܂��A�L���ȃw�l�p�^�{�̃��f��CPU�@DLX�́AMIPS�A�[�L�e�N�`���̌��_�ɂȂ��Ă��܂��B�iDLX�̃R���p�C����T����茻����GCC������܂��B�j
�@�����āANios�U�i�A�[�L�e�N�`�����ύX����܂����B�j�AMicroBlaze���AMIPS�A�[�L�e�N�`���ɍ������Ă��邱�Ƃɂ��C�Â��ł��傤���H
�n�[�h�E�F�A���V���v������������̑��x���グ�₷�������쓮���g��UP����DMIPS�̌���A�Ƃ����}���ɂȂ��Ă��܂��B��}�́ACPI�ł̔�r�ł����A������̑��x�iDMIPS)�ł́A����ɍ����J�����ƂɂȂ�܂��B
SH2��RISC��RISC�Ȃ̂ł����A16�r�b�g�ɖ��߂����߂�@�\��CISC�I�Ȗ��߂��������肵�āAMIPS�A�[�L�e�N�`�����f�R�[�_�̕��S�́A�d���͂��ł��B
�@
Openrisc���U���Ȃ��̂́A1�|�[�gRAM�ŋ쓮���Ă��邱�Ƃ�����܂����A�L���b�V����MMU��ςނƂ��̕��̃I�[�o�w�b�h���傫���Ȃ邹���ł��傤�B�iPLASMA�́A1�|�[�gRAM�쓮�ŁA����Ƃ̔�r�ł��B
�����FDATA /Instruction���WKB�L���b�V���jDIV���Z��Native�ŃT�|�[�g���Ă��Ȃ����Ƃ������āA�R�[�h�T�C�Y����剻����̂��C�ɂȂ�܂����B����ɂ��Ă��A���������撣���͂��Ȃ̂ł����B�B
�蕨����ŁA�o�ꂵ�������ɂ�����Ǝ₵���C�����܂��B
�����v�����̂́Aopencores����Â���ADamjan Lampret�Ƃ����l�ŁA�����X���x�j�A�A�����u�����i��w�̈�w���Ƃ����̂́A���Q�ɒl���܂��B����AOpencores���ǂ̂悤�Ȉʒu���߂�̂������[���ł��B
�@
2. AES�R�A�i�I���j
�@�@CQ�o�ŎЂ̃f�U�C���E�F�[�u�R���e�X�g�Q�O�O�S�ɉ��債���v���|�[�g�ł��i���M�C�����Ă��܂���j�B
�@�@AES�͎������DES�ɑ���Í��R�A�ł��B�ۑ�́AAES�Ɏg����SUBBYTES�Ƃ������i��v������̂ł������A���ꂾ���ł́A���p�I�ł͂Ȃ��̂ŁAAES���̂��̂�v���Ă��܂��܂����B
���\�C�������Đv�����̂ł����A�ɂ������w�͏܂Ƃ������ʂɏI���܂����B
�Ƃ͂����ALUT2500���x�iLUT�����Ȃ�G���t�^�ɂ��Ă���FPGA�ɓ���܂��B�j�ŁACLOCK200MHz���A�X���[�v�b�g2.7G�������́AFPGA�Ƃ��Đ��E�ő��ł͂Ȃ����Ǝv���܂��B
�{�R�A�́ATOP�K�w�Ńp�C�v���C������FIFO���C���X�^���X�����Ă���̂ŁA�e�ՂɊg���ł���悤�ɂ��Ă��܂��B���_�I�ɂ́A�C���X�^���X�����P�O�ɂ���A10�{�̃X���[�v�b�g�ɂȂ锤�ł����A��������Ƃ������肷��悤�Ȍ��ʂɂȂ�܂��B
�����FPGA�ŁA���E�ɋ߂��g����������Ɣz���x�����{�g���l�b�N�ƂȂ邽�߂ł��B���ł��Ȃ��_����5ns���Ă��܂����ƂɈ��R�Ƃ��Ă��܂��܂��BFPGA�ł���K�͂ȃ��W�b�N�͂�����ƃt���[�A�v���������Ȃ��Ƃ����Ȃ��Ƃ������Ƃł��傤�B
3.H8�݊�CPU�̐v�iUnder�@Development Jul.28.2004�@Update�j
�I�[�v���R�A�Ŗ����N����ڂ����Ă��Ȃ����́A��r�I���W���[�AGCC���������̂Ƃ������ƂŁAH8300H��v���Ă݂܂��B
�Ƃ肠�����A�d�l�́A��v�Ȗ��߂���荞�T�u�Z�b�g�d�l�Ƃ��܂��B
���㕨��CPU�Ȃ̂ŁA�I���W�i��CPU�v�ׂ̃��t�@�����X�ɂ͂Ȃ蓾�܂��A��{�I�Ȑv��@�́A�}�C�N���v���Z�b�T�̎d�g�݂𗝉������ŎQ�l�ɂȂ�Ǝv���܂��B
�V�~�����[�^��Ńh���C�X�g�[���x���`���v�����܂����B
H8�@BASIC���Ȃ�ƃA�Z���u���ŏ����Ă�������݂��܂����B���̂����V��ł݂����Ǝv���܂��B
���v�]�����������Ă��܂����A������YACC�Ɣ�ׂ��DMIPS/���\�[�X�䂪1/20���炢�ɂȂ��Ă��܂��̂ŁA���`�x�[�V�������Ⴂ�ł��B
CPI�d�����̂ĂāA���S�ȃ}�C�N���R�[�h�����iROM���j���������A���\�[�X�����Ȃ��ł��AFPGA�������ȁA�Ǝv���܂��B
�RE�̃X�^�[�^�ł́A32MB��RAM����������Ă���悤�Ȃ̂ŁA
UCLINUX�̂悢�v���b�g�t�H�[���ɂȂ�\��������܂��B
�Ȃ�ƁAH8�ŁATCP/IP�������Ă�����������܂����B����́A�ʔ����ł��B�����AH8�v���W�F�N�g�œ����悤�ɂ�����AC����ƁAFPGA�ƁA
CPU�ƃA�Z���u���ƃC�[�T�l�b�g��TCP/IP��Verilog-2001���ꏏ�ɕ��ł���i�V�ׂ�j�A�������ς̂悤�Ȑ����v���W�F�N�g�ɂȂ邱�Ƃł��傤�H�I
�i�RE�́ALAN��PHY�����Ă���悤�ł��B�j
�@�J��Snapshot�@
�Ȃɂ��ς���Ă��܂��ARTL�\�[�X��Veritak�@Project�ł��B�c�[���̃\�[�X���ǂ����玝���Ă������Y��Ă��܂��܂����B
HEX�t�@�C���́A��̓����x���`�}�[�N�ɂȂ��Ă��܂��B�i�������́AAltera���C�u�������g�p���Ă��܂����A�A�[�J�C�u�́A�܂�ł��܂���B
�ʓr�Aaltera_mf.v ��COPY�Aset ���Ă��������B�j
�S�DYACC�v���W�F�N�g�iYet�@Another�@CPU�@CPU�̗�??�ł��B �@ Opencores���y�[�W�ł��B�j
=>
���̂悤�Ȏ��₪����܂����̂ŁA�����܂Ƃ��Ȋ��荞�݃R���g���[�����L�q���Ă݂����Ǝv���܂��B
Hi Tak-san,
Couple of months ago I successfully interfaced Yacc with a dsp hardware blocked. I was able to program hardware blocks configuration registers and share its RAMS.
Now I want to interface interrupts generated by the hardware block to YACC.
The main idea is that when once the hardware block has finished its job it raises the interrupt.
This interrupt causes the yacc to jump to a interrupt service routine which inspects some registers, sets up the next task and returns to normal execution.
�܂��A�}���`�^�X�N�X�C�b�`����AVCM�ɂ��f�W�^���T�[�{�R���g���[�����L�q���A�T�[�{�V�~�����[�V�������ėV��ł݂܂��傤�B�B
���}���`�^�X�N�X�C�b�`����
OS���K�v�ȃ��x���ł͂Ȃ�����ǂ��^�X�N�͕��������A����ȑg�ݍ��ݗp�r�ɂт�����ł��B�e�^�X�N�́A
�@task_switch();
���ĂԂ��ƂŐ�ւ��܂��B�@�Ⴆ�AUART�̏o�͂����Ȃ���A�R�}���h������ĉ�͂�����B�B�����̃^�X�N�́A�����̎d�����Ђƒi��������A����
�^�X�N�ɃX�C�b�`���܂��B���Ԃ�����Ă�����A�܂����������邱�Ƃ��Ď��ɓn���܂��B�^�X�N�����Ԃɉ�邾���ł����A�e�^�X�N�́A��p�̃X�^�b�N�������Ă���̂ŁA
�����̎d���ɐ�S�ł��܂��BMIPS�̏ꍇ32�����W�X�^������̂ŁA�^�X�N��ւ��̃I�[�o�w�b�h���傫���̂ł����A�����͂悵�Ƃ��܂��傤�B
�T�[�{�́A��莞�Ԗ��̏������K�v�Ȃ̂ŁA��L�Ƃ͕ʂ�Timer���荞�݂ɂ��ŗD�揈���ɂȂ�܂��B
�Ƃ肠�����A
�@�E���荞�݃R���g���[���̎d�l���߁B
�@�EHDL�L�q
�@�E���荞�݃��[�`���̐��`�L�q
�@�E�^�X�N�X�C�b�`�̋L�q
�@�E�f���T�[�{�̎d�l����
�@�E�T�[�{�R���g���[���̋L�q
�@..
���\����܂��ˁB�B
�ŏI�I�ɂ́A�V�~�����[�^��ŁACPU�������ăT�[�{���O���ɂ߂����ɖڕW�ɒǏ]����l�q�����Ă݂����Ǝv���܂��B
YACC�ɂ��ẮA�O���p�X�ɐڑ��\��CPU�̐v�Ƃ������Ƃ��������ōĐv���ł��B
DWM�f�U�C���R���e�X�g2006�㋉�ۑ������
�V�X�e��(�A���S���Y���E�A�[�L�e�N�`��)�v�Ɏn�܂�ARTL�@�R�[�f�B���O�A�Q�[�g�V�~�����[�V�����ƁA���Ƃ��Ă����܂Ƃ܂����L�q�Ƃ����̂́A
��Ƃ�E�������̉���ɂ�����̂ŁA���܂���J����Ă��Ȃ��悤�Ɏv���܂��BVerilog�@HDL�ʼn���I�������̂́A�܂���Ȃ�ɂ��P��̌���őS�Ă��L�q�ł��邱�Ƃł��B
���́A
- �V�X�e��(�A���S���Y���E�A�[�L�e�N�`��)�v
- RTL
- �Q�[�g���x��
�R���e�X�g�Ƃ������ʂ̑�ނ���āA��́i���p�I�ȁjIP���쐬���邱�Ƃ��y����ł��܂����A�����ł��Q�l�ɂȂ�L�q��������K���ł��B
�P��̃R���e�X�g�̋G�߂ɂȂ�܂����B�������_����݂̏o�肪�����̂ł����A���N�̖��́A���ł͂Ȃ��ł��傤���H
���̐ϕ����̃f�R�[�_�́A�^�[�{������LDPC�Ƃ������ŋ߂̕������_�̐��ʂ̃G�b�Z���X�ɔ�����̂ł��B
���̂悤�ɁA��M�l�̃A�i���O�l���g���Ē����m�������コ�����������iSoft Decision)�ƌĂ�ł��܂��B
�P.����
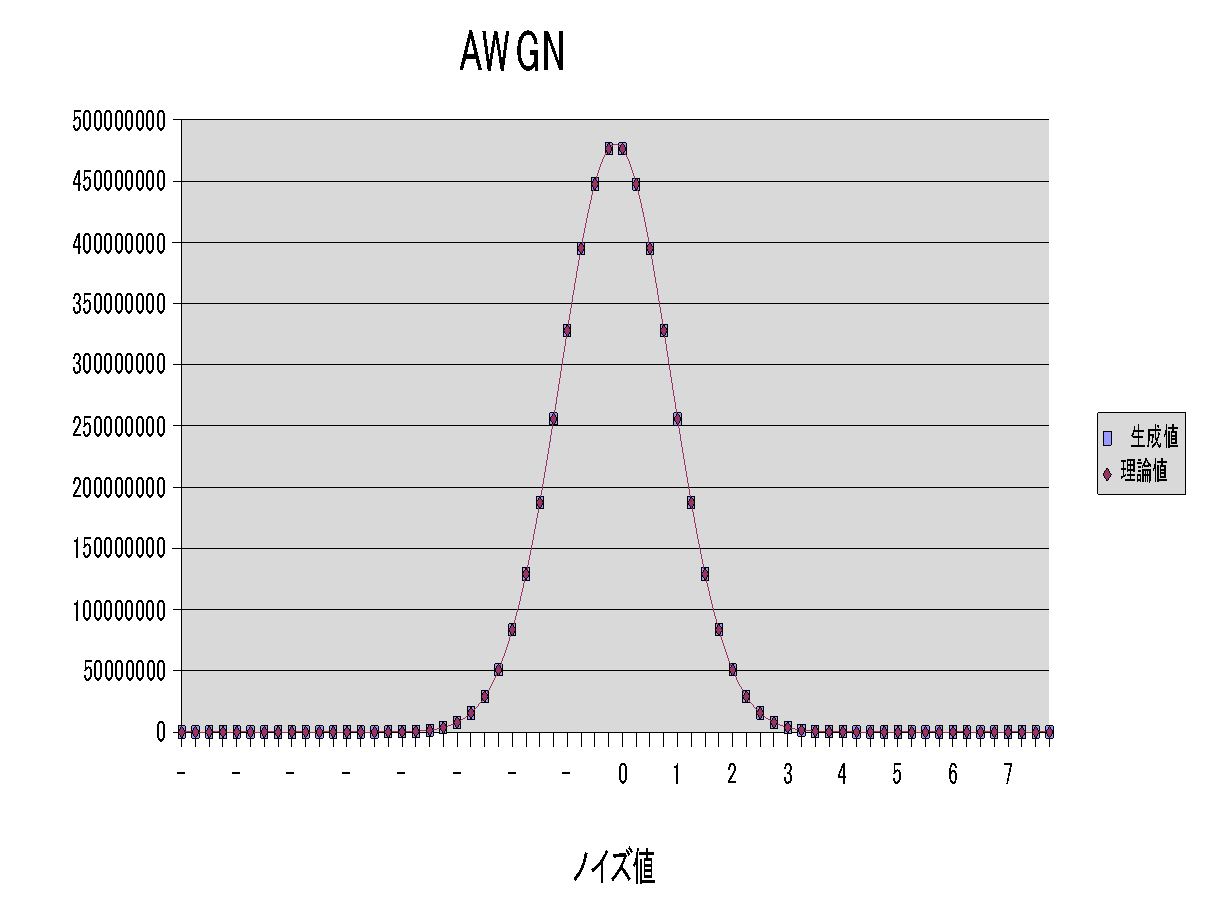
�V�X�e���̃V�~�����[�V������Verilog�@HDL�ōs�����Ƃ����AWG�iadditive white Gaussian )�@Noise������K�v������܂��BVerilog�@2001�ł́A
$dist_normal���ŁAAWGN���ł���̂ł����A�c�O�Ȃ��ƂɎd�l��A���́E�o�̓p�����[�^���Ainteger�ɂȂ��Ă��āA�ʎq���덷��
�܂Ȃ��Ƃ���œ����Ă��܂��܂��B�i�ǂ����āA���̂悤�Ȏd�l�ɂȂ������S���Ӗ��s���ł��B�j�@���z�l�Ƃ̔�r�������ł��A�ŏ���
�����́A�ʎq���덷�̓���Ȃ�real�i������ł�double)���x�ŊȒP�ɍs�������ł��ˁB�����ŁAVeritak�ł́Areal�ł�$normal_vtak��VPI�ō쐬���Ă݂܂����B(1.83����r���g�C�����Ă��܂��B�j
����ŁAC�ŏ����Ȃ��Ƃ��A�ŏI��Hard��H�̌��܂ŁAVerilog�@HDL��Ŏ��R�ɋL�q���邱�Ƃ��ł��܂��B
�P�D�P�@$dist_normal�̎g����
�T���v���ł��B
//Oct.11.2005
//random_sn.v
module random_sn;
parameter integer No=10;
real sd,mean;
real a;
integer seed1;
integer i;
real sdf_array[0:No-1] ;
real sum,avg,sd2;
real expected_mean=-10;
real expected_sd=2.0;
integer result;
initial begin
#10;
seed1=0;
sum=0;
for (i=0;i<No;i=i+1) begin
`ifdef Veritak
a=$normal_vtak(seed1,expected_mean,expected_sd);
`else
result=$dist_normal(seed1,$rtoi(expected_mean),$rtoi(expected_sd));
a=$itor(result);
`endif
sdf_array[i]=a;
sum=sum+a;
$display(" a=%f seed=%d",a,seed1);
end
avg=sum/No;
sum=0;
for (i=0;i<No;i=i+1) begin
a=sdf_array[i]-avg;
sum=sum+a*a;
end
sd2=sum/No;
`ifdef Veritak
sd=$sqrt(sd2);
$display("Total %d ",No);
$display("Expected Avg=%f SD=%f ",expected_mean,expected_sd);
$display("Results Avg=%f SD=%f SD2=%f",avg,sd,sd2);
$display("Difference Avg=%f SD=%f",$fabs(expected_mean-avg),$fabs(expected_sd-sd));
`else
$display("Total %d ",No);
$display("Expected Avg=%f SD2=%f ",expected_mean,expected_sd*expected_sd);
$display("Results Avg=%f SD2=%f",avg,sd2);
`endif
end
endmodule
Veritak�̎��s���ʂł��B���̃v���O�����ł́A���ρimean�j=-10.0, �W����=2.0�_���Ő������Ă��܂��B
F:\regression_test\complex\random_sn.v(3)::random_sn
Verilog�̃V�~�����[�V�����̏������������܂����B�X�^�[�g��,Go�{�^���������Ă��������B
------------- �V�~�����[�V�������J�n���܂��B--------------------
a=-9.107809 seed= 1082744015
a=-9.710610 seed= -958425333
a=-9.057617 seed=-2032678137
a=-7.126455 seed=-1634874387
a=-12.131116 seed= 1427361855
a=-9.270853 seed= 1735824513
a=-11.797993 seed= 1657425015
a=-7.087418 seed= 1586374365
a=-12.799056 seed=-2056026887
a=-13.158670 seed=-1872486481
Total 10
Expected Avg=-10.000000 SD=2.000000
Results Avg=-10.124760 SD=2.108805 SD2=4.447058
Difference Avg=0.124760 SD=0.108805
ModelSim�̎��s���ʂł��B
# Loading work.random_sn run -all # a=-9.000000 seed= 1082744015 # a=-10.000000 seed= -958425333 # a=-9.000000 seed=-2032678137 # a=-7.000000 seed=-1634874387 # a=-12.000000 seed= 1427361855 # a=-9.000000 seed= 1735824513 # a=-12.000000 seed= 1657425015 # a=-7.000000 seed= 1586374365 # a=-13.000000 seed=-2056026887 # a=-13.000000 seed=-1872486481 # Total 10 # Expected Avg=-10.000000 SD2=4.000000 # Results Avg=-10.100000 SD2=4.690000seed �́Arandom�̎�A�ł��ꂪrandom��SEQ�����߂Ă��܂��BVerilog�@2001�ł́A�����݊��Ȃ̂ŁA����seed��^����A
�V�~�����[�^�Ɉˑ������A��������SEQ�ɂȂ�܂��B$dist_normal���ĂԂƁAseed&�ŌĂ݂����Ɏ��̂�eed�l���Ԃ��Ă��܂��B
����Ăяo���ł́A���̕Ԃ��Ă����l�ŌĂԂ��ƂŁAAWGN�ɂȂ�܂��B$dist_normal�ł́A�����ŕԂ��Ă��Ă��܂��_��SD����̌덷��
�傫���Ȃ��Ă��܂��܂��B
�����ŁA����ȍ~�́AVeritak�Ǝ��V�X�e���^�X�N���g�����Ƃɂ��܂��B
�����A�T�[�x�C���Ă݂܂����B�ۑ�́A���������p���e�B�R�[�h��Sum-Product�A���S���Y���ʼn����Ă��܂��B�p���e�B���������Ⴄ�̂�
LDPC�ł͂���܂������@�́ALDPC���̂��̂ł��B
�Ƃ肠�����A�d����ł�1�r�b�g�̌������͂ł��܂��BHamming�@Code�́A������7�r�b�g�ŁA1�r�b�g�����ł��܂�����A���ꂾ��������ƁA
�����͂悭����܂���BBP�iBelief�@Propagation�j�����@���^��������̂́A���̂悤�ȒZ���������ł͂Ȃ�
������x�����������ł��B�������A����̕����́ALDGM�Ƃ����p���e�B�̍����ɂȂ��Ă��āALDPC�ɔ�ׂē��������m���Ă��܂��B
�d����̃X�g���e�W�̌���
���\�ŁAy0-y3���f�[�^�Aro-r1���A�s�p���e�B�Ac0-c1����p���e�B�ŁAy0-y3-r0-r1-c0-c1�̏��ő���܂��B
| y0 | y1 | r0 |
| y2 | y3 | r1 |
| c0 | c1 |
�@�P���Ƀp���e�B�}�g���N�X�����ɏ��������ƁA
�@y0+y1 +r0 =0 -(1)
y2+y3+ r1 =0 -(2)
y0+ y2+ +c0 =0 -(3)
y1+ y3 +c1=0 -(4)
�ɂȂ�܂��B�@�����ŁA������G���[�����������Ɖ��肵�܂��B
���p���e�B�r�b�g�ɔ��������ꍇ��
�@���̏ꍇ�́A�e�o���e�B�́A(1)-(4)�܂ŁA�Ɨ��������ɂȂ��Ă��܂��B���������āA(1)-(4)�܂ł̂ǂꂩ�A�ꎮ�������A�������Ȃ��P�[�X�́A
�p���e�B�r�b�g�̃G���[�ƍl���邱�Ƃ��ł��A�f�[�^�r�b�g�iy0-y3)�̒����͕K�v����܂���B
���f�[�^�r�b�g��1�̃f�[�^�G���[�����������ꍇ��
�@����y0�ɃG���[��e0���������Ƃ��܂��B��������ƁA�������Ȃ��̂́A(1)�A(3)�����ɂȂ�܂��B
���l�ɂ��Ĉȉ��̂悤�ɂ܂Ƃ߂邱�Ƃ��ł��܂��B
| 1�̃G���[ | �p���e�B�G���[�ƂȂ鎮 | ���� |
| y0 | (1),(3) | y0^=1; |
| ���P | (1),(4) | y1^=1; |
| y2 | (2),(3) | y2^=1; |
| y3 | (2),(4) | y3^=1; |
| r0 | (1) | �K�v�Ȃ� |
| r1 | (2) | �K�v�Ȃ� |
| c0 | (3) | �K�v�Ȃ� |
| c1 | (4) | �K�v�Ȃ� |
2�G���[�����������ꍇ�́A�ǂ��ł��傤���H�P���ɂ́A�s���Ȃ��ł��ˁB���Ƃ��Ay0,y1�ɃG���[�����������ƂƁAc0,c1�ɃG���[�����������Ƃ�
��ʂł��܂���B�G���[�����������Ƃ́A���o�ł������ł����A�����܂ł́A�ł��܂���B����ɁA�R�G���[����ƁA1�̃G���[�Ƌ�ʂł��Ȃ��Ȃ�A
������̉\��������܂��B4�G���[�����Ƃ���ƁA�G���[�����������Ƃ��猟�o�ł��Ȃ�\��������܂��B
�i��ʂɁA�����ƌ�����́A�m���̈Ⴂ�ł�������܂���B��������V�X�e���́A�K��������m���ɂ��čl�@����K�v������܂��B�j
���̃f�[�^�́A4�r�b�g�ł�����A�����̎�ނ́A���X16��������܂���B�������p���e�B��������8�r�b�g���Ȃ킿256��ނ�
Data��M�̉\��������܂��B��M�����A256��ނ̃f�[�^�i�A�i���O�ōl����Ɩ����ɂ���܂����j�́A���̂P6��
�ǂ�Ɉ�ԋ߂��ł��傤���H�Ƃ������ł��B�@��ԋ߂��f�[�^������A�ł��G���[�m�����������ł���悤�ȋC�����܂��ˁB
�ł́A��ԋ߂��Ƃ������Ƃ��ǂ��\���ł���ł��傤���H���ꂪ�����Ƃ����T�O�ł��B
�n�~���O�����ƃ��[�N���b�h����
����̉ۑ�ł́ALDGM��BP�Ƃ����̑��Ƀ��[�N���b�h�������r���铚�Ă����邾�낤�Ǝv���܂��B
����ł́A�n�~���O�����ɂ��Č��Ă����܂��傤�B
���̃v���O�����ł́A�����̑S���[�h���o�͂��Ă��܂��B
//�ۑ�̕�����S������
//Brute Force�ɍŏ������ׂ�
module dwm1_test;
reg [3:0] data;//Encode���錳Data��WORK
reg [7:0] code_array[0:15];//�S�R�[�h���[�h���i�[����
reg [7:0] work,a,b,c,d;
wire [7:0] encoded_data;//encoder ����̏o�͂����
integer i,j,flag,m,k,n;
encoder en1(data,encoded_data);
initial begin
//�����̗�
for (i=0;i<16;i=i+1) begin//
data=i[3:0];
#10;
code_array[i]=encoded_data;//�z��Ɋi�[
$display("Code [%d]=%b",i,encoded_data);
end
//CODE�@Word�̃r�b�g�̔C�ӂP�r�b�g��ω������ĕʕ�����Ɉ�v���邩������B
flag=0;
$display("1�r�b�g�G���[���`�F�b�N���Ă��܂��B");
for (i=0;i<16;i=i+1) begin//
work=code_array[i];//����Data��
for ( j=0;j<8;j=j+1) begin
a=work ^ (1 <<j);//1bit�@�G���[���悹��
for (m=0; m<16;m=m+1) begin//���������ꂪ���邩�ǂ������`�F�b�N
if (a==code_array[m]) flag=1;//���������ꂪ����������@�t���OON
end
end
end
if (!flag) $display( "1�r�b�g�G���[�ŁA���̕�����ɂȂ邱�Ƃ͂���܂���ł����B�ŏ������́A�P���傫���ł��B\n");
//CODE�@Word�̃r�b�g�̔C�ӂQ�r�b�g��ω������ĕʕ����Ɉ�v���邩������B
flag=0;
$display("2�r�b�g�G���[���`�F�b�N���Ă��܂��B");
for (i=0;i<16;i=i+1) begin//
work=code_array[i];//����Data��
for ( j=0;j<8;j=j+1) begin
a=work ^ (1 <<j);//1bit�@�G���[���悹��
for (k=0;k<8;k=k+1) begin
b=a ^(1<< k);//����1�r�b�g�G���[���悹��
if (work !=b) begin//���������͏�����
for (m=0; m<16;m=m+1) begin//���������ꂪ���邩�ǂ������`�F�b�N
if (b==code_array[m]) flag=1;//���������ꂪ����������@�t���OON
end
end
end
end
end
if (!flag) $display( "2�r�b�g�G���[�ŁA���̕�����ɂȂ邱�Ƃ͂���܂���ł����B�ŏ������́A2���傫���ł��B\n");
//CODE�@Word�̃r�b�g�̔C��3�r�b�g��ω������ĕʕ����Ɉ�v���邩������B
flag=0;
$display("3�r�b�g�G���[���`�F�b�N���Ă��܂��B");
for (i=0;i<16;i=i+1) begin//
work=code_array[i];//����Data��
for ( j=0;j<8;j=j+1) begin
a=work ^ (1 <<j);//1bit�@�G���[���悹��
for (k=0;k<8;k=k+1) begin
b=a ^(1<< k);//����1�r�b�g�G���[���悹��
for (n=0;n<8;n=n+1) begin
c=b^(1<<n);//����1�r�b�g�G���[���悹
if (work !=c) begin//����������͏�����
for (m=0; m<16;m=m+1) begin
if (c==code_array[m]) begin//���������ꂪ���邩�ǂ������`�F�b�N
//$display("%b %b",work,c);
flag=1;//���������ꂪ����������@�t���OON
end
end
end
end
end
end
end
if (!flag) $display( "3�r�b�g�G���[�ŁA���̕�����ɂȂ邱�Ƃ͂���܂���ł����B�ŏ������́A2���傫���ł��B");
else $display("3�r�b�g�G���[�ŁA���̕�����ɂȂ邱�Ƃ�����܂��B�ŏ������́A3�ȉ��ł��B");
end
endmodule
module encoder(input [3:0] in,
output wire [7:0] out);
reg r0,r1,c0,c1;
wire [3:0] y=in[3:0];
assign out[3:0]=in;
assign out[4]=r0;
assign out[5]=r1;
assign out[6]=c0;
assign out[7]=c1;
always @* begin
r0=y[0] ^ y[1];
r1=y[2] ^ y[3];
c0=y[0] ^ y[2];
c1=y[1] ^ y[3];
end
endmodule
���̌��ʂ�����ƁA���̂悤�ɂȂ�܂��B�R�[�h���[�h�O�ƂP�̃n�~���O�����́A3�ɂȂ�܂��B�n�~���O�����Ƃ͂O��1���Ⴄ�Ƃ���̐��ł��B�S�Ă̕�����ł݂��Ƃ��ɁA
�ŏ��ƂȂ�n�~���O�������ŏ������ɂȂ�܂��B�v���O�����ł́A�����f���ɑS���[�h�ɂ��Ď����čŏ����������߂Ă��āA
�^�̍ŏ������́A�R�ł��邱�Ƃ��Ă��܂��B
���̕�����ɉ�����ɂ́A3�r�b�g�̃G���[���K�v�ł��B�����̗��ꂩ�猩��ƁA1�r�b�g�̃G���[�ɂ��ẮA�ǂ���ɋ߂���
�d����ł��e�Ղɔ��f�ł��A2�r�b�g�G���[�ł́A������̉\��������A3�r�b�g�ł́A���̕�����ɉ����Ă��܂��ăG���[�����������Ƃ���A
������Ȃ��A�Ƃ������ƂɂȂ�܂��B�ȏ�́A�ŏ������Ō����ꍇ�ŁA�S�Ă̕����Ԃ̋������R�Ƃ�����ł��Ȃ������Ȃ̂ŁA
���ł́A2�r�b�g�������\�ȏ�ʂ��łĂ��邱�Ƃ����҂ł��邩������Ȃ��Ƃ������Ƃł͂Ȃ����Ǝv���܂��B
�f�W�^���I�Ɍ����̂��A�n�~���O�����ł����A������A�i���O�I�Ɍ����̂����[�N���b�h�����ɂȂ�܂��B����̂悤��AWGN�̌n�ɂ����ẮA��M���[�h�ɂ��āA
�S������Ƃ̃��[�N���b�h���������ߍŏ��ƂȂ镄�����I�яo���A�ł��m���炵�������iMaximum�@likelihood�@Decoding)�ƂȂ邱�Ƃ��m���Ă��܂��B
����̏ꍇ�A�ɒ[�ɕ��������Z���̂ŁA���͂�����ɂ��邩������܂���B
F:\regression_test\ldgm\dwm_test1.v(3)::dwm1_test
Verilog�̃V�~�����[�V�����̏������������܂����B�X�^�[�g��,Go�{�^���������Ă��������B
------------- �V�~�����[�V�������J�n���܂��B--------------------
Code [ 0]=00000000
Code [ 1]=01010001
Code [ 2]=10010010
Code [ 3]=11000011
Code [ 4]=01100100
Code [ 5]=00110101
Code [ 6]=11110110
Code [ 7]=10100111
Code [ 8]=10101000
Code [ 9]=11111001
Code [ 10]=00111010
Code [ 11]=01101011
Code [ 12]=11001100
Code [ 13]=10011101
Code [ 14]=01011110
Code [ 15]=00001111
1�r�b�g�G���[���`�F�b�N���Ă��܂��B
1�r�b�g�G���[�ŁA���̕�����ɂȂ邱�Ƃ͂���܂���ł����B�ŏ������́A�P���傫���ł��B
2�r�b�g�G���[���`�F�b�N���Ă��܂��B
2�r�b�g�G���[�ŁA���̕�����ɂȂ邱�Ƃ͂���܂���ł����B�ŏ������́A2���傫���ł��B
3�r�b�g�G���[���`�F�b�N���Ă��܂��B
3�r�b�g�G���[�ŁA���̕�����ɂȂ邱�Ƃ�����܂��B�ŏ������́A3�ȉ��ł��B
---------- �V�~�����[�V�������I�����܂��Btime=160----------
�ۑ�̎��g�ݕ��j
�R���e�X�g�̎��g�ݕ��j�́A��̌����Ō��܂�܂����B���肸�ɂ܂��A�Q�킵�Ă݂����Ǝv���܂��B�_���́A
- �X���[�v�b�g�@4Gbps�@�iIterative Decoder�͎g��Ȃ��Ǝ������j
- AWGN�����퓋��->1e8�r�b�g�ł�BER�������i�X�^�[�^�L�b�g�R�j
�ۑ�����������A6�Ђ܂őς���AWGN��IP������������ł��B�@
�n�[�h�Ŕ���������ƂȂ�ƁABox�@Muller�AZiggurat�AWallace�̕��@�̂�����������Ă��Ă������������Z�����邱�ƂɂȂ�̂ŁA
�ʓ|�ł��B����́AYACC�ɁAziggurat�̕��@���\�t�g�Ŏ������邱�Ƃɂ��܂����B�iYACC�̍������Q�Ƃ��������B�j
on the fly �ł́A����܂��A�����I��AWGN���ł���̂ŁA��x���点��A��̓Ԏ��敪�z�܂ŁA�v���O�����Ō����邱�Ƃ��\�ɂȂ�܂��B
BPSK�̐��G���[���[�g��1�r�b�g������H
���G���[���[�g�ɑ��āA��̍d���������H�̌��ʂ����Ă݂܂��傤�B
�ۑ�ʂ�A�O��B,3dB,6dB,9dB���܂�AWGN�������A���G���[���[�g�ɑ����r���s���Ă݂܂��B
//Nov.2.2005
//Nov.3.2005
module raw_error_rate;
parameter integer RATE=2;
parameter integer No_Of_Data_Bits=10000;
parameter integer No_Of_Array=No_Of_Data_Bits/4;
parameter integer Total_Bits=No_Of_Data_Bits*RATE;
parameter integer SEED=1;
real expected_sigma;
real noise;
real noise_array[ 0 :Total_Bits-1];
real r_array [0 :Total_Bits-1];
reg [7:0] data_array [0 : No_Of_Array-1];
reg [7:0] decode_array [0 : No_Of_Array-1];
reg [3:0] hard_correction_array [0 : No_Of_Array-1];
initial begin
make_random_data;//10000�̃����_���f�[�^����� ���ʂ�=>data_array�@LSB��4bit
encode_data;//10000�̃p�C�e�B������@���ʂ�=>data_array�@MSB��4bit
add_noise(0.0);//�O��B�m�C�Y��������
raw_decode;//�f�R�[�h����
hard_correction;
add_noise(3.0);//3��B�m�C�Y��������
raw_decode;//�f�R�[�h����
hard_correction;
add_noise(5.0);//5��B�m�C�Y��������
raw_decode;//�f�R�[�h����
hard_correction;
add_noise(6.0);//6��B�m�C�Y��������
raw_decode;//�f�R�[�h����
hard_correction;
add_noise(7.0);//7��B�m�C�Y��������
raw_decode;//�f�R�[�h����
hard_correction;
add_noise(8.0);//8.0��B�m�C�Y��������
raw_decode;//�f�R�[�h����
hard_correction;
add_noise(9.0);//9.0��B�m�C�Y��������
raw_decode;//�f�R�[�h����
hard_correction;
add_noise(10.0);//10.0��B�m�C�Y��������
raw_decode;//�f�R�[�h����
hard_correction;
end
task make_random_data;
integer i;
integer work,counter;
begin
$display("%d�̃����_���f�[�^�����ł��B",No_Of_Data_Bits);
for (i=0;i<No_Of_Array-8; i=i+8) begin//4x8 �r�b�g�����_���f�[�^��
work=$random;
{data_array[i+3][0 +:4],data_array[i+2][ 0 +:4],data_array[i+1][0 +:4],data_array[i+0][0 +:4]}=work[15:0];
{data_array[i+7][0 +:4],data_array[i+6][ 0 +:4],data_array[i+5][0 +:4],data_array[i+4][0 +:4]}=work[31:16];
end
work=$random;
counter=0;
for (i=No_Of_Array-8;i<No_Of_Array; i=i+1) begin//�Ō�́A4�r�b�g�Â�
data_array[i][0 +:4]=work[counter*4 +:4];
counter=counter+1;
end
end
endtask
task encode_data;
integer i;
begin
$display("�p���e�B�����ł��B");
if ( (Total_Bits/RATE)% No_Of_Array)begin//assert(0);
$display(" �v���O�����G���[");
$finish;
end
for (i=0;i<No_Of_Array; i=i+1) begin
data_array[i][4 +:4]=encoder(data_array[i][ 0 +:4]);//�f�[�^��n���ăp���e�B�����
// $display("data=%h parity=%h",data_array[i][0 +:4],data_array[i][4 +:4]);
end
end
endtask
function [3:0] encoder (input [3:0] y);//�p���e�B������
reg r0,r1,c0,c1;
begin
r0=y[0] ^ y[1];
r1=y[2] ^ y[3];
c0=y[0] ^ y[2];
c1=y[1] ^ y[3];
encoder ={c1,c0,r1,r0};
end
endfunction
task make_noise( input real db);//���]��S/N[dB]�����
real sigma2,sigma;
integer seed,i;
real noise;
real noise_sum;
begin
$display("-------------------------------------------------");
$display("�m�C�Y�p���[�@%f[dB] �_���Ő������ł��B",db);
sigma2=$pow(10.0,-db/10.0);//$pow �́AVeritak�@Unique
sigma=$sqrt(sigma2);//$sqrt �́AVeritak�@Unique
seed=0;
noise_sum=0;
for (i=0;i<Total_Bits;i=i+1) begin
noise=$normal_vtak(seed,0.0,sigma);//$normal_vtak�́AVeritak�@Unique�@���ϒl�O�A�Ђ�AWGN��
noise_array[i]=noise;//�m�C�Y�z��Ɏ��[����
noise_sum=noise_sum+noise*noise;
end
$display("�m�C�Y�p���[�@%f[dB]�̐��������܂����B",-10*$log10(noise_sum/Total_Bits));
end
endtask
task add_noise( input real db);//���]��S/N[dB]�����
real sigma2,sigma;
integer counter,i,j;
real noise,RData;
begin
make_noise(db);//���]��S/N�@Noize ��noise_array �Ɏ��[����
$display("�m�C�Y�����Z���ł��B");
counter=0;
for (i=0;i<No_Of_Array; i=i+1) begin
for (j=0;j<8;j=j+1) begin
if (data_array[i][j]==1'b1) RData=$itor(-1);//�f�[�^�P�����|�P.0�ɃG���R�[�h
else RData=$itor(1);//�f�[�^�O�����P.0�ɃG���R�[�h
RData=RData+noise_array[counter];//�v�Z��������AWGN�m�C�Y�����Z����
r_array[counter]=RData;//r_array �Ƀm�C�Y���d��real data ��Save����B
counter=counter+1;
end
end
if ( counter !=Total_Bits) begin//assert(0);
$display(" �v���O�����G���[");
$finish;
end
end
endtask
task raw_decode();
integer i,j;
integer index;
integer error_count;
begin
error_count=0;
index=0;
for (i=0;i<Total_Bits;i=i+8) begin
for (j=0;j<8;j=j+1) begin
if (r_array[i+j]>0) decode_array[index][j]=0;//�p���e�B���܂߃n�[�h�f�R�[�h����
else decode_array[index][j]=1;
if (j<4) begin//�f�[�^���̓r�b�g�G���[���J�E���g����
if (decode_array[index][j] !=data_array[index][j]) error_count=error_count+1;
end
end
index=index+1;
end
$display("�����Ȃ��V�X�e������");
$display("�g�[�^���G���[����%d �G���[���[�g=%e",error_count, $itor(error_count)/No_Of_Data_Bits);
end
endtask
task hard_correction();
reg p0,p1,p2,p3;
reg [3:0] parities;
reg d0,d1,d2,d3;
integer index,error_count,i;
begin
error_count=0;
for (index=0;index<No_Of_Array; index=index+1) begin
{d3,d2,d1,d0}=decode_array[index][3:0];//work
p0=d0 ^ d1 ^ decode_array[index][4];//�p���e�B���v�Z
p1=d2 ^ d3 ^ decode_array[index][5];//�p���e�B���v�Z
p2=d0 ^ d2 ^ decode_array[index][6];//�p���e�B���v�Z
p3=d1 ^ d3 ^ decode_array[index][7];//�p���e�B���v�Z
parities={p3,p2,p1,p0};
hard_correction_array[index][3:0]={d3,d2,d1,d0};
if (parities==4'b0000);//No Error Nothing to Do
else if (parities==4'b0101) hard_correction_array[index][3:0]={d3,d2,d1,~d0};//1bit ����
else if (parities==4'b1001) hard_correction_array[index][3:0]={d3,d2,~d1,d0};//1bit ����
else if (parities==4'b0110) hard_correction_array[index][3:0]={d3,~d2,d1,d0};//1bit ����
else if (parities==4'b1010) hard_correction_array[index][3:0]={~d3,d2,d1,d0};//1bit ����
else ;//parity error or uncorrectable error.
//�G���[�����J�E���g
if (data_array[index][3:0] !=hard_correction_array[index][3:0]) begin//���[�h��r����
for (i=0;i<4;i=i+1) begin//���������G���[�����J�E���g
if (data_array[index][i] !=hard_correction_array[index][i]) error_count=error_count+1;
end
end
end
$display("�n�[�h������H����");
$display("�g�[�^���G���[����%d �G���[���[�g=%e",error_count, $itor(error_count)/No_Of_Data_Bits);
$display("\n");
end
endtask
endmodule
���s���ʂł��B�Ȃ��ABPSK��BER���_�l�́A| S/N | BER |
| �T��B | 3.75e-2 |
| �U��B | 2.29e-2 |
| �V��B | 1.25e-2 |
| �W��B | 5.95e-3 |
| �X��B | 2.39e-3 |
���āA�����̌��ʂ́A�ǂ��ł��傤���H�O���t�ɂ��Ă݂Ȃ��Ɨǂ��킩��܂��ABER�͊m���ɉ������Ă���̂ŁA���ʂ͂����
������ł��傤�B���́A�����Maximum�@Likelihood�@Decoding�����ꍇ�ǂ��Ȃ邩�H�A�ł��B
F:\regression_test\ldgm\raw_error_rate.v(2)::raw_error_rate
Verilog�̃V�~�����[�V�����̏������������܂����B�X�^�[�g��,Go�{�^���������Ă��������B
------------- �V�~�����[�V�������J�n���܂��B--------------------
10000�̃����_���f�[�^�����ł��B
�p���e�B�����ł��B
-------------------------------------------------
�m�C�Y�p���[�@0.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@0.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 1607 �G���[���[�g=1.607000e-001
�n�[�h������H����
�g�[�^���G���[���� 1280 �G���[���[�g=1.280000e-001
-------------------------------------------------
�m�C�Y�p���[�@3.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@3.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 810 �G���[���[�g=8.100000e-002
�n�[�h������H����
�g�[�^���G���[���� 402 �G���[���[�g=4.020000e-002
-------------------------------------------------
�m�C�Y�p���[�@5.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@5.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 393 �G���[���[�g=3.930000e-002
�n�[�h������H����
�g�[�^���G���[���� 104 �G���[���[�g=1.040000e-002
-------------------------------------------------
�m�C�Y�p���[�@6.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@6.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 238 �G���[���[�g=2.380000e-002
�n�[�h������H����
�g�[�^���G���[���� 41 �G���[���[�g=4.100000e-003
-------------------------------------------------
�m�C�Y�p���[�@7.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@7.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 110 �G���[���[�g=1.100000e-002
�n�[�h������H����
�g�[�^���G���[���� 12 �G���[���[�g=1.200000e-003
-------------------------------------------------
�m�C�Y�p���[�@8.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@8.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 52 �G���[���[�g=5.200000e-003
�n�[�h������H����
�g�[�^���G���[���� 2 �G���[���[�g=2.000000e-004
-------------------------------------------------
�m�C�Y�p���[�@9.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@9.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 23 �G���[���[�g=2.300000e-003
�n�[�h������H����
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
-------------------------------------------------
�m�C�Y�p���[�@10.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@10.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 8 �G���[���[�g=8.000000e-004
�n�[�h������H����
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
---------- �V�~�����[�V�������I�����܂��Btime=0----------
���[�N���b�h�����ɂ�镜���ł��B���hard_correction�^�X�N�ɑΉ����Ă��܂��B
task euclidean_decode();
integer i,j,k,m;
integer index;
integer error_count;
reg [3:0] min_code_word;
reg [7:0] data;
real distance,min_distance;
real bit_distance;
real data_r;
begin
error_count=0;
index=0;
for (i=0;i<Total_Bits;i=i+8) begin
//�����̗�
min_distance=1e5;//Big Value
for (j=0;j<16;j=j+1) begin//�S�R�[�h���[�h�ɂ���
data={encoder(j[3:0]),j[3:0]};//�����̗�
//$display("Code [%d]=%b",j,data);
distance=0.0;
for (k=0;k<8;k=k+1) begin//���[�N���b�h�����ׂ�
data_r=data[k]==1'b1 ? -1.0 : 1.0;//�G���R�[�h
bit_distance=r_array[i+k]- data_r;//�r�b�g���̋���
distance=distance+ bit_distance**2;//�Q�悵�đ���
end
if (distance <min_distance) begin//�������ŏ����H ��r�����Ȃ̂Ń��[�g�͕s�v
min_distance=distance;//������Save
min_code_word=j[3:0];//�R�[�h���[�h���o������
end
end
euclidean_correction_array[index]=min_code_word;
if (min_code_word !==data_array[index][3:0]) begin//�R�[�h���[�h���r����
for (m=0;m<4;m=m+1) begin//���������r�b�g�G���[�����J�E���g
if (data_array[index][m] !=euclidean_correction_array[index][m]) error_count=error_count+1;
end
end
index=index+1;
end
$display("ML�V�X�e������");
$display("�g�[�^���G���[����%d �G���[���[�g=%e",error_count, $itor(error_count)/No_Of_Data_Bits);
end
endtask
���s���ʂł��B�m���ɏ�̍d���������H�����G���[���[�g�����サ�Ă��܂��B���̌��ʂ́A���̕����������̏�E��^���܂��B
�i������ǂ����ʂ͂���܂���B�j�@�R���e�X�g�ł́A�����ɂ��̌��ʂɁA�������ŏ��Q�[�g���ŋ߂Â��邩�A���L�[�|�C���g�ɂȂ�܂��B
F:\regression_test\ldgm\Euclidean_error_rate.v(3)::euclidean_error_rate
Verilog�̃V�~�����[�V�����̏������������܂����B�X�^�[�g��,Go�{�^���������Ă��������B
------------- �V�~�����[�V�������J�n���܂��B--------------------
10000�̃����_���f�[�^�����ł��B
�p���e�B�����ł��B
-------------------------------------------------
�m�C�Y�p���[�@0.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@0.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 1607 �G���[���[�g=1.607000e-001
�n�[�h������H����
�g�[�^���G���[���� 1280 �G���[���[�g=1.280000e-001
ML�V�X�e������
�g�[�^���G���[���� 755 �G���[���[�g=7.550000e-002
-------------------------------------------------
�m�C�Y�p���[�@3.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@3.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 810 �G���[���[�g=8.100000e-002
�n�[�h������H����
�g�[�^���G���[���� 402 �G���[���[�g=4.020000e-002
ML�V�X�e������
�g�[�^���G���[���� 128 �G���[���[�g=1.280000e-002
-------------------------------------------------
�m�C�Y�p���[�@5.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@5.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 393 �G���[���[�g=3.930000e-002
�n�[�h������H����
�g�[�^���G���[���� 104 �G���[���[�g=1.040000e-002
ML�V�X�e������
�g�[�^���G���[���� 13 �G���[���[�g=1.300000e-003
-------------------------------------------------
�m�C�Y�p���[�@6.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@6.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 238 �G���[���[�g=2.380000e-002
�n�[�h������H����
�g�[�^���G���[���� 41 �G���[���[�g=4.100000e-003
ML�V�X�e������
�g�[�^���G���[���� 4 �G���[���[�g=4.000000e-004
-------------------------------------------------
�m�C�Y�p���[�@7.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@7.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 110 �G���[���[�g=1.100000e-002
�n�[�h������H����
�g�[�^���G���[���� 12 �G���[���[�g=1.200000e-003
ML�V�X�e������
�g�[�^���G���[���� 3 �G���[���[�g=3.000000e-004
-------------------------------------------------
�m�C�Y�p���[�@8.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@8.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 52 �G���[���[�g=5.200000e-003
�n�[�h������H����
�g�[�^���G���[���� 2 �G���[���[�g=2.000000e-004
ML�V�X�e������
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
-------------------------------------------------
�m�C�Y�p���[�@9.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@9.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 23 �G���[���[�g=2.300000e-003
�n�[�h������H����
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
ML�V�X�e������
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
-------------------------------------------------
�m�C�Y�p���[�@10.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@10.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 8 �G���[���[�g=8.000000e-004
�n�[�h������H����
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
ML�V�X�e������
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
---------- �V�~�����[�V�������I�����܂��Btime=0----------
���āA���ɉۑ�̕��@�ł����ʂ��r���Ă����܂��傤�B�f���ɁA�Ꭶ�̕��@���R�[�f�B���O���܂��B
task iterative_decoder(input integer iteration,input integer min_sum_flag);//min_sum ��p����ꍇ�́Amin_sum=1�Ƃ���
integer i,j,m;
integer index;
integer iter;
integer error_count;
real y0,y1,y2,y3,r0,r1,c0,c1;
real y0col,y1col,y2col,y3col;
real y0row,y1row,y2row,y3row;
reg d0,d1,d2,d3;
begin
error_count=0;
index=0;
for (i=0;i<Total_Bits;i=i+8) begin
//iterative decoder �̏�����
y0=r_array[i+0];
y1=r_array[i+1];
y2=r_array[i+2];
y3=r_array[i+3];
r0=r_array[i+4];
r1=r_array[i+5];
c0=r_array[i+6];
c1=r_array[i+7];
y0col=0.0;
y1col=0.0;
y2col=0.0;
y3col=0.0;
for (iter=0;iter< iteration;iter=iter+1) begin//interative �f�R�[�f�B���O
//�s�A�O���l�̌v�Z
y0row=func(y1+y1col,r0,min_sum_flag);
y1row=func(y0+y0col,r0,min_sum_flag);
y2row=func(y3+y3col,r1,min_sum_flag);
y3row=func(y2+y2col,r1,min_sum_flag);
//��A�O���l�̌v�Z
y0col=func(y2+y2row,c0,min_sum_flag);
y1col=func(y3+y3row,c1,min_sum_flag);
y2col=func(y0+y0row,c0,min_sum_flag);
y3col=func(y1+y1row,c1,min_sum_flag);
end
//�J��Ԃ����I�������f�R�[�h���`���l���l�{���O�l�{����l
d0=y0+y0row+y0col > 0 ? 0 :1;
d1=y1+y1row+y1col > 0 ? 0: 1;
d2=y2+y2row+y2col > 0 ? 0: 1;
d3=y3+y3row+y3col > 0 ? 0: 1;
iterative_correction_array[index]={d3,d2,d1,d0};
if (iterative_correction_array[index] !==data_array[index][3:0]) begin//�R�[�h���[�h���r����
for (m=0;m<4;m=m+1) begin//���������r�b�g�G���[�����J�E���g
if (data_array[index][m] !=iterative_correction_array[index][m]) error_count=error_count+1;
end
end
index=index+1;
end
if (min_sum_flag) $display("Min-Sum Iterative Decoding Log�V�X�e������ ");
else $display("Log-Sum Iterative Decoding Log�V�X�e������ ");
$display("�g�[�^���G���[����%d �G���[���[�g=%e",error_count, $itor(error_count)/No_Of_Data_Bits);
end
endtask
function real func (input real a, input real b,input integer min_sum_flag);//min_sum ��p����ꍇ�́@min_sum_flag =1�ɐݒ肷��
real den,num;
real sign;
real min;
begin
if (min_sum_flag) begin
sign=a*b > 0 ? 1.0 : -1.0;
min=$fabs(a) > $fabs(b) ? $fabs(b) : $fabs(a);
func=sign* min;
end else begin
num=1.0 +$exp(a+b);
den=$exp(a)+$exp(b);
func=$log(num/den);
end
end
endfunction
���ʂł��Biteration �́A5��ɂ��܂����B�ӊO�ɂ��A�w��Optimum�Ȍ��ʂɂȂ�܂����B���ۂ̂Ƃ���A2��ł��A�w�LjႢ�́A�Ȃ��悤�Ɏv���܂��B
�ǂ����āA����iterative algorithm���������邩�Ƃ����̂́A���o�I�Ɍ����Ă��s�v�c�ł��ˁB
����ɂ��Ă��A����ȏ�ȒP�����悤�̂Ȃ�LDPC������ɂȂ��Ă���A�ʔ����ۑ�ɂȂ��Ă��܂��B�B
�O���t�����Ă݂܂����BMin-Sum �ƃ��[�N���b�h�́A�s�b�^���d�Ȃ��Ă��܂��Ă��܂��B1e-3�Ō���ƁA
���G���[���[�g�ɑ��āA�T��B�ʂ̃Q�C��������܂��B�������ɂ��ш�m�C�Y�̏㏸�́A2�{�̂R��B�Ȃ̂ŁA��������
����Č�������Q��B�̕����������������邱�ƂɂȂ�܂��B�i�Q��B���M�d�͂𗎂Ƃ��Ă�����BER��������j
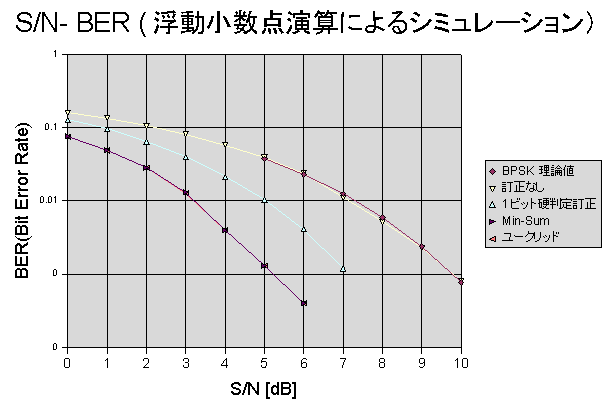
F:\regression_test\ldgm\iterative_decoding.v(3)::iterative_decoding
Verilog�̃V�~�����[�V�����̏������������܂����B�X�^�[�g��,Go�{�^���������Ă��������B
------------- �V�~�����[�V�������J�n���܂��B--------------------
10000�̃����_���f�[�^�����ł��B
�p���e�B�����ł��B
-------------------------------------------------
�m�C�Y�p���[�@0.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@0.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 1607 �G���[���[�g=1.607000e-001
�n�[�h������H����
�g�[�^���G���[���� 1280 �G���[���[�g=1.280000e-001
Min-Sum Iterative Decoding Log�V�X�e������
�g�[�^���G���[���� 765 �G���[���[�g=7.650000e-002
ML�V�X�e������
�g�[�^���G���[���� 755 �G���[���[�g=7.550000e-002
-------------------------------------------------
�m�C�Y�p���[�@1.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@1.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 1345 �G���[���[�g=1.345000e-001
�n�[�h������H����
�g�[�^���G���[���� 969 �G���[���[�g=9.690000e-002
Min-Sum Iterative Decoding Log�V�X�e������
�g�[�^���G���[���� 494 �G���[���[�g=4.940000e-002
ML�V�X�e������
�g�[�^���G���[���� 489 �G���[���[�g=4.890000e-002
-------------------------------------------------
�m�C�Y�p���[�@2.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@2.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 1061 �G���[���[�g=1.061000e-001
�n�[�h������H����
�g�[�^���G���[���� 645 �G���[���[�g=6.450000e-002
Min-Sum Iterative Decoding Log�V�X�e������
�g�[�^���G���[���� 283 �G���[���[�g=2.830000e-002
ML�V�X�e������
�g�[�^���G���[���� 282 �G���[���[�g=2.820000e-002
-------------------------------------------------
�m�C�Y�p���[�@3.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@3.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 810 �G���[���[�g=8.100000e-002
�n�[�h������H����
�g�[�^���G���[���� 402 �G���[���[�g=4.020000e-002
Min-Sum Iterative Decoding Log�V�X�e������
�g�[�^���G���[���� 131 �G���[���[�g=1.310000e-002
ML�V�X�e������
�g�[�^���G���[���� 128 �G���[���[�g=1.280000e-002
-------------------------------------------------
�m�C�Y�p���[�@4.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@4.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 577 �G���[���[�g=5.770000e-002
�n�[�h������H����
�g�[�^���G���[���� 214 �G���[���[�g=2.140000e-002
Min-Sum Iterative Decoding Log�V�X�e������
�g�[�^���G���[���� 40 �G���[���[�g=4.000000e-003
ML�V�X�e������
�g�[�^���G���[���� 40 �G���[���[�g=4.000000e-003
-------------------------------------------------
�m�C�Y�p���[�@5.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@5.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 393 �G���[���[�g=3.930000e-002
�n�[�h������H����
�g�[�^���G���[���� 104 �G���[���[�g=1.040000e-002
Min-Sum Iterative Decoding Log�V�X�e������
�g�[�^���G���[���� 13 �G���[���[�g=1.300000e-003
ML�V�X�e������
�g�[�^���G���[���� 13 �G���[���[�g=1.300000e-003
-------------------------------------------------
�m�C�Y�p���[�@6.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@6.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 238 �G���[���[�g=2.380000e-002
�n�[�h������H����
�g�[�^���G���[���� 41 �G���[���[�g=4.100000e-003
Min-Sum Iterative Decoding Log�V�X�e������
�g�[�^���G���[���� 4 �G���[���[�g=4.000000e-004
ML�V�X�e������
�g�[�^���G���[���� 4 �G���[���[�g=4.000000e-004
-------------------------------------------------
�m�C�Y�p���[�@7.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@7.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 110 �G���[���[�g=1.100000e-002
�n�[�h������H����
�g�[�^���G���[���� 12 �G���[���[�g=1.200000e-003
Min-Sum Iterative Decoding Log�V�X�e������
�g�[�^���G���[���� 3 �G���[���[�g=3.000000e-004
ML�V�X�e������
�g�[�^���G���[���� 3 �G���[���[�g=3.000000e-004
-------------------------------------------------
�m�C�Y�p���[�@8.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@8.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 52 �G���[���[�g=5.200000e-003
�n�[�h������H����
�g�[�^���G���[���� 2 �G���[���[�g=2.000000e-004
Min-Sum Iterative Decoding Log�V�X�e������
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
ML�V�X�e������
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
-------------------------------------------------
�m�C�Y�p���[�@9.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@9.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 23 �G���[���[�g=2.300000e-003
�n�[�h������H����
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
Min-Sum Iterative Decoding Log�V�X�e������
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
ML�V�X�e������
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
-------------------------------------------------
�m�C�Y�p���[�@10.000000[dB] �_���Ő������ł��B
�m�C�Y�p���[�@10.024707[dB]�̐��������܂����B
�m�C�Y�����Z���ł��B
�����Ȃ��V�X�e������
�g�[�^���G���[���� 8 �G���[���[�g=8.000000e-004
�n�[�h������H����
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
Min-Sum Iterative Decoding Log�V�X�e������
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
ML�V�X�e������
�g�[�^���G���[���� 0 �G���[���[�g=0.000000e+000
---------- �V�~�����[�V�������I�����܂��Btime=0----------
���āA�ȏ�ŗ��z�������V�X�e���ł̃��f���̍\�z���ł��܂����B���܂ł́A�_���������ӎ����܂���ł����B���ʂ̖��́A�r�b�g������ɂ��邩�Ƃ������ł��B
����ɂ́A��̃��f����ʎq���r�b�g�����p�����[�^�ɂ��āA�V�~�����[�V�������Ă݂�����ł��ˁB
�ʎq���덷�����荞��ł���̂ŁA��̃V�~�����[�V��������͔������܂���B���z�l��m������ł�
�Q�[�g��/���x�Ƃ̃g���[�h�I�t�ɂȂ�܂��BVersion�@1.83��regresiion_test\ldgm�t�H���_�ɏ�̃R�[�h�͓����Ă��܂��̂ŁA��������A
�X�̃A�C�f�A��W�J���Ă݂�̂��悢��������܂���B
�r�b�g���̌���
�A�[�L�e�N�`�������܂����̂ŁARTL�������āA�r�b�g���̌������s���܂����B
���̒i�K�ł́A���x�ƁA������H�K�́A���\�̃g���[�h�I�t�ɂȂ�̂ŁA�r�b�g�����p�����[�^�ɂ��āA�������s���Ă��܂��B
���̋L�q�́A�n�[�h�E�F�A�g�b�v�̃|�[�g�L�q�ł����A�r�b�g��BW���p�����[�^�ɂ��Ă��܂��BXILINX�ł́A���̃p�����[�^��
�����ƔF�����Ă���āABW�̒l�������邾���ŁA�S�̂̃r�b�g�����ς���Ă���܂��B�r�b�g���̃R�X�g�́A�������Ă݂Ȃ���
�\�z�����Ȃ����Ƃ������A���̎�@�͂����߂ł��B
module hardware # (parameter BW=8)
( input [BW*8-1:0] indata,
output reg [3:0] outdata,
input clock, Reset );
localparam integer FIFO_DEPTH=6;
reg [BW*8-1:0] indataR,indataR_D;
�܂��A����HW�L�q�ł́Averilog-2001��generate ���g���ăp�C�v���C�����W�X�^�������Ă݂܂����BFIFO_DEPTH���p�����[�^�Ƃ��āAHW�ύX�ɑ��ď_��ɂ��Ă��܂��B(Verilog 2001 generate�ɂ��ẮA�����������Q�Ƃ��������B�j
generate
genvar g;
for (g=0;g <FIFO_DEPTH; g=g+1) begin :fifo
reg [3:0] BinDD;
reg [3:0] word0_D;
reg [3:0] word1_D;
reg [3:0] word2_D;
if (g==0) begin :if_label //why xilinx needs label here?
always @(posedge clock) begin
BinDD<=BinD;//2nd
word0_D<=word0[3:0];//2nd
word1_D<=word1[3:0];
word2_D<=word2[3:0];
end
end else begin :else_label//why xilinx needs label here?
always @(posedge clock) begin
BinDD<=fifo[g-1].BinDD;//
word0_D<=fifo[g-1].word0_D;//
word1_D<=fifo[g-1].word1_D;
word2_D<=fifo[g-1].word2_D;
end
end //if
end //for
endgenerate
�Ƃ���ŁA���\�ł����A��Ă��Ă���A�[�L�e�N�`���ł́AML�̗��z�l�ɂ������āA�͔������܂���B�����ł́A0.5��B�ʂɂƂǂ߂����Ǝv���Ă��܂��B���̃V�X�e���V�~�����[�V�����̃O���t����A3�r�b�g�ȏオ�K�v�ł��邱�Ƃ��킩��܂��B�Ȃ��A�����x���`�ŁA�����Ɏg����RTL�ł��V�~�����[�V����
���s���A����̌��ʂł��邱�Ƃ��m�F���܂����B���̃V�~�����[�V�����ł́A�e1e6�r�b�g�����Ă��܂��B�G���[���[�g���Ⴂ�Ƃ���ŁA�o�^���Ă���̂́A���̃G���[�����łȂ��ׂł��B
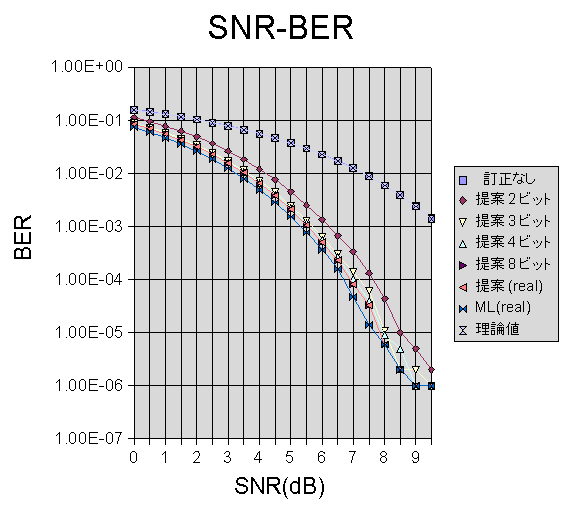
������̋K�́E���x���A��̑z����ł����̂ŁA����ŁA�R�A���̐v�I���ł��B
�]�k�ł����AXILINX�X�p���^���R��Stratix2�Ƃł́A���W�b�N�̐[�����Ⴂ�܂��B�X�p���^���R�́A�ƂĂ��̂ŁA�[�����W�b�N��
���������ł��܂���B��ꂽ���W�b�N�́A�����x�ቺ�Ƃ����`�Ō���܂��B�ŏ�3�i�ʂŏ����Ă��܂������A70MHz��
�����o�Ȃ��āA�ڂ��^���܂����B���ʁA�ŏI�I��8�i�ɂȂ��Ă��܂��܂����B�����Ă͂��܂��AST2�Ȃ玩�g�̍ō����x��ۂ����܂܁A3-4�i�Ŏ��܂�悤�ȋC�����܂��B
=>�������ɍő��f�o�C�X�iST2�j���g���Ƒ������ʂɂȂ�܂����B
| �����\�t�g/�f�o�C�X | �����Ώ� | LUT�� | �x��(ns) | ���g���iMH���j | LUT���� | ���x�� | �]�����[�g(Gbps) |
| Quartus�T�D�P/ | ���t�@�����X��H | 14 | 10.57 | 94.60 | 1 | 1 | |
| EP2S15F484C3 | hardware.v | 309 | 2.11 | 473.26 | 22.07 | 5.003 | 3.79 |
| ISE7.1/ | ���t�@�����X��H | 17 | 12.73 | 78.57 | 1 | 1 | |
| XC3S200-4 | hardware.v | 291 | 5.37 | 186.22 | 17.12 | 2.370 | 1.49 |
�x���V�~�����[�V����
�@�v�����R�A�̒x���V�~�����[�V�������s���Ă݂܂����BRTL��́A9�N���b�N�x���Ȃ̂ł����A�o�͂̒x��(��7ns)�̂��߁A10�N���b�N�x���ɂȂ��Ă��܂��Ă��܂��B
�܂��A���ŁA1�r�b�g�Ȃ����A2�r�b�g�̃G���[�p�^�[�����������Ă��܂����A�������s���ăm�C�Y���Z�O�̃f�[�^���Č����Ă��邱�Ƃ�������܂��B
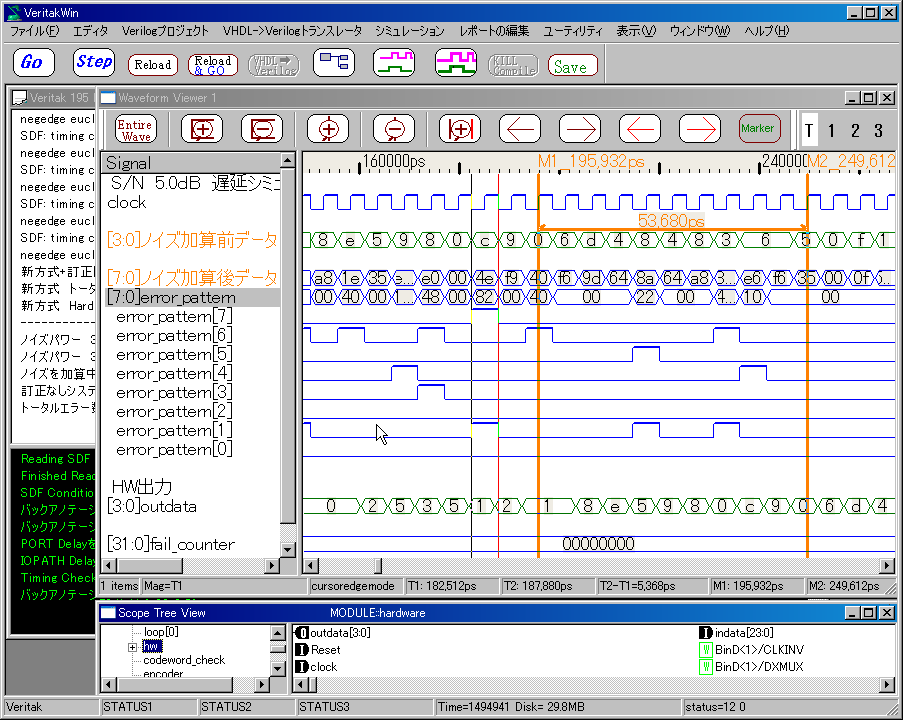
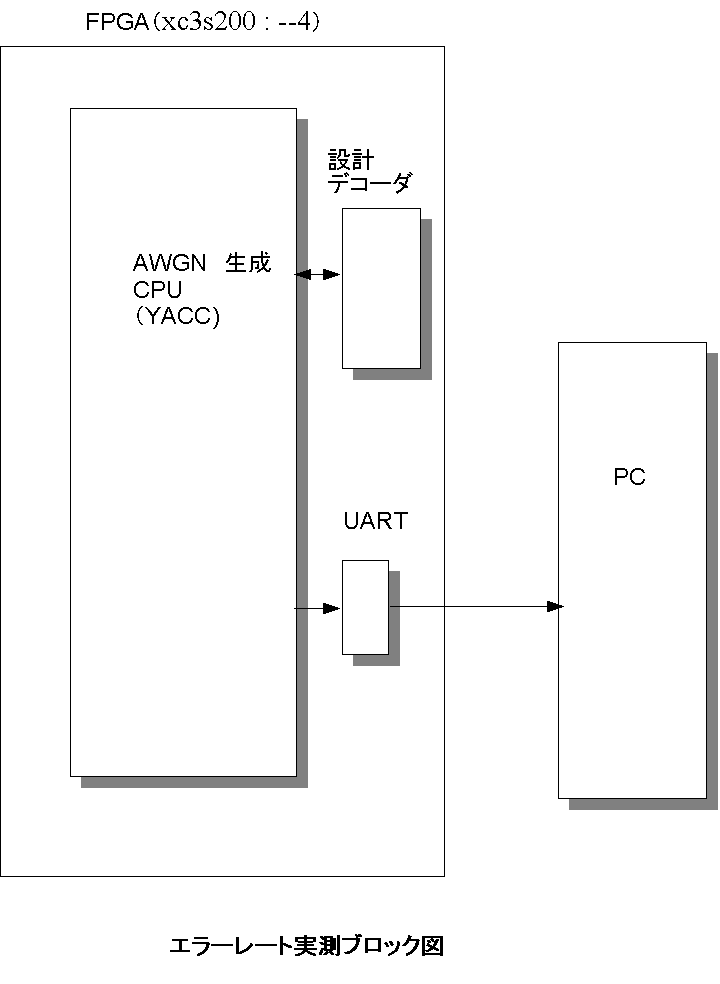
YACC�Ƃ̌���
YACC�̃�������ɃR�A���}�b�v���A������H���쐬���܂��B
3E�́A�҂��Ă����Ȃ��̂ŁA�X�p���^���R�̃X�^�[�^�L�b�g��ō쐬���܂����B���ʁAC�v���O�����̃_�C�G�b�g��]�V�Ȃ�����܂����B
Area�D��ŁA�x����25ns�������Ă��܂��B
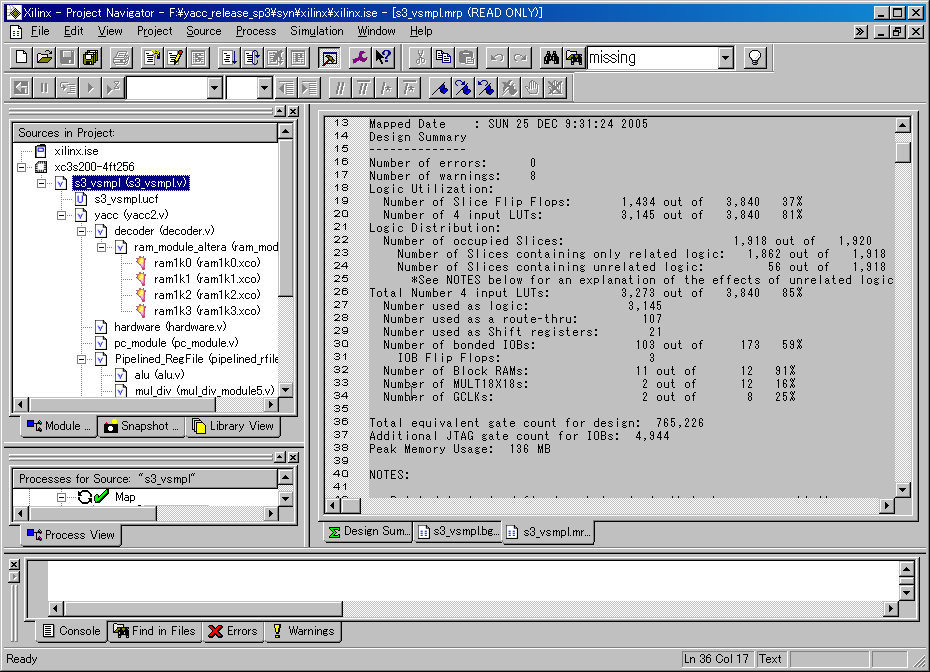
��́A���̂悤�ȁAC�v���O�������Ђ����瑖�点�AUART�ŁA�G���[���[�g�̕��i�Q�āj�҂ĂA�悢�����ł��B
double target_sds[]={ 1.0, //0db PASS0
0.891,//1db 1
0.794,//2db 2
0.708,//3db 3
0.631,//4db 4
0.562,//5dB 5
0.501,//6dB 6
0.447,//7 7
0.422,//7.5 8
0.398,//8.0 9
0.376,//8.5 10
0.355,//9 11
0.335,//9.5 12
0.315// 10.0 13
};
void main()
{
double sum,avg,a,target_sd;
double noise;
int i,j,index,I;
unsigned data_in,data_out;
int n=No;
#ifdef RTL_SIM
print_uart("V1.1\n");
#endif
total_bits=0;
sum=0;
// for (i=0;i< (STATISTICS_LEVELS*2);i++) counter_array[i]=0;
for(j=0;j< 14 ;j++) {
target_sd=target_sds[j];
bit_counter=0;
bit_error_counter=0;
raw_bit_error_counter=0;
do{
data_in=make_input_data(target_sd);
#ifndef DOS
data_write_and_compare(data_in);
#endif
bit_counter +=4;
total_bits +=4;
if (bit_error_counter> ERROR_THRESHOLD){
print_uart("Pass=");
print_num(j);
print_num(bit_counter);
print_num(raw_bit_error_counter);
print_num(bit_error_counter);
print_uart("EndPass\n");
break;
}
}while(1);
}
#ifdef DOS
#ifdef SD_DISPLAY
avg=sum/No;
sum=0;
for (i=0;i<No;i=i+1){
a=array[i]-avg;
sum=sum+a*a;
}
sd=sqrt(sum/No);
printf("Done %d samples. avg=%f target_sd=%f sd=%f",n,avg,target_sd,sd);
#endif
printf("Done %d samples. target_sd=%f\n",n,target_sd);
for (i=0;i< (STATISTICS_LEVELS*2);i++){
printf("%d,%d\n",i-STATISTICS_LEVELS,counter_array[i]);
}
#else
print_uart("Done All\n");
#endif
}
��������
AWGN�̐����Ɏ��Ԃ��������Ă���̂ŁA������݂̃r�b�g���́A������ʂƂȂ�܂������A����ł��AH/W��
�쐬�����Ԃ��l����ƁA�����I�ȑË��_�ł͂Ȃ����Ǝv���܂��B��y��C�v���O����������CPU������ƁA
����H/W�̌����y�ɂȂ邱�Ƃ��A�������܂����B
�@����AC�v���O�����̃f�o�b�O��Veritak��ōs���܂������AAWGN�̐����́A���Ԃ�������̂Ō��\�Ȏ��Ԃ�������܂����B
�\�t�g�E�F�A�V�~�����[�^�ł́A�����ɑ��点�邱�Ƃ��ł��܂����A����H/W�́A�Ǝ��Ȃ̂ŁA��͂�RTL�ł̍��������]�܂����Ǝv���܂����B
�܂��A�V�X�e���̌����ł́ARTL�͂��̂܂܂ŁA����ȊO��VPI���g����C�Ăяo���ō쐬���Ă��悩������������܂���B
�����A���Ԃ�����̂ŁA���̓_�ł̌��������Ă݂����Ǝv���܂��B
�Ȃ��A����́A�����̃G���W�j�A���̗ǎ��Ƃ̋���ł��B
����
��VPI���g��������RTL�V�~�����[�V������
H/W�̋L�q�ȊO�̎��ӂ�C�ŋL�q���āARTL�V�~�����[�V���������������܂����B
���ꂾ�ƁA���r�b�g��1e9�̃e�X�g�ł��A����قǎ��Ԃ́A������܂���B��̃X�p���^���R�ł̃e�X�g�����A
���Ȃ葬���ł��B���@CPU�̕�����Ȃ��Ȃ��Ă��܂��B�i�Ȃɂ��A�\�t�g�t���[�g25MHz�쓮�ł��̂ŁB�j
H/W���́A�����Ɏg�p�����\�[�X�ł����AAWGN�̃v���O�����������Ȃ̂ŁA���@�Ɠ������ʂɂȂ�͂��ł��B
�ȉ��e�X�g�x���`�ł��B
//RTL VPI��p����������
`timescale 1ns/1ps
`define CYCLE 10
module euclidean_error_rate;
parameter integer ERROR_LIMIT=1000;//�G���[���@��������玟��DB�@STEP�ɍs��
parameter integer BW=3;//�r�b�g��
parameter integer FIFO_DEPTH=9;//�n�[�h�E�F�A�̒x���҂�
reg clock=0;
reg [31:0] VPI_Data;//VPI�ŕԂ����l
wire [23:0] indata=VPI_Data[23:0];//�n�[�h�E�F�A����3�r�b�g���W�r�b�g
wire [3:0] correct_data=VPI_Data[27:24];//���Ғl
wire [3:0] outdata;//�n�[�h�E�F�A�o��
reg Reset=1;
reg [63:0] bit_counter=0;
integer bit_error_counter=0;
real DB;
real sigma;
initial begin
#100;
Reset=0;
DB=0.0;
set_sigma;
end
generate
genvar gen;
for (gen=0;gen<FIFO_DEPTH;gen=gen+1) begin :loop
reg [4:0] D;
if (gen==0) begin
always @(posedge clock) begin
D<={Reset,correct_data};
end
end else if(gen==FIFO_DEPTH-1) begin//�n�[�h�E�F�A�̒x���N���b�N���A���Ғl���x��������
always @(posedge clock) begin
D<=loop[gen-1].D;
@(negedge clock);
if (D[4]==0 ) begin//RESET ��LOW�̂Ƃ������J�E���g����
bit_counter=bit_counter+4;
count_bit_error(D[3:0],outdata);//�G���[���̃J�E���g�@D[3:0]�́A���Ғl
end
end
end else begin
always @(posedge clock) begin
D<=loop[gen-1].D;
end
end
end
endgenerate
task count_bit_error( input [3:0] in1,in2) ;
integer i;
real rate;
begin
if ( in1 !==in2) begin
for (i=0;i<4;i=i+1) begin
if (in1[i] !==in2[i]) bit_error_counter=bit_error_counter+1;
end
end
if (bit_error_counter >ERROR_LIMIT) begin//�G���[����LIMIT���������玟��DB�@STEP
rate=bit_error_counter;
rate=rate/bit_counter;
$display("DB=%f bits=%d error=%d error_rate=%e sigma=%f",DB,bit_counter,bit_error_counter,rate,sigma);
DB=DB+0.5;
bit_counter=0;
bit_error_counter=0;
set_sigma;
end
end
endtask
task set_sigma;
real sigma2;
begin
sigma2=$pow(10.0,-DB/10.0);//
sigma=$sqrt(sigma2);//$sqrt
end
endtask
always @(negedge clock) begin
#1;
if (Reset) ;
else begin
VPI_Data=$my_random_for_dwm(sigma);//DWM �p�@VPI
end
end
always #(`CYCLE) clock=~clock;
hardware # ( .BW(BW)) hw ( .indata(indata), .outdata(outdata), .clock(clock), .Reset(Reset) );
endmodule
VPI�\�[�X�ł��B
static int sys_my_random_for_dwm_size_tf()//Aug.42003
{
return 32;
}
/* position of right-most step */
#define PARAM_R 2.96454468156
/* level values */
static const double ytab[32] = {
1,
0.907475617638,
0.8387295158,
0.780775785072,
0.729446868113,
0.682776316768,
0.639647716015,
0.599353201849,
0.561409662765,
0.525469625896,
0.491273228111,
0.458620229136,
0.427352696597,
0.397343775955,
0.368490127285,
0.340706676394,
0.313922886649,
0.288080067698,
0.263129417761,
0.23903060658,
0.215750777731,
0.193263899438,
0.171550433862,
0.150597335281,
0.130398439093,
0.110955385052,
0.0922793705114,
0.0743943543072,
0.0573431209268,
0.0411998625242,
0.0261009770388,
0.0123479825627,
};
/* quick acceptance check */
static const unsigned long ktab[32] = {
0,
12465559,
14143380,
14859376,
15254596,
15503949,
15674743,
15798352,
15891342,
15963265,
16020003,
16065358,
16101882,
16131333,
16154939,
16173564,
16187797,
16198017,
16204425,
16207053,
16205755,
16200181,
16189707,
16173323,
16149413,
16115345,
16066638,
15995077,
15883832,
15691829,
15281721,
15063248
};
/* quick value conversion */
static const double wtab[32] = {
2.6265107239e-08,
3.5349827263e-08,
4.19328107856e-08,
4.73449074891e-08,
5.20705831605e-08,
5.63468970139e-08,
6.03100167664e-08,
6.40468149156e-08,
6.76171489147e-08,
7.10648776583e-08,
7.44238783956e-08,
7.77216053723e-08,
8.09813473119e-08,
8.42237615336e-08,
8.74679979284e-08,
9.0732597892e-08,
9.4036290297e-08,
9.73987784303e-08,
1.00841606117e-07,
1.04389204949e-07,
1.08070261837e-07,
1.11919620405e-07,
1.15981071511e-07,
1.20311664676e-07,
1.24988739931e-07,
1.30122131768e-07,
1.35877026736e-07,
1.42521234138e-07,
1.50537318078e-07,
1.60949814958e-07,
1.76700632665e-07,
1.96806467179e-07
};
unsigned long s1=0xffffffff,s2=0xffffffff,s3=0xffffffff;
unsigned long taus88_int ()
{/*Generates numbers between 0 and 1.*/
unsigned b;
b =(((s1 <<13)^s1)>>19);
s1 =(((s1 &4294967294)<<12)^b);
b =(((s2 <<2)^s2)>>25);
s2 =(((s2 &4294967288)<<4)^b);
b =(((s3 <<3)^s3)>>11);
s3 =(((s3 &4294967280)<<17)^b);
return ((s1 ^s2 ^s3));
}
double taus88 ()
{
return (taus88_int()*2.3283064365e-10);
}
double
gsl_ran_gaussian_ziggurat ()
{
unsigned long U, sign, i, j;
double x, y;
while (1) {
U = taus88_int();
i = U & 0x0000001F; /* 7 bit to choose the step */
sign = U & 0x00000020; /* 1 bit for the sign */
j = U>>6; /* 24 bit for the x-value */
x = j*wtab[i];
if (j < ktab[i]) break;
if (i<32) {
double y0, y1;
y0 = ytab[i];
y1 = ytab[i+1];
y = y1+(y0-y1)*taus88();
} else {
x = PARAM_R - log(1.0-taus88())/PARAM_R;
y = exp(-PARAM_R*(x-0.5*PARAM_R))*taus88();
}
if (y < exp(-0.5*x*x)) break;
}
return sign ? x : -x;
}
unsigned quantize(double rvalue)
{
double R;
int qdata;
R=rvalue*1;
if (R>=1.5) qdata=3;
else if (R>=1.0) qdata=2;
else if (R>=0.5) qdata=1;
else if (R>=0) qdata=0;
else if (R>=-0.5) qdata=-1;
else if (R>=-1.0) qdata=-2;
else if (R>=-1.5) qdata=-3;
else qdata=-4;
qdata &=0x7;//3bit ��o��
return qdata;
}
unsigned get_random_data()
{
unsigned y;
unsigned r0,r1,c0,c1;
unsigned y0,y1,y2,y3;
unsigned outdata;
y=taus88_int();//�����_���f�[�^��B����4�r�b�g�����g���Ă��Ȃ�
//�r�b�g��o��
y0=y & 0x01;
y1=(y >> 1) & 0x01;
y2=(y >> 2) & 0x01;
y3=(y >> 3) & 0x01;
//�p���e�B�v�Z
r0=y0 ^ y1;
r1=y2 ^ y3;
c0=y0 ^ y2;
c1=y1 ^ y3;
outdata=y0;
outdata |=y1 <<1;
outdata |=y2 <<2;
outdata |=y3 <<3;
outdata |=r0 <<4;
outdata |=r1 <<5;
outdata |=c0 <<6;
outdata |=c1 <<7;
outdata <<=24;// ���8�r�b�g�������O�m�C�Y���Z�O�G���R�[�h�f�[�^
return outdata;
}
unsigned make_input_data(double target_sd)
{
double rvalue;
unsigned temp;
unsigned i,j;
double noise;
unsigned outdata;
unsigned word;
outdata=get_random_data();//�G���R�[�_���8�r�b�g�ɃG���R�[�h�f�[�^
//3�r�b�g�A�i���O��M�l�̍쐬
for (i=0;i<8 ;i++) {
noise=gsl_ran_gaussian_ziggurat();//1.0 �K�E�X�m�C�Y����
#ifdef STATISTICS
statistics(noise);//�K�E�X�m�C�Y�̓x�����z����
#endif
noise *=target_sd;//�m�C�Y�V�O�}��Z
if ( (outdata >> (24+i)) & 0x01) {
rvalue=-1.0;//1-> -1��
}else rvalue=+1.0;//0-> +1�ɃG���R�[�h
rvalue +=noise;
temp=quantize(rvalue);//3�r�b�g�ɗʎq��
temp <<=3*i;
outdata |=temp;
}
return outdata;
}
static int sys_my_random_for_dwm(char* name)
{
vpiHandle systfref,argsiter,argh;
t_vpi_value value;
double r;
systfref = vpi_handle(vpiSysTfCall, NULL); /* get system function that invoked C routine */
argsiter = vpi_iterate(vpiArgument, systfref);/* get iterator (list) of passed arguments */
argh = vpi_scan(argsiter);/* get the one argument - add loop for more args */
if(!argh){
vpi_printf("$VPI missing parameter.\n");
return 0;
}
value.format = vpiRealVal;
�@�@vpi_get_value(argh, &value);
�@�@r = value.value.real;
value.value.integer =make_input_data(r) ;
value.format = vpiIntVal;/* return the result */
vpi_put_value(systfref, &value, NULL, vpiNoDelay);
vpi_free_object(argsiter);
return(0);
}
extern "C" void sys_math_vpi_register()//VPI�@DLL���[�h��CALL����A��Function���o�^�����B
{
s_vpi_systf_data tf_data;
//Dec.30.2005 FOR DWM
tf_data.type = vpiSysFunc;//Define as function
tf_data.subtype =vpiIntFunc;//return by integer
tf_data.tfname = "$my_random_for_dwm";
tf_data.user_data = "$my_random_for_dwm";
tf_data.calltf = sys_my_random_for_dwm;
tf_data.compiletf = 0;
tf_data.sizetf = sys_my_random_for_dwm_size_tf;//func �Ȃ̂ŕԂ�
vpi_register_systf(&tf_data);
}
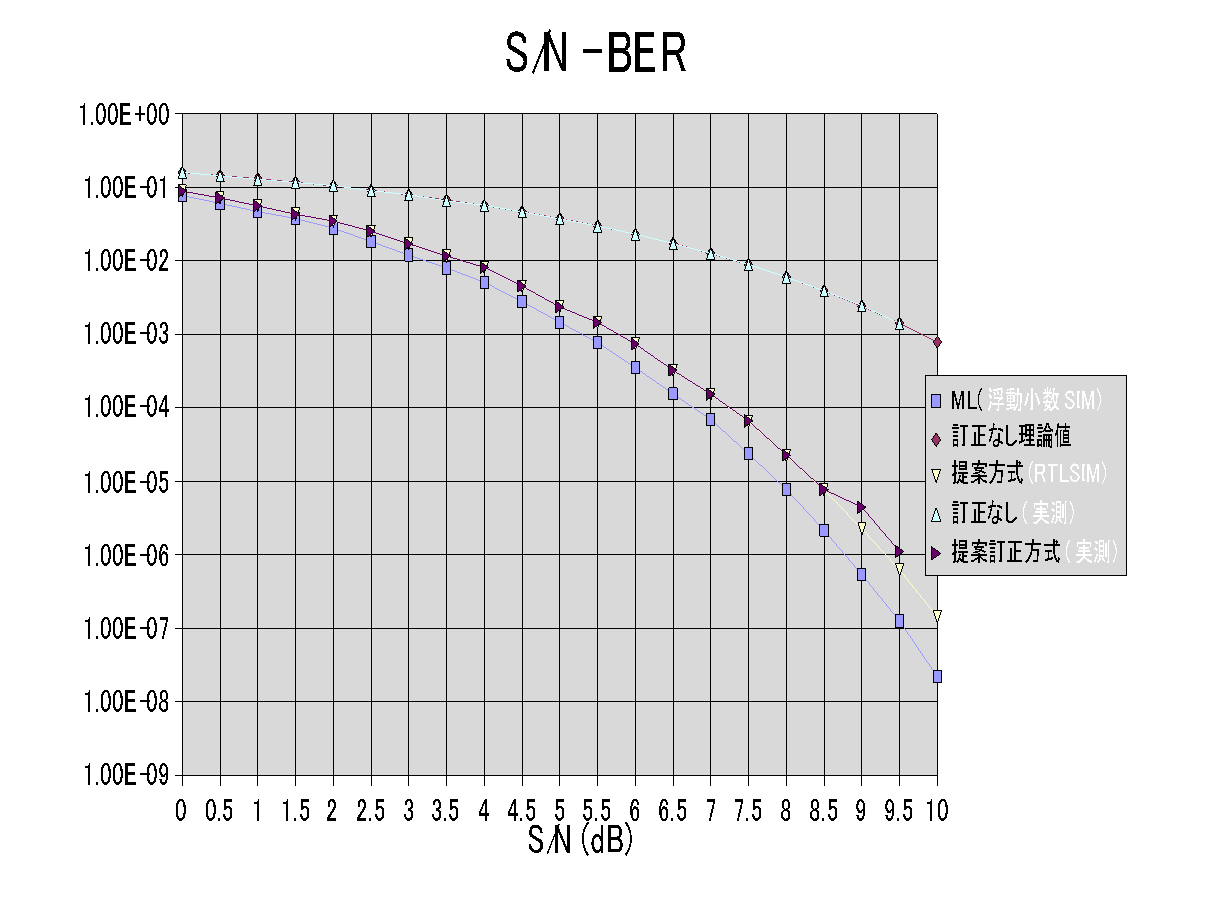
RTL�V�~�����[�^�ŁAC�̃f�o�b�O������Ȃ�āA�M�҂��炢�ł��傤���B�ŏI�I�Ȍ��ʂł��B9/9.5dB�̎����ŁARTL�V�~�����[�V�����l�ƈ�v���Ă��Ȃ��̂́A����2�_�����A�G���[�����P�O�Ŏ~�߂Ă��邽�߂Ǝv���܂��B
���̃f�[�^�́A���ׂ�1000�ȏ�̃G���[���ł����ARTL�V�~�����[�V�����l�Ƃ悭��v���Ă��܂��B�ǂ����ĂP�O�Ŏ~�߂Ă��邩�Ƃ����ƁA���Ԃ��Ȃ���������ł��B
1.3e8�r�b�g���e�X�g����̂ɁA1�T�Ԉȏ�܂����B���̃f�[�^9.0db�ł́A�����炭3�T�Ԃ͂������Ă��܂��ł��傤�B
��������AWGN���{���ɃK�E�X���z���Ă���̂������ׂ܂����B�J�C���挟��ō��i�ł��B
��o�������|�[�g�ł��B
�V�X�e���̌�������o�b�N�A�m�e�[�V������̒x���V�~�����[�V�����܂ŁA�P��̌���Verilog�@HDL��Ō������s���܂����B
����Ȃ�������A���x�I�Ƀl�b�N�̕����́AC/C++�ŋL�q���āAVerilog�@HDL�ŌĂяo���Ă��܂��悢�̂ł��B
�A
�e�X�g�x���`���V�X�e���̌�������x���V�~�����[�V�����܂ŁA�ς��Ȃ��������Ƃɂ��C�Â��ł��傤���H���̎���HDL���g��
�����Ƃ��傫�ȓ_���ƕM�҂͎v���܂��B�m����H/W�́A���ۂ����̂ցA���Ȃ킿�A���f��->RTL->�Q�[�g�[���x�����Q�[�g�ɕω����܂������A�e�X�g�x���`�́A�V�X�e����
�g�������̂����̂܂g�p���Ă��܂��B�������A���̋L�q�́ASystemVerilog�ɂȂ��Ă��ύX�̕K�v�͂���܂���B
20�N���O�ɐv���ꂽ���ꂪ�A���̊�{�@�\�͂��̂܂܂ɁA�����Ȃ��Ƃ��A����10�N�ԁA����������̂́A���������Ƃ��Ǝv���܂��B
�@
LDPC��Verilog�@HDL�L�q
�R���e�X�g�ۑ�́ALDGM�̓����ł��B���������Ɉ��܂����ALDPC��Verilog�R�[�f�B���O��́AOpencores���܂߂Ă܂Ƃ܂������̂́A
���J����Ă��Ȃ��悤�Ȃ̂ŁA�����ŋL�q���Ă݂悤���Ǝv���܂��B
�K���AMATLAB��C�ł̗�́A���\����܂��̂ŁA������|�[�g���Ă��������Ǝv���܂��B
T.B.C.
Verilog �ʼn摜�����H�iVersion�@1.74A/3.24A)
Note:�ȉ��́AVeritak�g���I�v�V������Enable�ɂ���8�r�b�g�P�ʂŏ����Ă��܂��B�����Enable���Ȃ��ƁAVerilog-2001�̋K�i�ł́A%u�́A32�r�b�g�P�ʂōs���Ƃ����K�肪����AC����̃C���[�W�����̂܂܈ڐA�����ȉ��̃\�[�X�͐��������삵�܂���B
3.24A����A�����$fwrite��%c���g���܂����A�o�C�i��0�������Ă���(20)�ɂ��Ă��܂��V�~�����[�^������V�~�����[�^�Ԃ������̍���������悤�ł��B�܂��AVeritak�ł́A1�o�C�g���C�g�p��fputc���g�p�ł��܂����A����́AStandard�iLRM)�ł͂���܂���B
Verilog�@2001�ŃT�|�[�g���ꂽ�A�������z��ƃo�C�i���t�@�C���������V�X�e���^�X�N�̗�ł��B
���̗�ł́A24�r�b�g��BMP�t�@�C��(3port.bmp)���o�C�i���œǂݍ���ŁA
�Z�W�����摜(after_abc2.bmp)�ƁA2�l���摜(after_abc3.bmp)�ɂ��Ă��܂��B
���x�����߂�ꍇ�́AC��VPI�������������悢�̂́A�����܂ł�����܂���B
�o�C�i���̃��C�g���s���ɂ́A$fwrite(�h%u�h�A�����j�A������%u�́A�����o�C�i��2�i�̃t�H�[�}�b�g�w���ɂȂ�܂��B�ʏ�A
Verilog�@HDL�ł́A4�l�Ȃ̂Ń�������ł͕���2�r�b�g�ɃA�T�C������Ă��܂����A�����ł́A�����I��1�r�b�g�ɑΉ����܂��B
�܂��A���ӓ_�Ƃ��āA�o�C�i����R/W����ꍇ�́A
$fopen�́A�e�L�X�g���[�h�ł͂Ȃ��A�o�C�i�����[�h�ŊJ���Ȃ��Ă͂����܂���B�i�M�҂��ŏ��e�L�X�g���[�h�ŊJ����
���܂��āA�ςȌ��ʂɔY��ł��܂��܂����B�j�@�@�܂��A�o�C�i�����[�h���s���ɂ́A$fread���g���܂��B
���ϊ�(after_abc1.bmp)
�Z�W�����摜(after_abc2.bmp)
2�l���摜(after_abc3.bmp)
//�Q�l�ɂ���C�\�[�X�́A
//http://www.fit.ac.jp/elec/7_online/lu/sample/bmp_image_proc.cpp
//�ł��B
`define Y_SIZE 2048 // �����ł���ő�摜
`define X_SIZE 2048
`define HIGH 255 //�@�摜�̍ő勭�x�l
`define LOW 0 //�@�摜�̍ŏ����x�l
`define LEVEL 256 //�@�摜�̋��x���x���l
module bmp_test;
parameter read_filename="3port.bmp";
parameter write_filename1="after_abc1.bmp";
parameter write_filename2="after_abc2.bmp";
parameter write_filename3="after_abc3.bmp";
parameter [7:0] INTENSITY=100;//0-255
integer biCompression,
biSizeImage,
biXPelsPerMeter,
biYPelsPerMeter,
biClrUsed,
biClrImportant;
reg [15:0] bfType;
integer bfSize;
reg [15:0] bfReserved1, bfReserved2;
integer bfOffBits;
integer biSize, biWidth, biHeight;
reg [15:0] biPlanes, biBitCount;
reg [7:0] image_in [0:`Y_SIZE][0:`X_SIZE][0:2]; // ���̓J���[�摜�z��
reg [7:0] image_out [0:`Y_SIZE][0:`X_SIZE][0:2]; //�o�̓J���[�摜�z��
reg [7:0] image_bw [0:`Y_SIZE][0:`X_SIZE]; //�Z�W�摜�z��
//********************************************
// 24Bit�r�b�g�}�b�v�t�@�C���ǂݍ��� *
//********************************************
task readBMP(input [128*8:1] read_filename);
integer fp;
integer i, j, k;
reg [7:0] byte;
begin
// �t�@�C���I�[�v��
fp = $fopen(read_filename, "rb") ;//must be binary read mode
if (!fp) begin
$display("readBmp: Open error!\n");
$finish;
end
$display("input file : %s\n", read_filename);
// �w�b�_�[���ǂݍ���
$fread(bfType, fp);
$fread(bfSize, fp);
$fread(bfReserved1, fp);
$fread(bfReserved2, fp);
$fread(bfOffBits, fp);
$fread(biSize, fp);
$fread(biWidth, fp);
if (biWidth%4) begin
$display("Sorry, biWidth%4 must be zero in this program. Found =%d",biWidth);
$finish;
end
$fread(biHeight, fp);
$fread(biPlanes, fp);
$fread(biBitCount, fp);
if (biBitCount !=24) begin
$display("Sorry, biBitCount must be 24 in this program. Found=%d",biBitCount);
$finish;
end
$fread(biCompression, fp);
$fread(biSizeImage, fp);
$fread(biXPelsPerMeter, fp);
$fread(biYPelsPerMeter, fp);
$fread(biClrUsed, fp);
$fread(biClrImportant, fp);
// RGB�摜�f�[�^�ǂݍ���
for (i=0; i< biHeight; i=i+1) begin
for (j=0; j< biWidth; j=j+1) begin
for (k=0; k<3; k=k+1) begin
$fread(byte,fp);
image_in[biHeight-i][j][2-k]=byte;
end
end
end
$display("Current POS=%d",$ftell(fp));
$fclose(fp);
end
endtask
//******************************************************
// 24�r�b�g-�r�b�g�}�b�v�f�[�^��BMP�t�@�C���ɏo�� *
//******************************************************
task writeBMP(input [128*8:1] write_filename,input O);
integer fp;
integer i, j, k;
begin
// �t�@�C���I�[�v��
fp = $fopen(write_filename, "wb");//must be binary read mode
if (!fp) begin
$display("writeBmp: Open error!\n");
$finish;
end
$display("output file : %s\n", write_filename);
// �w�b�_�[���
$fwrite(fp,"%u",bfType);
$fwrite(fp,"%u",bfSize);
$fwrite(fp,"%u",bfReserved1);
$fwrite(fp,"%u",bfReserved2);
$fwrite(fp,"%u",bfOffBits);
$fwrite(fp,"%u",biSize);
$fwrite(fp,"%u",biWidth);
$fwrite(fp,"%u",biHeight);
$fwrite(fp,"%u",biPlanes);
$fwrite(fp,"%u",biBitCount);
$fwrite(fp,"%u",biCompression);
$fwrite(fp,"%u",biSizeImage);
$fwrite(fp,"%u",biXPelsPerMeter);
$fwrite(fp,"%u",biYPelsPerMeter);
$fwrite(fp,"%u",biClrUsed);
$fwrite(fp,"%u",biClrImportant);
// �r�b�g�}�b�v�f�[�^
for (i=0; i< biHeight; i=i+1) begin
for (j=0; j< biWidth; j=j+1) begin
for (k=0; k<3; k=k+1) begin
if (O) $fwrite(fp,"%u",image_out[biHeight-i][j][2-k]);
else $fwrite(fp,"%u",image_in[biHeight-i][j][2-k]);
end
end
end
$display("Current WPOS=%d",$ftell(fp));
$fclose(fp);
end
endtask
//**********************************************
// �q�f�a�J���[�摜��256�~�������Z�W�摜�֕ϊ� *
//**********************************************
task BMPto256BW;
integer y, x, a;
begin
for (y=0; y<biHeight; y=y+1) begin
for (x=0; x<biWidth; x=x+1) begin
a =$rtoi(0.3*image_in[y][x][0] + 0.59*image_in[y][x][1] + 0.11*image_in[y][x][2]);
if (a<`LOW) a = `LOW;
if (a>`HIGH) a = `HIGH;
image_bw[y][x] = a;
end
end
end
endtask
//****************************************
// �����摜��24bit�r�b�g�}�b�v�`���ɕϊ� *
//****************************************
task BWto24BMP;
integer y, x, a;
begin
for (y=0; y<biHeight; y=y+1) begin
for (x=0; x<biWidth; x=x+1) begin
a = image_bw[y][x];
image_out[y][x][0] = a;
image_out[y][x][1] = a;
image_out[y][x][2] = a;
end
end
end
endtask
//****************************************
// �����摜�̂Q�l�� *
//****************************************
task toBinary( input [7:0] intensity);
integer y, x;
begin
for (y=0; y<biHeight; y=y+1)begin
for (x=0; x<biWidth; x=x+1) begin
if(image_bw[y][x] >= intensity) image_bw[y][x]=`HIGH;
else image_bw[y][x] = `LOW;
end
end
end
endtask
initial begin
//�摜����1�F
readBMP(read_filename); // �摜�̓���,RGB24�r�b�g�J���[BMP�摜��z��Ɋi�[
writeBMP(write_filename1,0);//���ϊ��ŏ�������
//�摜�����Q�F�����ϊ�
BMPto256BW; // �q�f�a�J���[�摜�𔒍��摜�ɕϊ�
BWto24BMP; //�@�P�`�����l�������摜���R�`�����l���a�l�o�W���t�H�[�}�b�g�֕ϊ�
writeBMP(write_filename2,1); // �����摜�o��
//�摜�����R�F 2�l��
toBinary(INTENSITY);
BWto24BMP;
writeBMP(write_filename3,1); // �����摜�o��
end
endmodule
|
Verilog �Ńe�L�X�g�t�@�C�������H�iVersion�@1.74A)
��̗�́A�o�C�i���t�@�C����������ł������A�e�L�X�g�t�@�C���������s�����Ƃ��ł��܂��B
�e�X�g�x���`�Ō��ʂ̑Ó������`�F�b�N����p�r�Ƃ��ċ@��͑����̂ł͂Ȃ��ł��傤���H�@
�e�L�X�g�t�@�C�������ɂ́A$fseek,$fscanf,$fdisplay,$fell�����g���܂��B�w��C���̂܂܂ł��ˁB
���́A256MB�̃e�L�X�g�t�@�C�����쐬���āA$fseek��$random�ɔ�сA��������ł���Data�̑Ó������`�F�b�N���Ă��܂��B
�Ȃ��A$random�́A�����t�ŕԂ��̂ŁA$unsigned�������́A�o�p�ŁA�����Ȃ��ɂ��܂��B
//Sep.21.2005
//$fseek/$fscanf/$fdisplay Test
module large_file;
parameter integer WORDS=1024*1024*8;//1024*1024*34 BYTES;
parameter integer STR_LEN=32+2;//CR+LF
integer i;
integer fp;
integer offset;
reg [255:0] R2;
initial begin
//Open
fp=$fopen("large_file.txt","w+");//Open By Write & Read Mode
if (!fp) begin
$display("File Can not be opend.!");
$finish;
end
//Write
$display("Writing Large File..");
for (i=0; i<WORDS;i=i+1) begin
R2={i+7,i+6,i+5,i+4,i+3,i+2,i+1,i};
if (i%10000==1) $display("%d",i);
$fdisplay(fp,"%32x",R2[127:0]);
end
$display("Large Text File genrated Words=%d Total %fMBytes",WORDS,(WORDS*STR_LEN)/1e6);
//Trival Check
trival_check(fp);
//Random Check
random_check(fp);
end
task disp_current_position(input integer fp);
integer position;
begin
position=$ftell(fp);
$display("Current Posion=%d",position);
end
endtask
task trival_check(input integer fp);
parameter OFFSET=10;
begin
$display("Trival Check Starts...");
offset=$ftell(fp);
disp_current_position(fp);
offset=offset-OFFSET*STR_LEN;
$fseek(fp, offset,0);
disp_current_position(fp);
for (i=0;i<OFFSET;i=i+1) begin
$fscanf(fp,"%h\n",R2);
$display("%h",R2);
end
$display("Trival Check Done.\n");
end
endtask
task random_check(input integer fp);
integer EOF;
parameter integer No_of_Checks=1000_000;
integer i,position,aligned_pos,word_pos;
reg [127:0] word;
begin
$display("Random Check.Starts.. It takes several minutes.");
$fseek(fp,0,2);//Go to EOF
EOF=$ftell(fp);//EOF position
disp_current_position(fp);
for (i=0;i< No_of_Checks;i=i+1) begin
position={$random} % EOF;//or $unsigned($random) %EOF
word_pos=(position/STR_LEN);
aligned_pos=word_pos*STR_LEN;
$fseek(fp,aligned_pos,0);//Goto aligned_pos
$fscanf(fp,"%h\n",R2);
word={word_pos+3,word_pos+2,word_pos+1,word_pos};
if (word !==R2[127:0] ) begin//Check result
$display("Fails. Error detected");
$stop;//assert(0);
end
end
$display("Random Test passed. Random %d seeks performed . Error Detected 0",No_of_Checks);
end
endtask
endmodule
Opencores Veritak �v���W�F�N�g�t�@�C���iVersion�P�D�S�PA�j
�@
�@Opencores�ɂ́A�v���t�F�b�V���i�����������l�X��IP�R�A������܂��B������ȒP�ɁA�]��/�������Ă݂������������̂ł͂Ȃ��ł��傤���H
�Ƃ��낪�AOpencores���V��INCLUDE�@�t�@�C����ADefine�̐ݒ蓙���K�v�ȏꍇ������A�@����҂̃V�~�����[�^�����Ȃ��ƊȒP�ɂ����Ȃ��Ƃ��낪����܂��B�V�~�����[�^������o���܂łɍ��܂��Ă��܂����l�����邩������܂���B
�����ŁAVeritak�v���W�F�N�g�t�@�C�����쐬���X��}��܂����B
�𓀂��āA�uVerilog�v���W�F�N�g����Load�@Verilog�v�Ńv���W�F�N�g�t�@�C�������[�h�A�uGo�v�����Ńe�X�g�x���`�����肾���܂��B
�l��RTL�\�[�X�́A���������������̂ł����A�g���[�X�t�@�C���i�^�O�t�@�C���j���Y�t���Ă��܂��̂ŁA��͂̈ꏕ�ɂȂ�ł��傤�B
�K�v�ɉ����ăg���[�X���[�h�ŃR���p�C�����邱�ƂŁA�K�wView�AVeriPad�A�g���[�X�t�@�C���i�^�O�t�@�C���j�AWaveformView��ł̃h���C�o����@�\���A�������z�I�ȉ�͊��ɂȂ锤�ł��B
�v���W�F�N�g�́A�ȉ��̌��؉\�ȃe�X�g�x���`�t�̃R�A�ɂ��č쐬���܂����B
�v���W�F�N�g�͕����쐬���Ă���ꍇ������܂����A���̈Ӗ��́A���̒ʂ�ł��B
| �v���W�F�N�g�̖��O | ���e | ���l |
| *_no_save.prj | �g�`Save�Ȃ��̃v���W�F�N�g�B | �������m�F�ς݁B���̃v���W�F�N�g�ł͔g�`�iWaveformView�j�������ɂȂ�܂���̂ł����ӂ��������B |
| *_trace_mode.prj | �g���[�X���[�h�ł̃v���W�F�N�g | |
| *_trace_mode2.prj | �g���[�X���[�h2�ł̃v���W�F�N�g | �g���[�X�t�@�C���̐����p |
| IP�@CORES | Veritak�@�v���W�F�N�g�t�@�C���ʒu | �\�[�X���s�� | �V�~�����[�V�������ԁiAthlon64 3000+�@�PGB�@Memory�@on�@W2K) |
�_�E�����[�h�iZIP) | ���l |
| AC97 | \ac97_ctrl\bench\verilog | 11K | 49min54sec | AC97�i0.3MB) | ac97_no_save.prj |
| CAN | \can | 12K | 0min | CAN�i0.2MB) | can.prj |
| ATA | \ata | 4K | 13min38sec | ATA�i1MB) | Nov.22.2004 no_save_ata.prj |
| PCI | \pci\bench\verilog | 89K | 2�� | PCI�i14MB) | pci_no_save.prj |
| USB1.1 | \usb11 | 11K | 2min37sec | USB1.1�i0.3MB) | `include����ӏ��lj� usb11_no_save.prj |
| I2C | \i2c | 2K | 2sec | I2C(0.7MB) | i2c.prj |
| ETHERNET | \ethernet\ethernet | 45K | 4h | ETHERNET�i2.6MB) | tb_ethernet_no_save.prj |
| AES | \aes_core | 2K | 13sec | AES�i0.2MB) | aes.prj |
| DES | \des | 2K | 1sec | DES�i0.5MB) | des_trace_mode.prj |
| GENERIC FIFO | \generic_fifos\generic_fifos\bench\verilog | 2K | �Q�� | GENERIC�@�@ FIFO�i0.1MB) |
fifo_no_save.prj |
| GPIO | \gpio\gpio | 4K | 41sec | GPIO�i0.6MB) | gpio.prj |
| WB_DMA | \wb_dma | 15K | 46h | WB_DMA�i1.5MB) | |
| WB_CONBUS | \wb_conbus | 4K | 6sec | WB_CONBUS�i0.4MB) | conbus.prj |
| WB_CONMAX | \wb_conmax | 11K |
10min6sec | WB_CONMAX�i0.2MB) | |
| Divider |
dividers\bench\verilog | divierders | divider.vtakprj (Version 2.11�ȏ�@RunLength10�O0us) |
�i���Ƃ��APentium500MHz���ƁA6�{����x�ɂ͂Ȃ��Ă���悤�ł��B
��Opencores�ɂ��ā�
�@��삪�����ł��B�Ȃ��ɂ́A�V�~�����[�V�������Ԃ��ُ�ɂ������Ă�����̂�����܂����A�i���CPU�x���`�}�[�N�e�X�g��ł́A�����Ă������ł��j�@
����́ARegression�@Test�ŁA�ԗ��I�ȃe�X�g�����Ă��邽�߂ł��B���g�́Atask���ŕ����L�q����A�����FOR�@LOOP�ʼnĂ���̂ŁA�v�G�b�Z���X�̃V�~�����[�V�����ł́A����قǑ���������K�v�͂Ȃ��ł��傤�B
�n�[�h�E�F�A�̋L�q�ɁA�@���Ƃ��AA<=#1A���g���Ă���i�V�~�����[�V�����T�C�N�����]�v�ɂ�����ȊO�ɉ��̉v���Ȃ��L�q�j�A�e�X�g�x���`�ł�Race�L�q�������A���A
�K�������悢�L�q�ƌ����Ȃ����̂��܂܂�Ă��܂����A�S�̂̃��x���Ƃ��Ă͍����A��ώQ�l�ɂȂ�Ǝv���܂��B
�@�Ƃ���ŁA����Opencores�@�͂ǂ����Ă���́H�v�����v���Z�b�T�́A���̈Ӗ�����́H�Ƃ������₪�ǂ����炩���ł������ł��B�M�҂̏ꍇ�́AFAQS��Veritak�̖ڎw���Ă�����̂Ƃ��ď����Ă���܂��̂���������Q�Ƃ��B
Opencores�̐l�B�̓��������p���܂��B
Mainly for fun.
Other reasons include:
- to learn,
- to teach,
- to improve your resume,
- to make the world a better place to live in.
CRC��RTL���������v���O�����̉���iMay.5.2005�@�I���j
<�T��>
���L�����N�ŁAWEB��ŁA�C�Ӑ����������A�C�Ӄr�b�g����RTL�\�[�X�������܂��B
http://www.easics.be/webtools/crctool
���ۂɂ���Ă݂�Ɗm���ɐ������܂��B�Ƃ���ŁA����́A�ǂ�����Đ������Ă���̂ł��傤���H�����v���O�����������āA�����R�[�h���o�͂��邱�Ƃ��m�F���܂����B
�܂��A�g�����̗�Ƃ��āAVerilog-2001�Ńe�X�g�x���`�������܂����B�i�{���́A�p���ł��B�j
�Ȃ��ACRC�ɂ��Ă͈ȉ����ڂ����ł��B
�C���^�[�t�F�[�X2004�@12����CRC��H�̍����ƃA�����W�@�X�����v��
���_����w�т������́A
�������_�@�d�q���ʐM�w��@����G��
�������߂��܂��B
=>CRC32�i�q�e�b�Q�O�W�R) ��C �v���O�����ƌ��ʂ�����Ȃ��A�Ƃ�������������������܂����B
��͂��Ă݂��Ƃ���A�r�b�g��MSB��LSB���t���ɂȂ��Ă���܂����B���H/W������́AMSB������͂���d�l�ɂȂ��Ă��܂��B
������ALSB������͂���d�l��C�v���O�����Ɣ�r����ꍇ�́A�r�b�g�����o�[�X����K�v������܂��ˁB
�����ŁA�r�b�g�����o�[�X����L�q��lj�����Ǝ��̂悤�ɂȂ�܂��B����ɂ��H/W���\�[�X�lj��͂���܂���B�i�z�������ł��j
`define CYCLE (10)
`timescale 1ns/1ns
module crc_module_test;
reg RES; // Reset
reg CLK; // clock
reg[31:0] DATA; // data
wire w_RESULT;//TAK
always #20 CLK =~CLK;
parameter RATE = 50;
wire [31:0] DReverse;//TAK
wire [31:0] ResultReverse;//TAK
generate //TAK
genvar g;
for (g=0; g<32;g=g+1) begin :loop
assign DReverse[g]=DATA[31-g];
assign ResultReverse[g]=_crc_module.crc_reg[31-g];
end
endgenerate
initial begin
#0
RES = 0;
CLK = 0;
DATA = 0;
#200
RES=1;
#(RATE*2)
@(negedge CLK);//NEG TAK
DATA = 32'h000_0001;
@(negedge CLK);//NEG TAK
DATA = 0;//32'h30303030;
#1000;
$finish;
end
crc_module _crc_module(
.RES(RES),
.CLK(CLK),
.DATA(DReverse),//TAK
.CRC_RESULT(w_RESULT)
);
endmodule
�ʏ�AC�v���O�����ł́A256Byte�̃e�[�u���ŁA�PByte�Âv�Z����܂����A���H/W�@Generator�ł́A�C�ӂ̕���x�i�C�ӂ̌꒷�j�Ōv�Z���邱�Ƃ��ł��܂��B�{��ł́A32�r�b�g/CLOCK�ł��B
�������̌�A����ɁA���̂悤�ȃf�[�^���t�@�C������ǂݏo�������A�Ƃ��������₪����܂����B
; �ŏ��̍s�R�����g���v���ȁH 12345678 aaaa5555 ; ����́A�R�����g�s�ł��B�`���ɁG�����邱�ƁB 1111aaaa 3456789a ;�@������A�R�����g�s�ł��B abcdef01 58d7e7e0 ;�Ō�̍s�̃R�����g���v���ȁH���̋L�q���A���[�U�l���炲�������\�[�X�ł��B�i�M�҂Ƃ��Ƃ肵�Ȃ���L�q����܂����B�������R�����g�����ł��B�j
���̕��́AC�ł̋L�q�́A�M�҂��o�����������ł��B���AVerilog�@HDL�́A���Ĕ�Ȃ錾��ł��BC�̗ސ�����ԈႦ�₷��
�ӏ��AVerilog�@2001��FILE�@IO/generate �A�����āAfor loop �ɂ�����break�Acontinue�����Ɋւ���L�q���Q�l�ɂȂ�Ǝv���܂��B
�e�X�g�x���`�̋L�q�ł��B
`define CYCLE (10)
`timescale 1ns/1ns
module crc_module_test;
reg RES; // Reset
reg CLK; // clock
reg START; // calc start
reg[31:0] DATA; // data
parameter integer ROW_LINES=16;//�����p�����^���C�Y
wire w_RESULT;
always #20 CLK =~CLK;
parameter RATE = 50;
//--------------------------------------------------------------------
//�r�b�g����ւ�MSB<->LSB, D30<->D1,....D16<->D15�̏ꍇ�͂��������ׂ�
//--------------------------------------------------------------------
//�������́A������ƋZ�ł��B assgin DReverse[0]=DATA[31];..... �Ɖ��X�����Ă�OK�ł��B
wire [31:0] DReverse;
wire [31:0] ResultReverse;
generate //
genvar g;
for (g=0; g<32;g=g+1) begin :loop
assign DReverse[g]=DATA[31-g];
assign ResultReverse[g]=_crc_module.crc_reg[31-g];
end
endgenerate
//-----------------------------------------------------------
//task readFDATA�œǂݍ��ނ��߂̃o�b�t�@���m��
//-----------------------------------------------------------
reg[31:0] FDATA[0:ROW_LINES]; //���ۂɂ�2048���炢�g�������B�����p�����^���C�Y
reg[31:0] td;
reg [8*100:1] str_buffer;//����$fgets �́A�e�L�X�g�ǂݍ��݂Ȃ̂�Str�o�b�t�@��p�ӂ��܂��B
//����8�́Achar�̈Ӗ��ł��B�R�����g������܂��̂ŁA�\���傫��(100)�ɕύX���܂����B
//-----------------------------------------------------------
//�ǂݍ��݂��J�n
//-----------------------------------------------------------
task readFDATA;
integer fp;
integer i, r,c;
begin
fp = $fopen("tp.txt", "r"); //�_�����ł���Ă݂܂����B
//����OK�ł��B "r" ���w�肵�Ȃ���Default"w"�Ȃ̂�
//��ȃt�@�C�������Ă��܂��܂��B
if (!fp)
begin
$display(" Open error!\n"); //�t�@�C�������݂��Ȃ���ΏI��
$finish;
end
begin : gloval_loop //����break ���邽�߂̃��x��
for(i=0; i< ROW_LINES;i=i+1) // i<16 �������ڐ��l�w�肷����ROW_LINES�@�p�����[�^�Ŏw�肵�������ێ琫����낵�����Ǝv���܂��B
begin :local_loop //����continue���邽�߂̃��x��
if( !$feof(fp) )
begin
c=$fgetc(fp);//�����ꕶ���ǂݍ��݂܂��B
if (c==";") begin //�����R�����g�����͖`����1������ǂ݂܂��B
//���� str_buffer[1] �ł́A��r�b�g�̃Z���N�g�ɂȂ��Ă��܂��܂��B
//�����܂��A"�G"�̃o�b�t�@��̈ʒu�́A�R�����g�̒����ɂ���Ă��܂��ׁA��L�̋L�q�Ƃ��܂����B
r = $fgets(str_buffer,fp);//; �̎�����1�s�ǂ݂܂�
$display("Comment %s",str_buffer);//�R�����g�s����
i=i-1;//���Ȃ�ꂵ���ł��B�B
disable local_loop;//continue
end
$ungetc(c,fp);//�ǂݍ���1������߂��܂��B
// r = $fgets(td, 10, fp); //�����t�@�C������P�s�ǂݍ��ށB�ǂݍ��ރf�[�^��32�r�b�g��
r = $fgets(str_buffer,fp); //���� C�Ƃ͈Ⴂ�܂��B�P�O���w�肷��p�����[�^�͂���܂���B
$sscanf(str_buffer,"%h\n",td); //����sscanf �ʼn��s�܂Ńo�b�t�@����͂��Đ��l�ɒ����܂��B
$display("%d:read data= %h \n",i,td);
FDATA[i] = td; //32�r�b�g���̃f�[�^���i�[
end
else
begin
$fclose(fp);
//�t�@�C���̍Ō�ɓ��B�����甲������
//C�ł���break���������A�\�L�s��
disable gloval_loop; //������break�ɑ������܂��B
//�������Ȃ݂�continue �́Adisable local_loop �Ƃ��Ă��������B
end
end //end local_loop
end //gloval_loop
$display("Exit Task ");
end //endtask
endtask
integer i;
initial begin
// integer i;���� initail process�̊O�Ő錾���Ă��������B
readFDATA; //��`�����^�X�N���R�[��
RES = 0;
CLK = 0;
DATA = 0;
START = 0;
i=0;
#200
RES=1;
#(RATE*2)
//�t�@�C������ǂݍ���FDATA���g����CRC���͂������B
for(i=0; i<ROW_LINES; i=i+1)//����i++ �́AVerilog2001�ł͂���܂���B
begin
@(negedge CLK);//�����n�[�h��Pos�Ȃ̂ŁAneg �œ��͂��Ă��A���[�X��������ł��܂��B
if(i==0)
START = 1;
DATA = FDATA[i] ; //�킴�킴���l���w�肷��̂ł͂Ȃ��t�@�C������ǂl���g������
end
#1000;
$finish;
end
crc_module _crc_module(//����DUT �n�[�h�E�F�A���C���X�^���X�����܂�
.RES(RES),
.CLK(CLK),
.START(START),
.DATA(DReverse),
.CRC_RESULT(w_RESULT)
);
endmodule
�n�[�h�E�F�A�{�̂̋L�q�ł��B�����\�ȃ\�[�X�Ɏd�オ���Ă���Ǝv���܂��B
/*******************************************************************************
** crc check
*******************************************************************************/
module crc_module(
RES, // input :Reset
CLK,
START, // crc calc start
DATA, // input :data
CRC_RESULT
);
/****************************************************************
���W���[�����́A�o��
****************************************************************/
input RES; // Reset
input CLK;
input START;
input[31:0] DATA; // data
output CRC_RESULT; //
/****************************************************************
reg [�����Ŏg�p]
****************************************************************/
reg [31:0] crc_reg;
reg crc_result;
wire[31:0] w_data;
wire[31:0] w_crc_temp;
/****************************************************************
�o�͐ݒ�
****************************************************************/
assign CRC_RESULT = crc_result;
assign w_data = DATA;
generate //����Verilog-2001�@generate�@Xilinx �́AOK�ł����AAltera�@5.1�ł́A�܂��Ή��ł��Ă��Ȃ��悤�ł��B
genvar g;
for (g=0; g<32;g=g+1)
begin
:loop
assign w_crc_temp[g] = crc_reg[31-g];
end
endgenerate
//---------------------------------------------------------
// crc check
//---------------------------------------------------------
always @ (posedge CLK)
if(RES == 0)
begin
crc_reg <= 32'hffffffff;
crc_result <= 0;
end
else
begin
if(START == 1)
begin
crc_reg = nextCRC32_D32(w_data, crc_reg);
if(crc_reg == 0)
begin
crc_result <= 1;
end
end
end
///////////////////////////////////////////////////////////////////////
// File: CRC32_D32.v
// Date: Sat Jan 7 09:33:48 2006
//
// Copyright (C) 1999-2003 Easics NV.
// This source file may be used and distributed without restriction
// provided that this copyright statement is not removed from the file
// and that any derivative work contains the original copyright notice
// and the associated disclaimer.
//
// THIS SOURCE FILE IS PROVIDED "AS IS" AND WITHOUT ANY EXPRESS
// OR IMPLIED WARRANTIES, INCLUDING, WITHOUT LIMITATION, THE IMPLIED
// WARRANTIES OF MERCHANTIBILITY AND FITNESS FOR A PARTICULAR PURPOSE.
//
// Purpose: Verilog module containing a synthesizable CRC function
// * polynomial: (0 1 2 4 5 7 8 10 11 12 16 22 23 26 32)
// * data width: 32
//
// Info: tools@easics.be
// http://www.easics.com
///////////////////////////////////////////////////////////////////////
// polynomial: (0 1 2 4 5 7 8 10 11 12 16 22 23 26 32)
// data width: 32
// convention: the first serial data bit is D[31]
function [31:0] nextCRC32_D32;
input [31:0] Data;
input [31:0] CRC;
reg [31:0] D;
reg [31:0] C;
reg [31:0] NewCRC;
begin
D = Data;
C = CRC;
NewCRC[0] = D[31] ^ D[30] ^ D[29] ^ D[28] ^ D[26] ^ D[25] ^ D[24] ^
D[16] ^ D[12] ^ D[10] ^ D[9] ^ D[6] ^ D[0] ^ C[0] ^
C[6] ^ C[9] ^ C[10] ^ C[12] ^ C[16] ^ C[24] ^ C[25] ^
C[26] ^ C[28] ^ C[29] ^ C[30] ^ C[31];
NewCRC[1] = D[28] ^ D[27] ^ D[24] ^ D[17] ^ D[16] ^ D[13] ^ D[12] ^
D[11] ^ D[9] ^ D[7] ^ D[6] ^ D[1] ^ D[0] ^ C[0] ^ C[1] ^
C[6] ^ C[7] ^ C[9] ^ C[11] ^ C[12] ^ C[13] ^ C[16] ^
C[17] ^ C[24] ^ C[27] ^ C[28];
NewCRC[2] = D[31] ^ D[30] ^ D[26] ^ D[24] ^ D[18] ^ D[17] ^ D[16] ^
D[14] ^ D[13] ^ D[9] ^ D[8] ^ D[7] ^ D[6] ^ D[2] ^
D[1] ^ D[0] ^ C[0] ^ C[1] ^ C[2] ^ C[6] ^ C[7] ^ C[8] ^
C[9] ^ C[13] ^ C[14] ^ C[16] ^ C[17] ^ C[18] ^ C[24] ^
C[26] ^ C[30] ^ C[31];
NewCRC[3] = D[31] ^ D[27] ^ D[25] ^ D[19] ^ D[18] ^ D[17] ^ D[15] ^
D[14] ^ D[10] ^ D[9] ^ D[8] ^ D[7] ^ D[3] ^ D[2] ^
D[1] ^ C[1] ^ C[2] ^ C[3] ^ C[7] ^ C[8] ^ C[9] ^ C[10] ^
C[14] ^ C[15] ^ C[17] ^ C[18] ^ C[19] ^ C[25] ^ C[27] ^
C[31];
NewCRC[4] = D[31] ^ D[30] ^ D[29] ^ D[25] ^ D[24] ^ D[20] ^ D[19] ^
D[18] ^ D[15] ^ D[12] ^ D[11] ^ D[8] ^ D[6] ^ D[4] ^
D[3] ^ D[2] ^ D[0] ^ C[0] ^ C[2] ^ C[3] ^ C[4] ^ C[6] ^
C[8] ^ C[11] ^ C[12] ^ C[15] ^ C[18] ^ C[19] ^ C[20] ^
C[24] ^ C[25] ^ C[29] ^ C[30] ^ C[31];
NewCRC[5] = D[29] ^ D[28] ^ D[24] ^ D[21] ^ D[20] ^ D[19] ^ D[13] ^
D[10] ^ D[7] ^ D[6] ^ D[5] ^ D[4] ^ D[3] ^ D[1] ^ D[0] ^
C[0] ^ C[1] ^ C[3] ^ C[4] ^ C[5] ^ C[6] ^ C[7] ^ C[10] ^
C[13] ^ C[19] ^ C[20] ^ C[21] ^ C[24] ^ C[28] ^ C[29];
NewCRC[6] = D[30] ^ D[29] ^ D[25] ^ D[22] ^ D[21] ^ D[20] ^ D[14] ^
D[11] ^ D[8] ^ D[7] ^ D[6] ^ D[5] ^ D[4] ^ D[2] ^ D[1] ^
C[1] ^ C[2] ^ C[4] ^ C[5] ^ C[6] ^ C[7] ^ C[8] ^ C[11] ^
C[14] ^ C[20] ^ C[21] ^ C[22] ^ C[25] ^ C[29] ^ C[30];
NewCRC[7] = D[29] ^ D[28] ^ D[25] ^ D[24] ^ D[23] ^ D[22] ^ D[21] ^
D[16] ^ D[15] ^ D[10] ^ D[8] ^ D[7] ^ D[5] ^ D[3] ^
D[2] ^ D[0] ^ C[0] ^ C[2] ^ C[3] ^ C[5] ^ C[7] ^ C[8] ^
C[10] ^ C[15] ^ C[16] ^ C[21] ^ C[22] ^ C[23] ^ C[24] ^
C[25] ^ C[28] ^ C[29];
NewCRC[8] = D[31] ^ D[28] ^ D[23] ^ D[22] ^ D[17] ^ D[12] ^ D[11] ^
D[10] ^ D[8] ^ D[4] ^ D[3] ^ D[1] ^ D[0] ^ C[0] ^ C[1] ^
C[3] ^ C[4] ^ C[8] ^ C[10] ^ C[11] ^ C[12] ^ C[17] ^
C[22] ^ C[23] ^ C[28] ^ C[31];
NewCRC[9] = D[29] ^ D[24] ^ D[23] ^ D[18] ^ D[13] ^ D[12] ^ D[11] ^
D[9] ^ D[5] ^ D[4] ^ D[2] ^ D[1] ^ C[1] ^ C[2] ^ C[4] ^
C[5] ^ C[9] ^ C[11] ^ C[12] ^ C[13] ^ C[18] ^ C[23] ^
C[24] ^ C[29];
NewCRC[10] = D[31] ^ D[29] ^ D[28] ^ D[26] ^ D[19] ^ D[16] ^ D[14] ^
D[13] ^ D[9] ^ D[5] ^ D[3] ^ D[2] ^ D[0] ^ C[0] ^ C[2] ^
C[3] ^ C[5] ^ C[9] ^ C[13] ^ C[14] ^ C[16] ^ C[19] ^
C[26] ^ C[28] ^ C[29] ^ C[31];
NewCRC[11] = D[31] ^ D[28] ^ D[27] ^ D[26] ^ D[25] ^ D[24] ^ D[20] ^
D[17] ^ D[16] ^ D[15] ^ D[14] ^ D[12] ^ D[9] ^ D[4] ^
D[3] ^ D[1] ^ D[0] ^ C[0] ^ C[1] ^ C[3] ^ C[4] ^ C[9] ^
C[12] ^ C[14] ^ C[15] ^ C[16] ^ C[17] ^ C[20] ^ C[24] ^
C[25] ^ C[26] ^ C[27] ^ C[28] ^ C[31];
NewCRC[12] = D[31] ^ D[30] ^ D[27] ^ D[24] ^ D[21] ^ D[18] ^ D[17] ^
D[15] ^ D[13] ^ D[12] ^ D[9] ^ D[6] ^ D[5] ^ D[4] ^
D[2] ^ D[1] ^ D[0] ^ C[0] ^ C[1] ^ C[2] ^ C[4] ^ C[5] ^
C[6] ^ C[9] ^ C[12] ^ C[13] ^ C[15] ^ C[17] ^ C[18] ^
C[21] ^ C[24] ^ C[27] ^ C[30] ^ C[31];
NewCRC[13] = D[31] ^ D[28] ^ D[25] ^ D[22] ^ D[19] ^ D[18] ^ D[16] ^
D[14] ^ D[13] ^ D[10] ^ D[7] ^ D[6] ^ D[5] ^ D[3] ^
D[2] ^ D[1] ^ C[1] ^ C[2] ^ C[3] ^ C[5] ^ C[6] ^ C[7] ^
C[10] ^ C[13] ^ C[14] ^ C[16] ^ C[18] ^ C[19] ^ C[22] ^
C[25] ^ C[28] ^ C[31];
NewCRC[14] = D[29] ^ D[26] ^ D[23] ^ D[20] ^ D[19] ^ D[17] ^ D[15] ^
D[14] ^ D[11] ^ D[8] ^ D[7] ^ D[6] ^ D[4] ^ D[3] ^
D[2] ^ C[2] ^ C[3] ^ C[4] ^ C[6] ^ C[7] ^ C[8] ^ C[11] ^
C[14] ^ C[15] ^ C[17] ^ C[19] ^ C[20] ^ C[23] ^ C[26] ^
C[29];
NewCRC[15] = D[30] ^ D[27] ^ D[24] ^ D[21] ^ D[20] ^ D[18] ^ D[16] ^
D[15] ^ D[12] ^ D[9] ^ D[8] ^ D[7] ^ D[5] ^ D[4] ^
D[3] ^ C[3] ^ C[4] ^ C[5] ^ C[7] ^ C[8] ^ C[9] ^ C[12] ^
C[15] ^ C[16] ^ C[18] ^ C[20] ^ C[21] ^ C[24] ^ C[27] ^
C[30];
NewCRC[16] = D[30] ^ D[29] ^ D[26] ^ D[24] ^ D[22] ^ D[21] ^ D[19] ^
D[17] ^ D[13] ^ D[12] ^ D[8] ^ D[5] ^ D[4] ^ D[0] ^
C[0] ^ C[4] ^ C[5] ^ C[8] ^ C[12] ^ C[13] ^ C[17] ^
C[19] ^ C[21] ^ C[22] ^ C[24] ^ C[26] ^ C[29] ^ C[30];
NewCRC[17] = D[31] ^ D[30] ^ D[27] ^ D[25] ^ D[23] ^ D[22] ^ D[20] ^
D[18] ^ D[14] ^ D[13] ^ D[9] ^ D[6] ^ D[5] ^ D[1] ^
C[1] ^ C[5] ^ C[6] ^ C[9] ^ C[13] ^ C[14] ^ C[18] ^
C[20] ^ C[22] ^ C[23] ^ C[25] ^ C[27] ^ C[30] ^ C[31];
NewCRC[18] = D[31] ^ D[28] ^ D[26] ^ D[24] ^ D[23] ^ D[21] ^ D[19] ^
D[15] ^ D[14] ^ D[10] ^ D[7] ^ D[6] ^ D[2] ^ C[2] ^
C[6] ^ C[7] ^ C[10] ^ C[14] ^ C[15] ^ C[19] ^ C[21] ^
C[23] ^ C[24] ^ C[26] ^ C[28] ^ C[31];
NewCRC[19] = D[29] ^ D[27] ^ D[25] ^ D[24] ^ D[22] ^ D[20] ^ D[16] ^
D[15] ^ D[11] ^ D[8] ^ D[7] ^ D[3] ^ C[3] ^ C[7] ^
C[8] ^ C[11] ^ C[15] ^ C[16] ^ C[20] ^ C[22] ^ C[24] ^
C[25] ^ C[27] ^ C[29];
NewCRC[20] = D[30] ^ D[28] ^ D[26] ^ D[25] ^ D[23] ^ D[21] ^ D[17] ^
D[16] ^ D[12] ^ D[9] ^ D[8] ^ D[4] ^ C[4] ^ C[8] ^
C[9] ^ C[12] ^ C[16] ^ C[17] ^ C[21] ^ C[23] ^ C[25] ^
C[26] ^ C[28] ^ C[30];
NewCRC[21] = D[31] ^ D[29] ^ D[27] ^ D[26] ^ D[24] ^ D[22] ^ D[18] ^
D[17] ^ D[13] ^ D[10] ^ D[9] ^ D[5] ^ C[5] ^ C[9] ^
C[10] ^ C[13] ^ C[17] ^ C[18] ^ C[22] ^ C[24] ^ C[26] ^
C[27] ^ C[29] ^ C[31];
NewCRC[22] = D[31] ^ D[29] ^ D[27] ^ D[26] ^ D[24] ^ D[23] ^ D[19] ^
D[18] ^ D[16] ^ D[14] ^ D[12] ^ D[11] ^ D[9] ^ D[0] ^
C[0] ^ C[9] ^ C[11] ^ C[12] ^ C[14] ^ C[16] ^ C[18] ^
C[19] ^ C[23] ^ C[24] ^ C[26] ^ C[27] ^ C[29] ^ C[31];
NewCRC[23] = D[31] ^ D[29] ^ D[27] ^ D[26] ^ D[20] ^ D[19] ^ D[17] ^
D[16] ^ D[15] ^ D[13] ^ D[9] ^ D[6] ^ D[1] ^ D[0] ^
C[0] ^ C[1] ^ C[6] ^ C[9] ^ C[13] ^ C[15] ^ C[16] ^
C[17] ^ C[19] ^ C[20] ^ C[26] ^ C[27] ^ C[29] ^ C[31];
NewCRC[24] = D[30] ^ D[28] ^ D[27] ^ D[21] ^ D[20] ^ D[18] ^ D[17] ^
D[16] ^ D[14] ^ D[10] ^ D[7] ^ D[2] ^ D[1] ^ C[1] ^
C[2] ^ C[7] ^ C[10] ^ C[14] ^ C[16] ^ C[17] ^ C[18] ^
C[20] ^ C[21] ^ C[27] ^ C[28] ^ C[30];
NewCRC[25] = D[31] ^ D[29] ^ D[28] ^ D[22] ^ D[21] ^ D[19] ^ D[18] ^
D[17] ^ D[15] ^ D[11] ^ D[8] ^ D[3] ^ D[2] ^ C[2] ^
C[3] ^ C[8] ^ C[11] ^ C[15] ^ C[17] ^ C[18] ^ C[19] ^
C[21] ^ C[22] ^ C[28] ^ C[29] ^ C[31];
NewCRC[26] = D[31] ^ D[28] ^ D[26] ^ D[25] ^ D[24] ^ D[23] ^ D[22] ^
D[20] ^ D[19] ^ D[18] ^ D[10] ^ D[6] ^ D[4] ^ D[3] ^
D[0] ^ C[0] ^ C[3] ^ C[4] ^ C[6] ^ C[10] ^ C[18] ^
C[19] ^ C[20] ^ C[22] ^ C[23] ^ C[24] ^ C[25] ^ C[26] ^
C[28] ^ C[31];
NewCRC[27] = D[29] ^ D[27] ^ D[26] ^ D[25] ^ D[24] ^ D[23] ^ D[21] ^
D[20] ^ D[19] ^ D[11] ^ D[7] ^ D[5] ^ D[4] ^ D[1] ^
C[1] ^ C[4] ^ C[5] ^ C[7] ^ C[11] ^ C[19] ^ C[20] ^
C[21] ^ C[23] ^ C[24] ^ C[25] ^ C[26] ^ C[27] ^ C[29];
NewCRC[28] = D[30] ^ D[28] ^ D[27] ^ D[26] ^ D[25] ^ D[24] ^ D[22] ^
D[21] ^ D[20] ^ D[12] ^ D[8] ^ D[6] ^ D[5] ^ D[2] ^
C[2] ^ C[5] ^ C[6] ^ C[8] ^ C[12] ^ C[20] ^ C[21] ^
C[22] ^ C[24] ^ C[25] ^ C[26] ^ C[27] ^ C[28] ^ C[30];
NewCRC[29] = D[31] ^ D[29] ^ D[28] ^ D[27] ^ D[26] ^ D[25] ^ D[23] ^
D[22] ^ D[21] ^ D[13] ^ D[9] ^ D[7] ^ D[6] ^ D[3] ^
C[3] ^ C[6] ^ C[7] ^ C[9] ^ C[13] ^ C[21] ^ C[22] ^
C[23] ^ C[25] ^ C[26] ^ C[27] ^ C[28] ^ C[29] ^ C[31];
NewCRC[30] = D[30] ^ D[29] ^ D[28] ^ D[27] ^ D[26] ^ D[24] ^ D[23] ^
D[22] ^ D[14] ^ D[10] ^ D[8] ^ D[7] ^ D[4] ^ C[4] ^
C[7] ^ C[8] ^ C[10] ^ C[14] ^ C[22] ^ C[23] ^ C[24] ^
C[26] ^ C[27] ^ C[28] ^ C[29] ^ C[30];
NewCRC[31] = D[31] ^ D[30] ^ D[29] ^ D[28] ^ D[27] ^ D[25] ^ D[24] ^
D[23] ^ D[15] ^ D[11] ^ D[9] ^ D[8] ^ D[5] ^ C[5] ^
C[8] ^ C[9] ^ C[11] ^ C[15] ^ C[23] ^ C[24] ^ C[25] ^
C[27] ^ C[28] ^ C[29] ^ C[30] ^ C[31];
nextCRC32_D32 = NewCRC;
end
endfunction
endmodule
���ʂł��B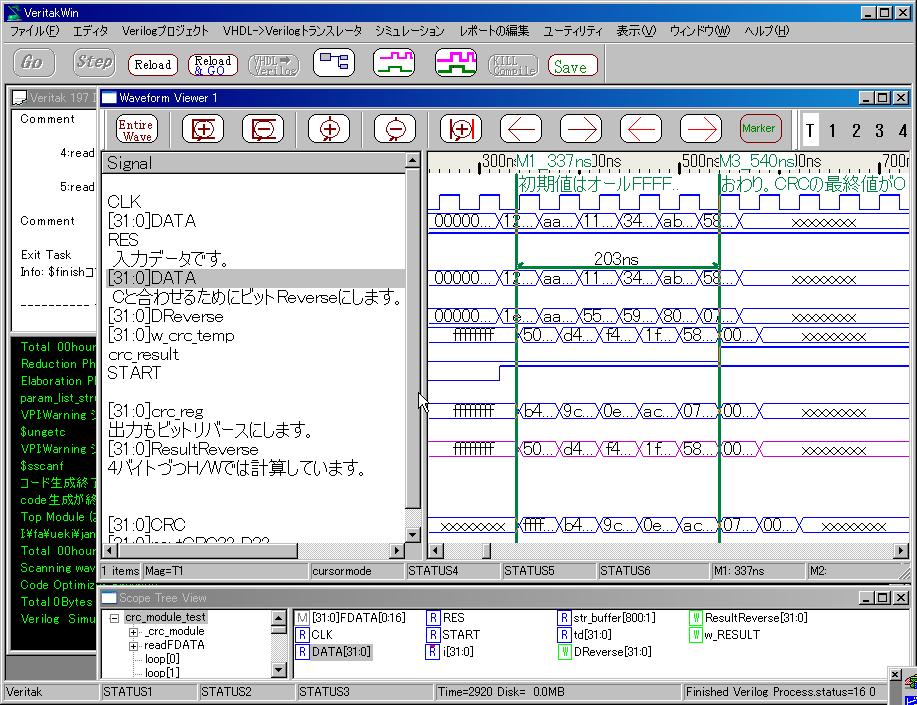
�R���\�[���̏o�͂ł��B
Verilog�̃V�~�����[�V�����̏������������܂����B�X�^�[�g��,Go�{�^���������Ă��������B
------------- �V�~�����[�V�������J�n���܂��B--------------------
Comment �ŏ��̍s�R�����g���v���ȁH
0:read data= 12345678
1:read data= aaaa5555
Comment ����́A�R�����g�s�ł��B�`���ɁG�����邱�ƁB
2:read data= 1111aaaa
3:read data= 3456789a
Comment �@������A�R�����g�s�ł��B
4:read data= abcdef01
5:read data= 58d7e7e0
Comment �Ō�̍s�̃R�����g���v���ȁH
Exit Task
Info: $finish�R�}���h�����s���܂��Btime=1920
---------- �V�~�����[�V�������I�����܂��Btime=1920----------
���ӁFi�Ȃ��A��L�́A�q�e�b�Q�O�W�R�̂���ł́A����܂���B�i�o�͂�INVERTER�������Ă��܂���B�j
32�r�b�gCRC��8�r�b�gData�Ŏg�p�����
�������̕��ɂ���x���`��������������������32�r�b�gCRC8�r�b�g�f�[�^�ł�����Ă݂܂����B
CRC�̃e�X�g�́A���M���Ǝ�M���œ���CRC���g���܂��B�ł��̂ŁA�������W���[���ŃC���X�^���X������悢�ł��B
CRC32_D8_Module #(.initial_value(initial_value),.poly_width(poly_width),.data_width(data_width)) crc_sender_module( clock,
data,sync_reset,hold,
crc_sender);
CRC32_D8_Module #(.initial_value(initial_value),.poly_width(poly_width),.data_width(data_width)) crc_receiver_module( clock,
receive_data,sync_reset,receiver_hold,
crc_receiver);
���M���ł́ACRC�𑗂�Ƃ��́A�������z�[���h���܂��B
for (i=0;i<data_length;i=i+1) begin
data=$random;//�����_���f�[�^��
@(negedge clock);
end
hold=1;//���葤CRC�����z�[���h
for (i=0;i<crc_bytes;i=i+1) begin//CRC�o�C�g��������
data=crc_sender[poly_width-1-data_width*i -:data_width];
@(negedge clock);
end
��M���ł́A�ʏ�̃f�[�^�Ƃ��Ď�M���܂��B��L��ł́A4Byte��CRC��M��A��CRC���O�ɂȂ��Ă��邱�Ƃ��킩��܂��B
�Ȃ��A�㔼�̃e�X�g�ł́A�̈ӂɃG���[�������āACRC���O�ɂȂ�Ȃ����Ƃ��m�F���܂��B�G���[������̂�CRC���O�ɂȂ�P�[�X�͌댟�o�ł��B�댟�o�m���́A�����������Ɉˑ�
���܂��̂ŁA���̃G���[���[�g���ɉ����ēK�Ȑ�����������I������K�v������܂��B
�e�X�g�x���`�ł��B
//Dec.18.2006
module CRC32D8_test_bench;
parameter integer initial_value=-1;
parameter integer poly_width=32;
parameter integer data_width=8;//;
parameter integer maximum_no_of_errors=6;
parameter integer data_length=10;
parameter integer crc_bytes=poly_width/data_width;
reg clock=0;
reg sync_reset=1;
reg hold=0, receiver_hold=0;
wire [poly_width-1:0] crc_sender,crc_receiver;
reg done=0;
integer i,test_loops,error_counter=0;
reg error=0;
reg [data_width-1:0] data=0;
wire [data_width-1:0] receive_data=data^ error;
always #10 clock=~clock;
initial begin
#5;
test_loops=0;
$display("Make sure no CRC error ocrrurs when we don't have error additions.");
//Test 1 Make sure no crc error occurs
repeat (1000) begin
test_loops=test_loops+1;
if (test_loops%100==0) $display("Test Loops=%d",test_loops);
sync_reset=1;
@(negedge clock);
@(negedge clock);
sync_reset=0; hold=0;
for (i=0;i<data_length;i=i+1) begin
data=$random;//�����_���f�[�^��
@(negedge clock);
end
hold=1;//���葤CRC�����z�[���h
for (i=0;i<crc_bytes;i=i+1) begin//CRC�o�C�g��������
data=crc_sender[poly_width-1-data_width*i -:data_width];
@(negedge clock);
end
done=1;
if (crc_receiver !==0) $display("Miss Detection or Programming Error");//CRC���O�łȂ�������v���O�����G���[
@(negedge clock);
done=0;
end
$display("Test Done.!");
//Make sure crc error occurs
$display("Make sure CRC occurs when we have some trivial error additions.");//�̈ӂɃG���[��������e�X�g
test_loops=0;
repeat (1000) begin
test_loops=test_loops+1;
if (test_loops%1000==0) $display("Test Loops=%d",test_loops);
sync_reset=1;
@(negedge clock);
@(negedge clock);
sync_reset=0; hold=0;error_counter=0;
for (i=0;i<data_length;i=i+1) begin
data=$random;//�����_���f�[�^��
if (i==0) begin
error=1;//We add at least one error.
error_counter=error_counter+1;
end else begin//Limit maxinum no of errors
if (error_counter <maximum_no_of_errors) begin
error=$random;//$random error addition
error_counter=error_counter+1;
end
end
@(negedge clock);
end
hold=1;//Stop CRC generation in sender//���葤CRC�����z�[���h
for (i=0;i<crc_bytes;i=i+1) begin//CRC�o�C�g��������
data=crc_sender[poly_width-1-data_width*i -:data_width];
@(negedge clock);
end
done=1;//CRC���O��������v���O�����G���[���댟�o
if (crc_receiver ==0) $display("Miss Error Detection or Programming Error Test Loops=%d",test_loops);
@(negedge clock);
done=0;
end
$display("Test Done.! .... see you again..");
$finish;
end
CRC32_D8_Module #(.initial_value(initial_value),.poly_width(poly_width),.data_width(data_width)) crc_sender_module( clock,
data,sync_reset,hold,
crc_sender);
CRC32_D8_Module #(.initial_value(initial_value),.poly_width(poly_width),.data_width(data_width)) crc_receiver_module( clock,
receive_data,sync_reset,receiver_hold,
crc_receiver);
endmodule
CRC�������W���[���iH/W�j�ł��B
//Dec.18.2006 Tak.S
module CRC32_D8_Module #(parameter integer initial_value=-1, poly_width=32,data_width=8) (input clock,
input [data_width-1:0] data,
input sync_reset,hold,
output reg [poly_width-1:0] crc);
always @(posedge clock) begin
if (sync_reset) crc <=initial_value;
else if (hold) crc <=crc;
else crc<=nextCRC32_D8(data,crc);
end
///////////////////////////////////////////////////////////////////////
// File: CRC32_D8.v
// Date: Mon Dec 18 10:47:11 2006
//
// Copyright (C) 1999-2003 Easics NV.
// This source file may be used and distributed without restriction
// provided that this copyright statement is not removed from the file
// and that any derivative work contains the original copyright notice
// and the associated disclaimer.
//
// THIS SOURCE FILE IS PROVIDED "AS IS" AND WITHOUT ANY EXPRESS
// OR IMPLIED WARRANTIES, INCLUDING, WITHOUT LIMITATION, THE IMPLIED
// WARRANTIES OF MERCHANTIBILITY AND FITNESS FOR A PARTICULAR PURPOSE.
//
// Purpose: Verilog module containing a synthesizable CRC function
// * polynomial: (0 1 2 4 5 7 8 10 11 12 16 22 23 26 32)
// * data width: 8
//
// Info: tools@easics.be
// http://www.easics.com
///////////////////////////////////////////////////////////////////////
// polynomial: (0 1 2 4 5 7 8 10 11 12 16 22 23 26 32)
// data width: 8
// convention: the first serial data bit is D[7]
function [31:0] nextCRC32_D8;
input [7:0] Data;
input [31:0] CRC;
reg [7:0] D;
reg [31:0] C;
reg [31:0] NewCRC;
begin
D = Data;
C = CRC;
NewCRC[0] = D[6] ^ D[0] ^ C[24] ^ C[30];
NewCRC[1] = D[7] ^ D[6] ^ D[1] ^ D[0] ^ C[24] ^ C[25] ^ C[30] ^
C[31];
NewCRC[2] = D[7] ^ D[6] ^ D[2] ^ D[1] ^ D[0] ^ C[24] ^ C[25] ^
C[26] ^ C[30] ^ C[31];
NewCRC[3] = D[7] ^ D[3] ^ D[2] ^ D[1] ^ C[25] ^ C[26] ^ C[27] ^
C[31];
NewCRC[4] = D[6] ^ D[4] ^ D[3] ^ D[2] ^ D[0] ^ C[24] ^ C[26] ^
C[27] ^ C[28] ^ C[30];
NewCRC[5] = D[7] ^ D[6] ^ D[5] ^ D[4] ^ D[3] ^ D[1] ^ D[0] ^ C[24] ^
C[25] ^ C[27] ^ C[28] ^ C[29] ^ C[30] ^ C[31];
NewCRC[6] = D[7] ^ D[6] ^ D[5] ^ D[4] ^ D[2] ^ D[1] ^ C[25] ^ C[26] ^
C[28] ^ C[29] ^ C[30] ^ C[31];
NewCRC[7] = D[7] ^ D[5] ^ D[3] ^ D[2] ^ D[0] ^ C[24] ^ C[26] ^
C[27] ^ C[29] ^ C[31];
NewCRC[8] = D[4] ^ D[3] ^ D[1] ^ D[0] ^ C[0] ^ C[24] ^ C[25] ^
C[27] ^ C[28];
NewCRC[9] = D[5] ^ D[4] ^ D[2] ^ D[1] ^ C[1] ^ C[25] ^ C[26] ^
C[28] ^ C[29];
NewCRC[10] = D[5] ^ D[3] ^ D[2] ^ D[0] ^ C[2] ^ C[24] ^ C[26] ^
C[27] ^ C[29];
NewCRC[11] = D[4] ^ D[3] ^ D[1] ^ D[0] ^ C[3] ^ C[24] ^ C[25] ^
C[27] ^ C[28];
NewCRC[12] = D[6] ^ D[5] ^ D[4] ^ D[2] ^ D[1] ^ D[0] ^ C[4] ^ C[24] ^
C[25] ^ C[26] ^ C[28] ^ C[29] ^ C[30];
NewCRC[13] = D[7] ^ D[6] ^ D[5] ^ D[3] ^ D[2] ^ D[1] ^ C[5] ^ C[25] ^
C[26] ^ C[27] ^ C[29] ^ C[30] ^ C[31];
NewCRC[14] = D[7] ^ D[6] ^ D[4] ^ D[3] ^ D[2] ^ C[6] ^ C[26] ^ C[27] ^
C[28] ^ C[30] ^ C[31];
NewCRC[15] = D[7] ^ D[5] ^ D[4] ^ D[3] ^ C[7] ^ C[27] ^ C[28] ^
C[29] ^ C[31];
NewCRC[16] = D[5] ^ D[4] ^ D[0] ^ C[8] ^ C[24] ^ C[28] ^ C[29];
NewCRC[17] = D[6] ^ D[5] ^ D[1] ^ C[9] ^ C[25] ^ C[29] ^ C[30];
NewCRC[18] = D[7] ^ D[6] ^ D[2] ^ C[10] ^ C[26] ^ C[30] ^ C[31];
NewCRC[19] = D[7] ^ D[3] ^ C[11] ^ C[27] ^ C[31];
NewCRC[20] = D[4] ^ C[12] ^ C[28];
NewCRC[21] = D[5] ^ C[13] ^ C[29];
NewCRC[22] = D[0] ^ C[14] ^ C[24];
NewCRC[23] = D[6] ^ D[1] ^ D[0] ^ C[15] ^ C[24] ^ C[25] ^ C[30];
NewCRC[24] = D[7] ^ D[2] ^ D[1] ^ C[16] ^ C[25] ^ C[26] ^ C[31];
NewCRC[25] = D[3] ^ D[2] ^ C[17] ^ C[26] ^ C[27];
NewCRC[26] = D[6] ^ D[4] ^ D[3] ^ D[0] ^ C[18] ^ C[24] ^ C[27] ^
C[28] ^ C[30];
NewCRC[27] = D[7] ^ D[5] ^ D[4] ^ D[1] ^ C[19] ^ C[25] ^ C[28] ^
C[29] ^ C[31];
NewCRC[28] = D[6] ^ D[5] ^ D[2] ^ C[20] ^ C[26] ^ C[29] ^ C[30];
NewCRC[29] = D[7] ^ D[6] ^ D[3] ^ C[21] ^ C[27] ^ C[30] ^ C[31];
NewCRC[30] = D[7] ^ D[4] ^ C[22] ^ C[28] ^ C[31];
NewCRC[31] = D[5] ^ C[23] ^ C[29];
nextCRC32_D8 = NewCRC;
end
endfunction
endmodule
F.A.Q.Q.MSB��LSB�����ւ��E�@�r�b�g�ɐ��ɂ���
�������\�[�X�ƃe�X�g�x���`�ł�������
�V���~���[�V�������Ă݂܂���
��͂�@����CRC��MSB��LSB�̔��]�@�Ƌɐ��̔��]���N���܂�
���s���܂�����
�ŏ���DATA�@0x24�ɑ��ā@�g�`��ŏo�͂����CRC��
�@�hC52F7F88"�ł���
�t���[�̃\�t�g��CRC�R�Q�̌v�Z�\�t�g�Ōv�Z�������
�@�hEE010B5C"�ƂȂ�܂���
2��ނ̃t���[�\�t�g�Ŏ����Ă݂܂������@�������ʂł���
�@�hC52F7F88"���@MSB��LSB�����ւ��ā@�r�b�g�ɐ��]�������
�@�hEE010B5C"�ƂȂ�܂�
�Ȃɂ��������Ⴂ���Ă���̂ł��傤���H
A.����́ACRC�̗��p�̒�`�Ɉˑ����܂�
�{���I�Ȃ̂́A�����������ŁA���ꂾ���Ō댟�o�m�������肵�܂��B
CRC�����l��AINV�⏇����ς��Ă��A���������������Ȃ�A�댟�o�m���͕ς��܂���B
�܂�A���M�Ǝ�M��Closed�������E�i���CRC��AHDD�������j�ł́ACRC�����l/INV/������ς��Ē�`���ĂȂ��댟�o�m���͕ς��܂���B
���p����Ƃ��̃v���g�R���̖��ł��B
���ɑ��M����M���̏��������܂��Ă���ꍇ�iEthernet/CD/FDD/DVD��CRC�Ƃ��j�́ACRC�����l�͂�����ɂ���Ƃ��AINV����Ƃ�MSB�������邩LSB�������邩�A
�����́A���̃v���g�R��Spec.�̂Ȃ��Œ�`���Ă���͂��ł�����A����ɂ��킹���ޕK�v������܂��B�i���ʓI�ɂ����l������Ă����Ƃł��j
�łȂ��ƁA�܂���CRC�G���[�ɂȂ��Ă��܂��܂��ˁB�ܘ_�e�X�g�x���`�́A���̏ꍇ�A���̃v���g�R���ɉ����`�ɂ���ׂ��ł��傤�B
�A�i���OPLL�̃V�~�����[�V�����iMay.7.2005�@�I���j
��̌ÓT�I�ȃf�U�C�����s���Ă݂܂����B
���[�h�\�����������v���O�����̎����@�iUnder�@Development�j
���[�h�\�������́ACD��DVD�Ŏg���Ă���������iECC�j�̈��ł��B5�N�ʑO�̃n�[�h�f�B�X�N�̃e�N�m���W�[�ł́A5�C���^�[���[�u�̂�3�d�����iCPU�x���`�}�[�N�Ŏ��グ�܂����B�j���g���Ă��܂����B�iCD�͂Q�d�����܂łł��B�j�@
���[�h�\�������́A�����������R���܂łȂ�A��r�I�ȒP�ȑ㐔�������ō����ɉ������Ƃ��ł��܂��B�i�Ȃ̂ŁACD�EDVD�EHardDisk�ł̓C���^�[���[�u���g���ăo�[�X�g�G���[�\�͂��グ�Ă܂��B�j
�R���ȉ��ł́ACPU�x���`�}�[�N�Ɏ������㐔��@��(3���������̈�ʉ��F�J���_�m�̌����j�ŁA����ȏ�ł́A�T���ɂ����@�i5���ȏ�̑㐔�������̈�ʉ������݂��Ȃ��悤�Ɂj�A�ȉ��̎���Verilog����ʓI���Ǝv���܂��B
�K���A�̏�̏揜�Z�́ACPU�ł͕\�����ɂȂ�̂ŁA�������̂��߂ɂ́A�n�[�h�E�F�A�ʼn��Z����̂���ʓI�ł����B�i2�����o�[�R�[�h�悤�ɒᑬ�ł悢�ꍇ�ɂ́A���݂ł��\�t�g�E�F�A�ʼn\�ł��B�j
����A�g�ݍ���CPU���A���R���t�B�O�A�u���ɂȂ��Ă���ƁA�K���A�̂�ALU�����āA���ߒlj�����CPU�ōs����ʂ������Ȃ��Ă���ł��傤�B
SourceForge�ŁAVerilog�������o�͂��Ă����v���O�����������܂����B�ȒP�ɂł���悤�Ȃ�A�������Ă݂����Ǝv���܂��B
=>�e�X�g�x���`��f���Ă���Ȃ��̂ŁA�����ō��Ȃ���Ȃ�܂���B�R�[�h�́A����Ȃ�ɓf���݂����ł��BErasure�́A�T�|�[�g����Ă��܂��A�X�V�����Ă���悤�ł��B
�Ƃ肠�����AVC++�ŃR���p�C�������o�C�i�������Ă����܂��B�@CD�Ŏg���Ă��鐶���������ŁA�ڑ�H/W�ƃe�X�g�x���`����������ł������A���̃R���e�X�g�̖��Ŏ��Ԃ��Ȃ��Ȃ��Ă��܂��܂����B
�@
�@
�f�U�C���E�F�[�u�@�R���e�X�g�Q�O�O�T������(�I���j
�@FM���V�[�o�̖��ł��B�܂��A�^��Ɏv���̂́A�v�d�l�̞B���ȂƂ���ł��B���M�g�`�̑ш搧���i�X�y�N�g�������`�j�́A�ǂ��Ȃ��Ă���̂ł��傤���H�@��M�t�B���^�̍œK���v�ɂ����ẮA�K�v���Ǝv���̂ł����B�@
����ɁA�O�p�g�́A�����ш�����B�B�B
�@�Ƃ肠�����ADPLL�̎�����Ƃ��ẮA�ʔ����ۑ肾�Ǝv���̂ŁA���g��ł݂����Ǝv���܂��B�R���e�X�g��HP�����܂������A���ʂŐv����Ă���\�[�X�iVerilog/VHDL�j�͂Ȃ��悤�ł��B
�����ŁA���ʂŐ�������Ă���v�́i���Ƃ��ẮjVeritak�v���W�F�N�g���쐬���X��}��낤�Ǝv�����̂ł����A������DPLL����ARCTAN�Ɉڂ��Ă��܂��܂����B�j
�@=>
�@�����A�������Ă݂܂����B����́ADPLL�Ƃ��čl������FSK�Ƃ��čl���������悳�����ł��B
�@�m���ɁA�ʑ������b�N����A���g������͂Ȃ��̂ŁA�m���Ɏ��g���ω��𑨂��邱�Ƃ��ł��܂��B�������A�v�́A���g���ω������ʑ��̕ω���������悢��ŁA�K������PLL�ɂ������K�v�͂Ȃ��ł��傤�B
�\�t�g�E�F�A�����I�ȍl���ŁA���@�\��_�������A�n�[�h�E�F�A�iFPGA)�ɂ����ł��Ȃ����Ɓi���̂����A�\�t�g�E�F�A�ŏo���Ă��܂��̂����̐��E�̏�ł����B�j�A���Ȃ킿�X�s�[�h�ōő���_���v�����Ă݂����Ǝv���܂��B
�@����ɂ��Ă�S/N�����Ă悢�̂��ǂ����ŁA�܂������v���قȂ��Ă��܂��܂��B���p�����������R���e�X�g�ۑ�Ƒ����邩�A������x�A���g�p�ɑς�����v�Ƃ��邩�Y�݂ǂ���ł��ˁB
=>
�@���Ȃ茟��(�x����AM)���Ă݂܂����B�P������DWM���@�����F�ꎁ�̉���ɂ���ʂ�A��͂�PLL�̃A�v���[�`�́A���ړI�ł͂���܂���B
�����ŁA�����I��ł����A
- �p���X�J�E���g�@
- �ʑ����ڌv�Z
- Quadrature
�i�A�i���O�ł́AQuadrature�ɂ����@����ʓI�ŁA���ہA�M�҂�2.4GHz��110MHz��IF�ɗ��Ƃ�����A����Őv�������Ƃ�����܂����B�j
�����Ȃ�ƁA�ŏI�I�ɂ́A���̖��̃L�[�|�C���g�́AARCTAN�������Ɍv�Z���邩���Ǝv���܂��B
ARCTAN�̌v�Z�́ACORDIC��{�e�[���W�J���A����ނ̌v�Z���@������܂��B
=>
�@�O�p���̌������Ђ��ς肾���Ă���Ɍ������܂����B�i�x����PM,�@���ς���������Y��Ă��܂����B�j�@�ʂȎ��_����悢���@���v�����܂����BS/N������A���̏�ł́A���܂����������ȑ����V�����A���S���Y���ł��B
�Ƃ肠�����ANET��Search�����_���Ŏ�����́A����܂���ł����BSpartan3�i1�����t�^�j��260MH���ʍs�������ł��B�܂��A���̂��߂�H/W�iPIC����������)���]�T�ōڂ�ł��傤�B
��́A
- �V�X�e���Ƃ��Ẵ��f���V�~�����[�V�����iMATALB�ł͋L�q���Ȃ��ŁAVerilog�ł̃V�X�e�����f�����O(real�A$rungekutta�����g���܂��j�j -16��
- �f�W�^���t�B���^�v�iT.B.D.�@) -4h
- Verilog�ɂ��H/W�L�q �@-4h
- Verilog�@RTL�V�~�����[�V�����@-8h
- ���ؗp���ӋL�q�A�e�X�g�L�q�@-24h
- Xilinx�p�L�q�Ƀ}�b�s���O�@-2h
- Xlinx�_�������@�@-2h
- Xlinx�@�|�X�g���C�A�E�g�V�~�����[�V�����@-8h
- FPGA�@���@���i�t�^��FPGA�����Ƃ������������ɔ����Ă��܂��悤�ł����A����͊m�ۍς݂ł��B�j�@�|�W��
- ���|�[�g�쐬�@�@�|12��
=>�v���j�����߂܂����B
- �ۑ�P�Ɏ��g��(1/�|�P�j�A�f�W�^��FSK�Ə���ɉ���
- �ۑ���ȉ��̒ʂ菟��ɉ���
�@�@�@�������@18�r�b�gx1KWORDx4=>2x1Kx4�̃T���v������=>8KB�̃f�[�^�����[�\=>�x�[�X�o���h��60���͓���B=>�A�C�͉\
- �x�[�X�o���h�ő��i5MBPS��300MHzCLOCK��)�ƍŏ�LUT�i300LUT)����ڎw���B
- CP�́A�W���W�����t��Z��1��=>Xilinx�����͎g�킸�p�C�v���C����(YACC�̏�Z���8�r�b�g�x�[�X�ɕύX�j
- CPU�͍ڂ����ɁA���ӋL�q���Ԃ��ŏ��ɂ���B�X�^�[�g=>�������_���v=>Excel�����ł悢�B
�@
�@���̂܂܁A�A���S���Y�����j�]���Ȃ��悤��������AVerilog��ł̃V�~�����[�V�����́A�V�X�e��/RTL/�Q�[�g��3��s�����ƂɂȂ�܂��B���ۂ����̐v�ɗ��Ƃ��Ă����g�b�v�_�E���v��@�̂悢��ɂȂ��Ă���i�����H�j�Ǝv���̂ŁA
���ۂɐv�A���삵�Ă��������Ǝv���܂��B�܂��ARTL�V�~�����[�V�����܂ōs���āA�s�������������炻�̂܂܉��債�Ă݂����Ǝv���܂��B
=>�V�X�e���V�~�����[�V����
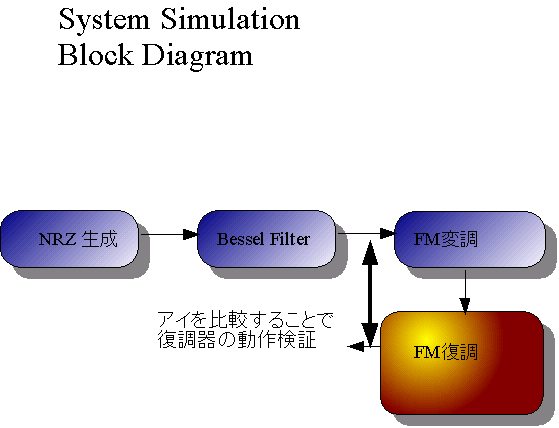
�@1)���M�g�`�̍쐬
�@ �x�[�X�o���h�̃����_��NRZ�g�`���쐬���܂��B����́A$random�@%2��OK�ł��傤�B�i$random�́AVerilog2001�d�l�ł́A����Seq.�̃V�~�����[�^�݊�������܂��B�j�@������A�K�E�X�t�B���^�i�A�i���O�x�b�Z���T���ŋߎ��j�ɒʂ��܂��B�@
FIR�ł��L�q�ł��܂����AVeritak�̏ꍇ�A$rungekutta���g����̂ŁA������̕����ȒP�ł��B
���ɁAFSK�ϒ��ł����Af(t)��ϒ���̔g�`�Ƃ���ƁA�u���I�ɂ́A
�@�@f(t)=sin(�ւ��j�ł�����A
�@�@�ց���c+��b
�����ŁA�ւ��́A�L�����A�A�ւ��́A�x�[�X�o���h��VCO�̊p���x�ɂȂ�܂��B
�Ƃ��낪�A�ւ��͕ω�����̂ŁA��̐ϕ����삪�K�v�ɂȂ�܂��B
�x�[�X�o���h��VCO�́A�K�E�X�t�B���^�̏o�͂ɕϒ��x1%����Z�������̂ɂ����OK�ł��B�ȏ�̎������̂܂܁AVerilog�ŏ����A���M�g�`�̏o���オ��ł��BMATLAB���݂ɐ��\�s�ŏ����Ă��܂��Ƃ��낪Verilog�̂����Ƃ���ł��B
�@
�@�Ƃ���ŁAGFSK�́ADECT�EGSM�EBluetooth�Ŏg���Ă���A���j�̂���ϒ������ł��BBluetooth�ł́AFH�̃e�N�j�b�N�ŁA2.4GHz ISM��79Channel�Ɋg�U����܂��B
�ۑ�́A�A�i���O��z�肵�Ă���݂����ł����A����������Digital�ϕ����ɂ��Č������Ă��ʔ����̂ł͂Ȃ��ł��傤���H
�@
Verilog2001�X�^�C���ŏ����Ă݂܂����B�@
����́A�ŏI�I�ȃ\�[�X���X�g�ł��B�@Xilinx�@Coregen�Ő����������̈ȊO�́A�����uart�\�[�X(���j���S�Ăł��B
//Jan.27.2005 Refine 2
//Jan.21.2005 Refine
//Jan.19.2005 �ŏI�Ł@Baseband/Demodulator��Eye�@����
// Coe FILE�@����
`timescale 1ps/1ps
module hard_test_bench;
//Hard �p�����[�^
parameter INPUT_DATA_MSB=7;
parameter HOST_DATA_MSB=((INPUT_DATA_MSB+1)*2-1);
parameter OUTPUT_DATA_MSB=11;
parameter ADDRESS_MSB=11;
//�e�X�g�x���`�p�����[�^
parameter real Freq =150e6*1000/999;//150MHz Carrior Frequency
parameter real Modulation =0.01;// +-1% GFSK Modulation
parameter integer Clock_Period=10;//10ps 10ps resolution test bench
parameter File_Name="bessel5.txt";//System Matrix A,B,C,D file for bessl filter
// 3dB cutoff=5MHz
parameter integer Filter_Degree= 5;//System Matrix 's Degree
parameter integer CYCLE=Clock_Period*3*333 ;//
parameter integer BasebandCycle=1000*100/(Clock_Period*2);//10Mbps
localparam integer Item_Counter_Max=2048*2-1;//4KB
parameter integer IQ_Delay=1667;//90Degree shift at 150MHz
parameter integer HOLD_TIME=1;
real fc;//Carrier Frequency
real fb;//BaseBand Frequency
real fm;//Modulated Frequency
//rungekutta systems matrix input/output array
real read_array[0:10];// Input vector for rungekutta
real write_array[0:10];//Output vector from rugekutta
real t;
reg clock=0;
reg signed [11:0] filt_out;//for monitoring
real filt_outr;
reg sync_reset1,sync_reset;
real modulated_waveform;//�ϒ��g�`
reg signed [INPUT_DATA_MSB:0] demodulator_input;//�Wx2�r�b�g�T���v�����O�M��
//�@������̓��͂ɂȂ�
real theta,delta_theta,omega;//Dec.22.2004
wire NRZ;//Baseband NRZ
wire TXD;//UART �o��
wire signed [OUTPUT_DATA_MSB:0] demodulated_wave;//������o��Data
integer fp=0;
//Hardware IF Signals
reg clk=0;
reg RST_In;
reg [ADDRESS_MSB:0] HOST_ADDRESS=0;
reg [HOST_DATA_MSB:0] HOST_DATA=0;
reg HOST_WRITE_ENABLE=0;
wire CLKFX_OUT;
wire dcm_clock=CLKFX_OUT;//150MHz FPGA output CLOCK
wire delayed_clock;
wire HOST_WRITE_CLOCK;
//�V�X�e���V�~�����[�V�����p
real cos_real,sin_real;
real cos_real_z1,sin_real_z1;
real diff_real;
integer mag;
assign #(HOLD_TIME) HOST_WRITE_CLOCK=delayed_clock;//RTL �V�~�����[�V�������A
//HOST��IQ��Write���邽�߂̃N���b�N
assign #(IQ_Delay) delayed_clock = dcm_clock;//CLKFX_OUT;//CLKFX_OUT��90 �x
//�V�t�g����150MHz�@�N���b�N
//�e�X�g�x���`�N���b�N�@�x�b�Z���t�B���^�̎��ԉ����v�Z�Ɏg�p����̂ŁA�\���ׂ�������
//DCM�ɒ[�����łȂ��悤��3�̔{��(150/50)�Ƃ��邱�ƁB�����łȂ��ƃW�b�^����������
always #Clock_Period clock=~clock;
//FPGA�V�X�e���N���b�N 50MHz Starter�@Kit�d�l
always #(CYCLE) clk=~clk;
//NRZ ���x�b�Z���t�B���^�̎��ԉ������v�Z����B
//
//`define USE_ROM_DATA //ROM DATA���g���Ȃ炱���ON�ɂ���
`ifndef USE_ROM_DATA //ROM DATA ���g��Ȃ��ꍇ�ANRZ��著�M�ϒ��g���쐬����
//�@ROM�@DATA���g���ꍇ�́ASIM���ԒZ�k�̂���
//�ȉ��͎��s���Ȃ�
always @( clock) begin//Jan.19.2005
t=$time()*1e-12;
read_array[0]=(NRZ==1 ? 1 :-1);//1/0 => 1/-1 �Ƀ}�b�s���O
$runge_kutta(File_Name,1);//�A�i���O�V�~�����[�^�ŁA�x�b�Z���t�B���^�o�͌v�Z
filt_outr=write_array[Filter_Degree-1];//�o�͂�REAL�œ���@Get filtered outout
filt_out=$rtoi($rint(filt_outr*1023));//�t�B���^�o�͂̃��j�^�p
fc=Freq;
fb=Freq*Modulation*filt_outr;
fm=fc+fb;
omega=2.0*fm*$M_PI;
delta_theta=(Clock_Period)*1e-12*omega;//Jan.19.2005
theta=theta+delta_theta;
modulated_waveform=$sin(theta);//�ϒ��������M�g�@150MHz
//�ʎq�������A�ϒ��������M�g�@150MHz�I�[�o�t���[�l���A�l�̌ܓ���A�����ϊ�
demodulator_input=$rtoi($rint(modulated_waveform*( 2**INPUT_DATA_MSB -1.0)));
end
`else
`endif
//coe file ����
//`define MAKE_COE_FILE // XILINX�@RAM�@�������t�@�C������������Ȃ�ON
`ifdef MAKE_COE_FILE
initial begin
fp=$fopen("modulator_out.coe","w");
$fwrite(fp,"memory_initialization_radix=16;\n");
$fwrite(fp,"memory_initialization_vector=\n");
end
`endif
integer item_counter=0;
integer dcm_instead_counter=0;
integer cos_monitor;
always @(posedge dcm_clock) begin//cos �G�b�W
#1;
HOST_DATA[INPUT_DATA_MSB:0]=demodulator_input;//Set LSB WORD
cos_real_z1=cos_real;
cos_real=modulated_waveform;
cos_monitor=$rtoi(1000*cos_real);
end
always @(posedge delayed_clock) begin//sin �G�b�W
#1;
HOST_DATA[HOST_DATA_MSB: INPUT_DATA_MSB+1]=demodulator_input;
//Set MSB WORD
if (!HOST_WRITE_ENABLE) HOST_ADDRESS=0;//�ŏ��͂O
else HOST_ADDRESS=HOST_ADDRESS+1;
//������C���N�������g
HOST_WRITE_ENABLE=1;//Write Start
sin_real_z1=sin_real;
sin_real=modulated_waveform;
diff_real=cos_real*sin_real_z1 -sin_real*cos_real_z1;
diff_real=diff_real*1023*16;
mag=$rtoi(diff_real);
`ifdef MAKE_COE_FILE // XILINX�@RAM�@�������t�@�C������������Ȃ�
if (item_counter==Item_Counter_Max) begin//RAM �ŏI�A�h���X�܂ŏ�������
//�I���
$fwrite(fp,"%4h;\n",HOST_DATA);
$fclose(fp);
$finish;
end else begin
$fwrite(fp,"%4h,\n",HOST_DATA);
end
`endif
item_counter=item_counter+1;
end
//NRZ ����
baseband #(.counter_max(BasebandCycle)) base(clock,NRZ);//NRZ ����
//�A�C�p�^�[������
`define EYE_BASEBAND //�x�[�X�o���h�̃A�C�p�^�[��������Ƃ��@�����ON
`define EYE_DEMODULATOR //������o�͂̃A�C�p�^�[��������Ƃ��@�����ON
`ifdef EYE_BASEBAND
eye_monitor #(.samples_per_scan(15*2*2),.max_columns(32)
,.Eye_Save_Data_File("eye_base.txt")) eye_base(dcm_clock,filt_out);
`endif
`ifdef EYE_DEMODULATOR
eye_monitor #(.samples_per_scan(15*2*2),.max_columns(32)) eye_demo(dcm_clock,mag);
//mag,demodulated_wave
`endif
//Reset
initial begin
$runge_kutta(File_Name,0,read_array,write_array);//�A�i���O�V�~�����[�^
//�̃I�u�W�F�N�g������
RST_In=0;
#(10*1000);
RST_In=1;
#(100*1000);
RST_In=0;
end
//������
hardware #( .INPUT_DATA_MSB(INPUT_DATA_MSB),
.HOST_DATA_MSB(HOST_DATA_MSB),
.ADDRESS_MSB(ADDRESS_MSB),
.OUTPUT_DATA_MSB(OUTPUT_DATA_MSB) )
dut ( .RST_In(RST_In),//Reset
. CLKIN_IN(clk),//FPGA ����CLOCK=50MH��
. HOST_CLK(HOST_WRITE_CLOCK),// ������RAM��Write�@����CLOCK
. HOST_ADDRESS(HOST_ADDRESS),//��������́@RAM�@Address�w��
. HOST_WRITE_ENABLE(HOST_WRITE_ENABLE),//���������Write
.HOST_DATA(HOST_DATA), // ���������Data
.output_data(demodulated_wave), //������o��Data
.CLKFX_OUT(CLKFX_OUT),//150MHz FPGA �o��
.TXD(TXD));//UART �o�́@115.2Kbps
//uart read port
wire [7:0] buffer_reg;
wire int_req;
localparam LF=8'h0d;//���s�R�[�h
always @(posedge clk, posedge RST_In) begin
if (RST_In) sync_reset <=1'b1;
else sync_reset<=1'b0;
end
//`define READ_GENERATED_UART_DATA //FPGA�@UART����̃f�[�^��TEXT�@Save
//=>uart.txt
//RTL �ƃR���y�A���Ƃ�ꍇ�́A�R�����g���g��
`ifdef READ_GENERATED_UART_DATA
parameter uart_file="uart.txt";//���@���o�͂���UART�@�e�L�X�g�t�@�C��
reg [OUTPUT_DATA_MSB:0] uart_mem [0 :4096*2-1];//���@�̃f�[�^�ێ�������
reg signed [OUTPUT_DATA_MSB:0] uart_output;//���������e����������o��
reg [ADDRESS_MSB+1:0] uart_mem_address=-(13'h100a-13'h0c70);
//���ꗬ��UART�@DATA�̒����l
initial begin
$readmemh(uart_file,uart_mem);//uart_mem �ɓǂݍ��f�[�^���i�[
end
always @* uart_output=uart_mem[uart_mem_address];//150MHz�@�N���b�N����
always @(posedge CLKFX_OUT) uart_mem_address<=uart_mem_address+1;//
`endif
uart_read uart_read_port( .sync_reset(sync_reset), .clk(clk)
, .rxd(TXD),.buffer_reg(buffer_reg), .int_req(int_req));//���@��TX port �̃e�X�g�p�Ƃ���
//UART ����̃f�[�^��12'h������CR�ŕ\������
always @(posedge int_req) begin
begin :local
reg [7:0] local_mem [0:3];
integer i=0;
if (i>=4) $stop;//Assert(0);
if (buffer_reg==LF) begin :local2 //pop stack
integer j;
j=0;
while( j < i) begin
$write( "%c",local_mem[j]);
j=j+1;
end
$write(" : time=%t\n",$time);
i=0;//clear stack
end else begin//push stack
local_mem[i]=buffer_reg;
i=i+1;
end
end
end
endmodule
//�����_��NRZ������
module baseband
#(parameter counter_max=1000)
(
input clock,
output reg NRZ=1
);
localparam integer MAX=counter_max-1;
localparam integer initial_value_counts=4;//�ŏ��́ABessel�������
localparam integer finish_value_counts=counter_max-5;//�Ō���P�ɂ��Ă��邪�A
//�ʑ��������Ă��Ȃ��̂ŁAWrap����Noise���ł�B
reg [15:0] counter=0;
reg [15:0] baseband_counter=0;
always @(posedge clock) begin
if (counter==MAX) counter<=0;//10Mbps counter
else counter<=counter+1;
end
always @(posedge clock) begin
if (counter==MAX) begin
baseband_counter <=baseband_counter+1;
if ( baseband_counter <=initial_value_counts ||
baseband_counter >=finish_value_counts) NRZ<=1;
else NRZ<=$random %2==1;//�����_���@10Mbps NRZ
end
end
endmodule
//�A�C�p�^�[�������BEXCEL �ǂݍ��ݗp�̃R���}�Z�p���[�g�@�e�L�X�g�t�@�C��������
//EXCEL�ǂݍ��ݎ��ɁA�R���} ���w�肷�邱�ƁB
module eye_monitor #(parameter samples_per_scan=32,//�s��
max_columns=64,//��
Eye_Save_Data_File="eye_demo.txt" //�t�@�C����
)
(
input clock,
input signed [11:0] baseband_out
);
integer sample_counter=0;
integer column_counter=0;
integer fi;
integer i,j;
reg [11:0] saved_wave [0:samples_per_scan][0:max_columns];
always @(posedge clock) begin
saved_wave[sample_counter][column_counter] =baseband_out;
if (sample_counter==samples_per_scan-1) begin
sample_counter<=0;
column_counter<=column_counter+1;
if (column_counter==max_columns) begin
save_data_to_file;
$stop;
end
end else sample_counter <=sample_counter+1;
end
task save_data_to_file;
begin
fi=$fopen(Eye_Save_Data_File);
for (i=0;i<samples_per_scan;i=i+1) begin
for (j=0;j< max_columns;j=j+1) begin
if (j==0) $fwrite(fi,"%d ",$signed(saved_wave[i][j]));
else if (j==max_columns-1) $fdisplay(fi,", %d ",$signed(saved_wave[i][j]));
else $fwrite(fi,",%d",$signed(saved_wave[i][j]));
end
end
$fclose(fi);
end
endtask
endmodule
//Jan.27.2005 Refine
//FPGA ��H�L�q���W���[��
//RTL �V�~�����[�V�������́AHOST����IQ�����炤�@�A�����o��12�r�b�g150MHz
//���@�ł́A����ROM�ɂ��IQ���@UART�@115.2Kbps �ŁARAM��Save���ꂽ�����o�͂��o��
//
module hardware #(parameter INPUT_DATA_MSB=7,
parameter HOST_DATA_MSB=(INPUT_DATA_MSB+1)*2-1,
parameter ADDRESS_MSB=11,
parameter OUTPUT_DATA_MSB=11 )
( input RST_In,
input CLKIN_IN,
input HOST_CLK,
input [ADDRESS_MSB :0] HOST_ADDRESS,
input HOST_WRITE_ENABLE,
input [HOST_DATA_MSB :0] HOST_DATA,
output signed [OUTPUT_DATA_MSB :0] output_data,
output CLKFX_OUT,
output TXD);
reg [ADDRESS_MSB:0] address,address_d,address_dup1,address_dup2,address_dup3,address_dup4,address_dup5;
wire signed [INPUT_DATA_MSB:0] data_in1,data_in2;
//uart
wire [ADDRESS_MSB:0] address_for_uart;
reg sync_reset_uart;
wire clk0;
wire signed [OUTPUT_DATA_MSB:0] demodulated_wave_final;
//XilinX DCM���W���[���F 50MHz �V�X�e���N���b�N����́@=>150MHz���o��
mydcm dcm(.CLKIN_IN(CLKIN_IN),
.RST_IN(RST_In),
.CLKFX_OUT(CLKFX_OUT),
.CLKIN_IBUFG_OUT(),
.CLK0_OUT(clk0),
.LOCKED_OUT());
//�����탂�W���[���F 150MHz�@�N���b�N�ŁAI/Q����́A=>�����o�͂�12�r�b�g���ŏo��
demodulator_hardware_new_sampling #(.Demo_MSB(INPUT_DATA_MSB)) demodulator(
.dcm_clock(CLKFX_OUT),//
.async_reset(RST_In),
.modulated_wave_sin(data_in1),//
.modulated_wave_cos(data_in2),//
.demodulated_wave_final(demodulated_wave_final));//
//Dual Port���W���[���F1�Q�r�b�g���SKWords
//�����o��Save�̂��߂�Dual Port RAM ���͂́A�����o�́i�P�Q�r�b�g���j=> �o�͂́A
//UART�ɏo�͂��Ȃ��̂Ȃ�ARTL�V�~�����[�V�����p��150MHz�ŕ����o�͂��o��
//UART�I�����́AUART_CNTRL�́A�A�h���X�𐧌䂷��
//`define UART_TX_OUTPUT
`ifndef UART_TX_OUTPUT //UART ���g��Ȃ��̂Ȃ�
dualram dual_portram(
.addra(address_dup4),
.addrb(address_dup5),
.clka(CLKFX_OUT),
.clkb(CLKFX_OUT),
.dina(demodulated_wave_final),
.dinb(),
.douta(),
.doutb(output_data),
.wea(1'b1),//Jan.23.2005
.web(1'b0)); // synthesis black_box
`else//uart �o��
dualram dual_portram(
.addra(address_dup4),
.addrb(address_for_uart),
.clka(CLKFX_OUT),
.clkb(clk0),//uart ��I������Əo�͂�50MHz�@Clock�ɂȂ�̂�
.dina(demodulated_wave_final),//RAM���͂�50MHz�T���v�����O�ɂȂ�B
.dinb(),
.douta(),
.doutb(output_data),//RAM ����̏o��Data
.wea(1'b1), //Jan.23.2005
.web(1'b0)); // synthesis black_box
uart_ctrl uart_write_port(
.ASYNC_RESET(RST_In),
.clk_50M(clk0),
.ram_data(output_data),
.ram_address(address_for_uart),
.TXD(TXD));
`endif
//�������tRAM���W���[���F16bits�iIQ)��4KWords
//`define USE_ROM_DATA //HOST ���琶��Data���g���ꍇ�ɂ́A�R�����g�A�E�g
//RTL �V�~�����[�V�������́AHOST�����DATA(150MHz)���o�b�t�@�����O����
//���@���́AHOST�@DATA�́A�����BRAM�����l���g��
myrom rom(
.addra(address_dup2),
.addrb(HOST_ADDRESS),
.clka(CLKFX_OUT),
.clkb(HOST_CLK),
.dina(),
.dinb(HOST_DATA),
.douta( {data_in2,data_in1}),
.doutb( ),
.wea(1'b0),
`ifdef USE_ROM_DATA //ROM ���g���Ȃ�WRITE���Ȃ�
.web(1'b0));
`else
.web(HOST_WRITE_ENABLE));
`endif
always @(posedge CLKFX_OUT or posedge RST_In) begin
if (RST_In) address<=0;
else address<=address+1;
end
always @(posedge CLKFX_OUT) address_d<=address;
always @(posedge CLKFX_OUT) address_dup1<=address;
always @(posedge CLKFX_OUT) address_dup2<=address_dup1;
always @(posedge CLKFX_OUT) address_dup3<=address_dup2;
always @(posedge CLKFX_OUT) address_dup4<=address_dup3;
always @(posedge CLKFX_OUT) address_dup5<=address_dup4;
endmodule
//Jan.27.2005 Refine
//FM ������
module demodulator_hardware_new_sampling #(parameter Demo_MSB=7) (
input dcm_clock,//150MHz
input async_reset,
input signed [Demo_MSB:0] modulated_wave_sin,//150MHz
input signed [Demo_MSB:0] modulated_wave_cos,//150MHz
output signed [Demo_MSB+4:0] demodulated_wave_final);//150MHz
reg signed [Demo_MSB:0] input_reg_sin,input_reg_cos;
reg signed [Demo_MSB:0] sin_input,cos_input,cos_i,sin_i,cos_r,sin_r;
reg signed [Demo_MSB:0] sin_z2,cos_z2, sin_z4,cos_z4,sin_z1,sin_z3,cos_z1,cos_z3;
reg signed [Demo_MSB:0] sin_z5,cos_z5, sin_z6,cos_z6,sin_z7,sin_z8,cos_z7,cos_z8;
reg signed [(Demo_MSB+1)*2-1:0] mult1,mult2;
wire signed [(Demo_MSB+1)*2-1:0] sin_mul,cos_mul;
wire signed [(Demo_MSB+1)*2-1:0] sin_ex_z4,cos_ex_z4;
wire signed [(Demo_MSB+1)*2-1:0] diff_reg;
always @(posedge dcm_clock ) //��������͂���UFF�Ŏ�
input_reg_sin<=modulated_wave_sin;
always @(posedge dcm_clock ) //��������͂���UFF�Ŏ�
input_reg_cos<=modulated_wave_cos;
always @(posedge dcm_clock) begin//�f�B���C�@Z8�܂ł��邪�A���������̂́AZ4�܂�
sin_z1<=input_reg_sin;
sin_z2<=sin_z1;
sin_z3<=sin_z2;
sin_z4<=sin_z3;
sin_z5<=sin_z4;
sin_z6<=sin_z5;
sin_z7<=sin_z6;
sin_z8<=sin_z7;
cos_z1<=input_reg_cos;
cos_z2<=cos_z1;
cos_z3<=cos_z2;
cos_z4<=cos_z3;
cos_z5<=cos_z4;
cos_z6<=cos_z5;
cos_z7<=cos_z6;
cos_z8<=cos_z7;
end
assign sin_ex_z4=sin_z4;//�A�C�p�^�[���������ʁAZ4��I��
assign cos_ex_z4=cos_z4;//�A�C�p�^�[���������ʁAZ4��I��
always @(posedge dcm_clock ) begin
begin
mult1<=input_reg_sin*cos_ex_z4;//�����t��Z��L�q
mult2<=input_reg_cos*sin_ex_z4;//�����t��Z��L�q
end
end
mysub sub(//Xilinx �p�C�v���C���h���Z���W���[���@Coregen����
.A(mult1),
.B(mult2),
.Q(diff_reg),
.CLK(dcm_clock)); // synthesis black_box
assign demodulated_wave_final=diff_reg[Demo_MSB+4+2:2];//������o��
endmodule
|
��ԏオ�ANRZ�g�`�Afilt_out���x�b�Z���t�B���^��ʂ����g�`�ł��B�ߓn���Ƃ�āA�I�[�o�V���[�g�̂Ȃ��Y��Ȕg�`�ɂȂ�܂��B���̐������A���ш悩�M�����̗̂��ŏ��ɂ���Ƃ����ړI�ɍ��v���Ă��܂��B
��ԉ������M�g�`�ł����AAliasing�̂��߂܂Ƃ��Ɍ����܂���B
�@�@
�����ŁA�J�[�\���Ԃ��g�債�Ă݂�ƁAsin�g�ɂȂ��Ă��邱�Ƃ��킩��܂����A1%Deviation�Ȃ̂�Data�̕ω��͂悭�킩��܂���B
���̔g�`�����ď��filt_out�ɖ߂����삪demodulation�ł��B
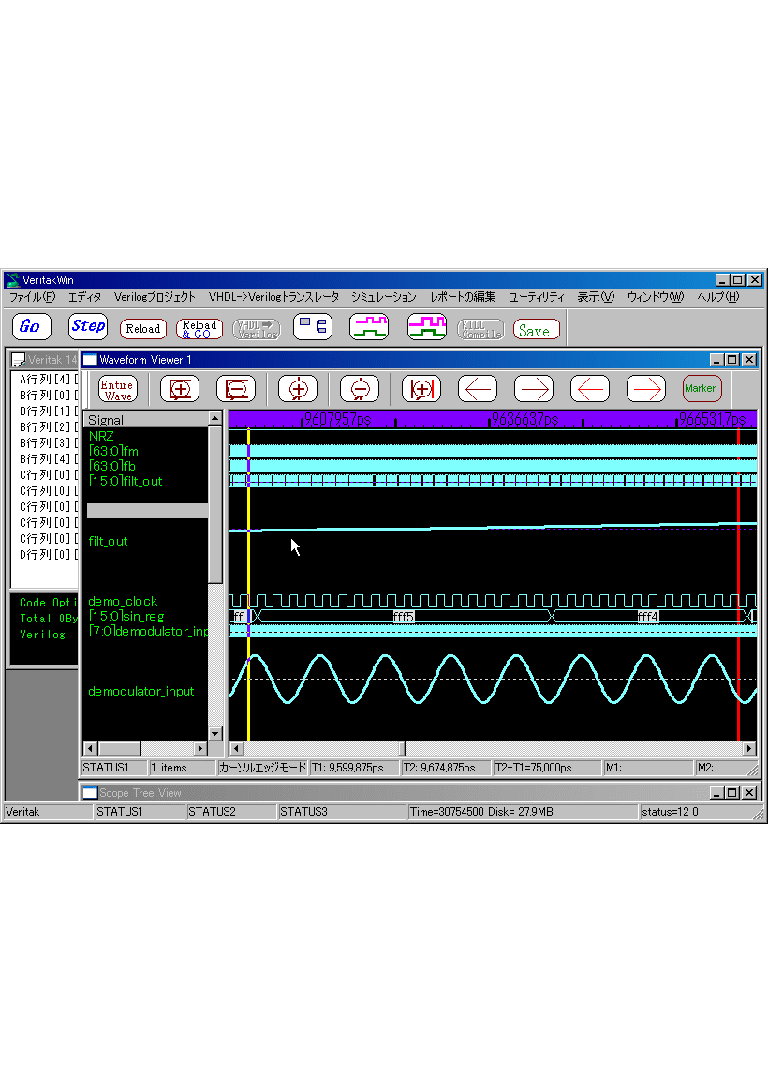
�i�Q�jDemodulation
Zero-IF�̃u���b�N�}�́A���̂悤�ɂȂ�܂��B4�{�T���v�����O����ƁA���g���ϊ���sin,cos�̌W���́A���̂悤�ɂȂ�܂�����A���ۂ̂Ƃ����Z��͕s�v�ɂȂ�܂��B
�������g���̂̊|���Z�́A����2�{�̎��g�������������܂��B�����ŁA2�{�̎��g��������LPF�ŗ��Ƃ��Ă��K�v������܂��B����́A2����FIR�ŏ\���ł��B
���}�́A����FIR�̓����ł����A�T���v�����O���g����1/2�ɂ�����Null�ɂȂ��Ă��邱�Ƃ��킩��܂��B�i4�{�T���v�����O��1/2���g�����L�����A��2�{���g���j
�Ƃ��낪�A�W����sin�Acos�̌W���́A�QCLOCK���O�Ȃ̂ŁA������܂��AFIR���Z���s���K�v�͂Ȃ����Ƃ��킩��܂��B�����܂Ōv�Z�炵���v�Z�́A�K�v����܂���ł������A���́A���̌��I/Q�v�Z�AARCTAN�v�Z�ł��B
���ꂪ�A����̉ۑ�̃|�C���g�ł��B
�@��L�ŁA�ʎq���덷���l���Ȃ��ėǂ�Real�ŏ����Ă݂܂����B
��ԉ��̔g�`��Demodulate�����g�`�ŁA���Ғʂ�x�[�X�o���h�g�`���Č����Ă��邱�Ƃ�������܂��BPLL���������ƈႢLatency�����ɏ������Ƃ��낪���̕����̓����ɂȂ��Ă��܂��B
(3) �A�C�p�^�[��
�@�x�[�X�o���h�̓]�����[�g��{�ɂ���Ƃǂ��Ȃ�ł��傤���H�x�b�Z���R��B�̃J�b�g�I�t��ς����ɁA�x�[�X�o���h�̓]�����[�g��{�̂QMBPS�ɂ��Ă݂܂��B
�@�x�[�X�o���h�g�`�́A�c�݁A�J�ڎ��Ԃ��������Ƃ���ł́A�U�����������Ȃ�܂��B
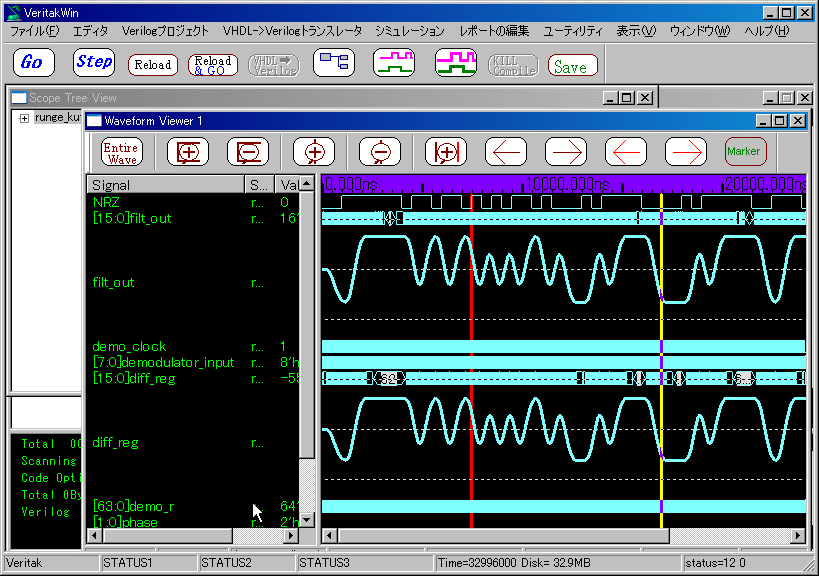
���̔g�`���I�V����Trigger�������Č����Ƃ���Ɖ��̊G�̂悤�Ɍ����܂��B������A�C�p�^�[���Ƃ����܂��B
�U�������̗]�T�͔����ȉ��ɂȂ��Ă��܂��܂����A�A�C�̒����ŃT���v�����O����A�����f�[�^�̔��ʂ͉\�ł��B
�A�C�p�^�[���́A��͂�Verilog�Ńv���O������������Excel�ŏ������܂����BVerilog2001�ł́A�������z����g����̂Ńe�X�g�x���`�������Ƃ��͏d�܂��B(��L�\�[�X�Q�Ɓj
�i4�jRTL
�@���́ADemodulator�����ۂ�H/W���ӎ������������ɒ����܂��B�ʎq���덷�AOverflow�����l�����ĉ��Z�r�b�g�������肵�܂��B
���̑O�ɁA�v�d�l������������̉����܂��B
�@GFSK�Ƃ��đ�\�I�Ȃ��̂́ABluetooth�ł��B�R���e�X�g�ۑ��Modulation��+-1%�ƁABluetooth����Spec.�����炢�v�d�l�Ƃ��Ĉȉ��̒ʂ�܂Ƃ߂܂����B
| No | ���� | �d�l | �P�� | ���l |
| �P | Clock���g�� | 300 | MH�� | Spartan3�@���E�H |
| �Q | Carrior���g�� | 75 | MH�� | 4x Oversampling |
| �R | Modulation Index | 0.3 | Bluetooth | |
| �S | BT | 0.5 | Bluetooth | |
| �T | �]��Rate | 5 | M������ | 75*0.01*2/0.3 |
�Ȃ��A�ŏI�I��Clock�́A�_��������ɁA���肵�܂��BTarget�́AStarter�@Kit(-4)�ł��B
=>�Ƃ肠�����A8�r�b�g��Z�킾���ŁA�_�����������276MHz�ɂȂ�܂����B�Ƃ��낪�A�g�`���͗p��RAM���L�q�����230MHz�ʂɗ����Ă��܂��܂����B���炩��RAM�ŗ������Ă��܂��B
���傤���Ȃ��̂Ŏ��@�ł̃^�[�Q�b�g�́A200MHz�A�Ƃ��܂����B
�A�C�p�^�[���́AVGA�ŏo�͂���������Ƃ��܂����BVGA�͏��߂ĂȂ̂ł����AR-2R���_�[DA�R���o�[�g�A�A�i���O�I�V���ŎB������X�}�[�g�ł��B
VGA�́A50MHz���g���݂����ł����AXilinx�@Starter�@Kit��50MHzClock�Ȃ̂ŁA4�{CLOCK�Ƃ���A�����������̂ł��BVGA�̃R�l�N�^�����Ă���̂ŁA���ɔ��c�t�����邱�Ƃ�����܂���B
�܂�������Ă����A���Ƃ��ƃA�i���O�I�V���̑���ɂ��Ȃ�悤�ȋC�����܂��B
�ȏ���@���@���ؗp��Target�͎��̒ʂ�Ƃ��܂��B
| No | ���� | �d�l | �P�� | ���l |
| �P | Clock���g�� | 200 | MH�� | Sartan3�@RAM��Speed��� |
| �Q | Carrior���g�� | 50 | MH�� | 4x Oversampling |
| �R | Modulation Index | 0.3 | Bluetooth | |
| �S | BT | 0.5 | Bluetooth | |
| �T | �]��Rate | 3.3 | M������ | 50*0.01*2/0.3 |
| �U | Demodulator�@Slice�� | 100�ȉ� | ��Z��2�́A��p�BDemodulator�́A276MHz�œ����\�� | |
| �V | RAM | 4x2 | �� | Dual�@Port�@���o�͋y��VGA�o�͌��p |
��L�p�����[�^��RTL���L�q���Ă݂܂����BBluetooth�@Spec.�ŋK�肳��Ă���g�`�ɋ߂��Ȃ�܂����B
Modulation�@Index�@0.3�Ƃ����̂́A+-0.15�ŁA�x�[�X�o���h�]�����[�g3.33Mbps�ɑ��āAPeak-Peak�łPMHz�ŁA�U��邱�Ƃ��Ӗ����Ă��܂��B
3.33Mbps�𑗂�̂�3.33MHz�͎g���Ă��܂���B���̂悤��GFSK�́A���ш�̒ʐM�ɓK���Ă��܂��B
�ʎq���̉e��(8�r�b�g�j���A���O�����������̂ł����A�Ă̒�A�ʎq���̉e�����łĂ��܂��B(���}�A�^���j
RTL�̃V�X�e���V�~�����[�V�����ł́A�r�b�g�����p�����[�^�����Ă������ƂŁA�C���X�^���X�����ɊȒP�ɂ��̉e�����V�~�����[�V�������邱�Ƃ��ł��܂��B
���̕ӂ́AHard�ɋ߂��iHard�@���̂��́j�̋L�q�Ȃ̂ŁAMatlab��������Ӗ��֗��ł��B�r�b�g�����P�Q�r�b�g���炢�ɂ���ƁA�������Real�̔g�`�Ƌ�ʂł��Ȃ����炢�ɂȂ�̂��m�F�ł��܂����B
�@�Ƃ���ŁA�ʎq���Ƃ����̂́A�m�C�Y�����������ƂƓ����ł��B����̗ʎq�������FNoise���ǂ����͂킩��܂��A�ȒP�ɂ́A�P����IIR�t�B���^�œ����邱�Ƃ��ł��܂��B�i��ԉ��̔g�`�j
�@����ŁA�V�X�e���Ƃ��ẴV�~�����[�V�������I���܂����B
�A���S���Y���ɔj�]���Ȃ������̂ŁA���債�Ă݂����Ǝv���܂��B
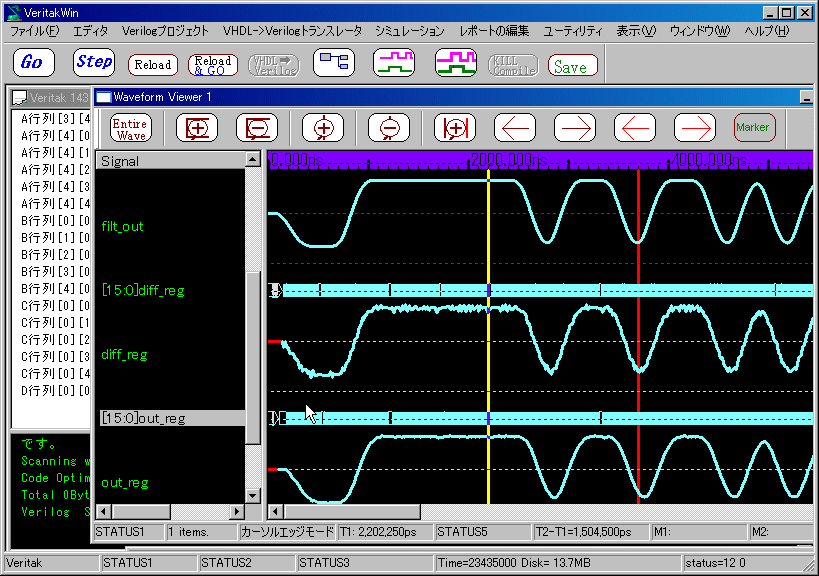
Demodulator�P�̂ł̍������ʂł��B�ŏ��̋L�q�ł́A100MHz���x�ł����B
�p�C�v���C�����ƁA���Z�r�b�g���̍팸�ɂ����240MHz���x�܂ł��܂����B�������V�X�e���V�~�����[�V������..���J��Ԃ��AReduction�ɂ���ē������ω����Ȃ����Ƃ��m�F���Ȃ���i�߂܂��B
�ڕW�̂P�O�OLUT�ȉ��͒B���ł����̂ŁA�����ł悵�Ƃ��܂��B
Critical�@Path�́A16�r�b�g���Z�����ł��BDemodulator�̋L�q�́A��100�s�ł��B
========================================================================= * Final Report * ========================================================================= Device utilization summary: --------------------------- Selected Device : 3s200pq208-4 Number of Slices: 72 out of 1920 3% Number of Slice Flip Flops: 126 out of 3840 3% Number of 4 input LUTs: 98 out of 3840 2% Number of bonded IOBs: 21 out of 141 14% Number of MULT18X18s: 2 out of 12 16% Number of GCLKs: 1 out of 8 12% ========================================================================= TIMING REPORT Clock Information: ------------------ -----------------------------------+------------------------+-------+ Clock Signal | Clock buffer(FF name) | Load | -----------------------------------+------------------------+-------+ dcm_clock | BUFGP | 144 | -----------------------------------+------------------------+-------+ Timing Summary: --------------- Speed Grade: -4 Minimum period: 4.179ns (Maximum Frequency: 239.292MHz) Minimum input arrival time before clock: 2.373ns Maximum output required time after clock: 6.172ns Maximum combinational path delay: No path found |
=>
DCM ���������Ă݂܂����BSpec.������ƌ��\�W�b�^���傫���ł��B�^�ʖڂɍl����ƁA���̃W�b�^�ŃT���v�����O������ƈʑ��덷�������ł��Ȃ��قǑ傫���Ƃ�����肪����܂��B
�܂��A�ő�쓮���g���ɁA�W�b�^�Ŏ�����͂��̃^�C�~���O�}�[�W���������v�Z�ɓ����Ă��Ȃ��悤�ł����A�����̂ł��傤���H
�i�S�jXILINX�@RTL�}�b�s���O
���ؕ��@�ɂ��āA���������̂ł����AVGA���UART�̕����ȒP�����ł��BUART��DUAL�@PORT�@RAM���e�𐂂ꗬ�����APC����Excel�������邱�Ƃɂ��܂��B
���Ӊ�H�Ƃ���DCM,UART���g���\�����C���[�W�ł����̂ŁA����STEP�́A�V�X�e���V�~�����[�V�����L�q��XILINX�@RTL�Ƀ}�b�s���O���邱�Ƃł��B
���̂��߂ɂ́A�u���b�NRAM��ROM�Ƃ��Ďg���K�v������܂��BRAM�̏������f�[�^���쐬���Ȃ��Ă͂����܂���B����́A�V�X�e���V�~�����[�V��������ROM��Verilog�L�q�����邱�Ƃɂ��܂��B
�@�܂��AROM���L�q�ł���ƁA�����V�X�e���Ƃ��ē����܂�����A���܂ł̉��z�N���b�N�̑����DCM200MHz�@�N���b�N�ŋ쓮���܂��B
�ʎq���덷���l���Ȃ��Ă��悢real�ł̋L�q����A�ʎq������Hardware�L�q�ւ̋L�q�Œ��ӂ���_�́A�����܂��B��́Areal����bit�ɕϊ����鑀��ł̎l�̌ܓ��ł��B
Verilog�̕ϊ��́AC����Ɠ��l�؎̂ĂȂ̂ŁA���Ƃ��A2.999�ł����Ă�2�ɂȂ��Ă��܂��܂��B���̏ꍇ�́A�R�ɂ��������悢���Ƃ͂����܂ł�����܂���B
Veritak�́A�l�̌ܓ�function�@$rin��������̂ł�����g����real��Ŏl�̌ܓ�(���̏ꍇ��3.0�ɕϊ��j������ɐ����ɕϊ����܂��B
��ڂ́A���Z��H�́A���x�Ƒ��x�̃g���[�h�I�t�ɂȂ�ꍇ�������A��Ńr�b�g����ς������Ȃ�ꍇ������܂��B
Verilog2001 �ɂȂ���parameter�����͂ɂȂ��Ă���̂ŁA�������g���ăr�b�g�����ςɂ��Ă����ƌ�Ŋy���ł��܂��B
=>UART���n�[�h�ʼnƂȂ�ƁA��͂�ʓ|�ł��BPC�Ŏ����EXCEL�`����DATA������̂��ʓ|�ł��BJTAG���g���A�ȒP�Ƀ_���v�ł������ł����A�������Ă��鎞�ԓI�ȗ]�T������܂���B
C����ŋL�q�ł���CPU������A����Starter�@Kit�ɍڂ���70MHz�ȏ�œ����AUART�o�͎��Ƀt�H�[�}�b�g�����Ă������Ƃ��e�Ղł��B�����CPU...����܂����BYACC�ł��B
�ŏ��ŋ��N��DWM�t�^�ɍڂ�܂�����Starter�@Kit�ɍڂ�Ȃ��͂��͂���܂���B
���x�I�ɂ��A70MHz�́A�e�Ղł��傤�B�����ŁA������YACC��RAM����̋L�q��XILINX�Ƀ|�[�g���Ă݂邱�Ƃɂ��܂����B
=>[�`�[��Veritak�v�Ƃ��ĉ��傷�邱�Ƃɂ��܂����B���僌�|�[�g�́A�����Ɍ��J���܂��B(�Q���P���ȍ~�j
�@Xilinx spartan3�X�^�[�^�L�b�g���C����œ��삷��YACC(32�r�b�gMIPS�T�݊�CPU�j��FM�@Demodulator�̃g�b�v�_�E���v�y�ю�����ɂȂ�Ǝv���܂��B
=>YACC���������Ă݂܂����B
Altera����̃|�[�g���K�v�Ȃ͎̂���2�ӏ��ł��B
- �q�`�l�̋L�q���@�B���ɂq�`�l�̏����l��^������@
- ���W�X�^�t�@�C���̋L�q
�܂��AModulator��ROM�t�@�C���́A��̃V�X�e���V�~�����[�V�������COE�t�@�C��������Verilog�L�q�Ƃ��܂����B(��L�\�[�X�Q��
�@COE�t�@�C�����o������Coregen�Ń����������܂��B���̂Ƃ�mif�t�@�C������������AVeritak�͂����ǂ݂܂��B�����V���Z�T�C�Y�p�̃t�@�C���͂܂��ʂ̃t�@�C���ɂȂ�܂��B
�܂�HDL�V�~�����[�V���������̂Ƃ��́Amif�����������Ă������̂ł����A�����������ʂɂ͔��f����܂���B
���W�X�^�t�@�C���ɂ������H�v���v��܂��B�RPORT�̃��W�X�^�t�@�C�����v��̂ł���Altera�ł́A������RPORT��RAM�ō������邱�Ƃ��ł��܂����BXilinx�ł́A����͂���܂���B
���URAM���g���ł���̂ł����A����ł́A���\�[�X����傫�����A����ڂ�܂���B�����ŁA2�|�[�g�̃u���b�NRAM��2�g��(�����f�[�^�������܂��j���Ƃɂ��܂����B
�ܑ̂Ȃ��ł����A���������FF�̏����}���邱�Ƃ��ł��܂��B����90%��FIT���܂����B
����́A�\�z�O�ɑ傫���ADemodulator���ڂ���ƃM���M���ł��BFIT���Ȃ���������܂���B�����ŁA���̕��@�́A�f�O���P����UART���ꗬ�������Ƃ��܂����B
�i�T�j�Q�[�g���x���V�~�����[�V����
�@�������RTL�V�~�����[�V�������܂��s���܂����B���̒i�K�ł̖��́Asigned�̉��߂�HDL�V�~�����[�^�ƃV���Z�T�C�U�ňقȂ邱�Ƃł��BXilinx�V���Z�T�C�U�ł́A$singed���T�|�[�g����Ă��܂���B
�����ł́A�ڂ����q�ׂ܂���signed�ƃr�b�g���g���Ɋւ��Ă�HDL�V�~�����[�^�ƃV���Z�T�C�U�̉��߂���v���Ȃ��ꍇ�����X����̂Œ��ӂ��K�v�ł��B
����́A���̂���ӏ���Verilog2001�@signed�@����]���Ɠ����������isigned�Ɉˑ����Ȃ��������j�ɕύX���Ĉ�v�����܂����B
Coregen�@Library���g���ăV�~�����[�V�������s���܂������A���̕ӂ́A�_���������Q�[�g���x���̃V�~�����[�V���������Ȃ��Ɩ��̗L�����m�F�ł��܂���B
�Q�[�g���x���V�~�����[�V�����́A�u�x���V�~�����[�V�����v�̑��ɘ_��������HDL�̈�v���Ƃ��Ă��Ӗ��������܂��B
�@

��ԏ�̔g�`�́A�T�OMH���̓��͔g�`�ł��BDCM��LOCKED����ƁA�S��CLOCK��DCM�����g�`(5ns=200MHz�j���o�͂���Ă��邱�Ƃ�������܂��B���̉��́A8�r�b�gROM�̔g�`�ł��B
4�{�T���v�����O�̈��g�`��sin�g��z������̂́A�����������܂���B���ꂪ�ADemodulator�̓��͂ɂȂ�܂��B
���Ȃ݂ɂ��̉��̔g�`�́ADCM�̓����M�����o�������̂ł��B180�x�A270�x���̐M������������Ă���̂�������܂��B
���̂Ƃ���Demodulator�o�͔g�`�ł��B�]�����[�g�́A�R�D�RMBPS�ł�����A�ŏ��s�[�N�́A�R�O�Ons�ɂȂ��Ă��܂��B
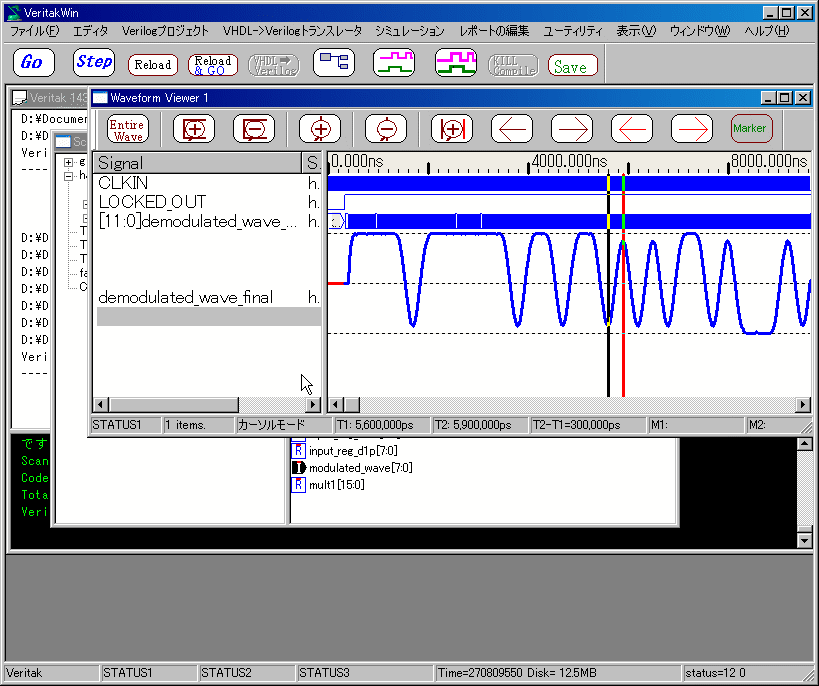
�Q�[�g�V�~�����[�V�����ɂ���XILINX�ł́AMAP��POST�@ROUTE�Ƃ����V�~�����[�V�����t�@�C������������܂��BMAP�ł́APlace�����̏��݂̂炵���A�قڏ�̍������x�ŃV�~�����[�V�������ł��܂����B
�������APOST�@ROUTE��Veritak�Q�[�g�V�~�����[�V�������s���Ă݂�ƁASetup/Hold�@�G���[�̃I���p���[�h��200MHz�ł͓����܂���ł����B
Systhesize�@Report�ł́A240MHz�o�Ă����̂�POST�@ROUTE�@TIMING�@REPORT������ƁA�m����200MHz��藎���Ă��܂��B150Mhz�����łĂ��܂���B20%�Ȃ�d���Ȃ��悤�ȋC�����܂����A50%�߂��Ȃ�ƍ��\�ɋ߂��B�B�B�B�B
�Ƃ肠�����A����200MHz�ł͓����Ȃ��̂ŁA150MHz��PostLayoutGate�V�~�����[�V�������s���Ă݂܂����B���̏�̔g�`�������ł����J�[�\�����g�債�Ă݂�ƃm�C�Y�̂悤�ȃq�Q���łĂ��܂��B�i�����j
�@����Ƀq�Q�̕������g�債�Ă݂�ƕ����r�b�g�̂����ł��邱�Ƃ��킩��܂��B���̐M���́A12�r�b�g����REG�o�͂ł��B�e�r�b�g�̃s���o�͂̒x�����Ԃ��قȂ邽�߂ɂ��̂悤�Ɍ����܂��B
�i�E���g�`�ŁA�ŏ�CLKFX���ׂ����o�^���Ă���l�q����������ł��傤�B���Ȃ݂ɒx���V�~�����[�V�����Ȃ̂ŁA�S�g�`Save�ł̓�����������������ł��B���̔g�`�ŁA155.1MB���H���Ă��܂��B�j�@
�@
�Ƃ肠�����A�ǂ����邩�l�����ł��BCD��150KB/Sec�Ȃ̂ŁACD������]�����悤�ƍl�����1.2Mbps����A�悢�ł����A�p�P�b�g�����l�����50%���x�ɒቺ����̂ŁA3Mbps�͗~�����B�B�B�B
=>
�@���ǁA200MHz�������Ƃ������_�ɒB���܂����B���̘_�����͂���Ȃ�FF�Ԃ̐ڑ������ŁA3.xns�H���Ă��܂��B��Z���2ns�͂����܂�����ǂ��撣���Ă�200MHz�͖������낤�Ƃ������_�ł��B
�i�t���[�A�v�����������Ƃ��A����̂�������܂��B�B�j
�@�����ŁADSM���g���ăL�����A���g����CLOCK�œ����d�l�ɕύX���邱�Ƃɂ��܂��BAltera�ł������ł������A120MHz���������肩��z���x�����x�z�I�ɂȂ��Ă��܂��Đ��\�������Â炭�Ȃ�܂��B�i�����炽������ԁj�@
�����ŁA�{���̖ړI�ɗ����Ԃ�A�S���������ŁA�ő��x�[�X�o���h��B������Ƃ����ړI���v���o���܂����B���ׂ̈ɂ́A�S���N���b�N���P���N���b�N�ɂ��Ă��܂��������ƂɂȂ�܂��B
�ʑ���4�{�����܂��̂ŁA�p�C�v���C�����ł��܂����Ȃ��������łĂ��܂����A����ł�100MHz���x�͂����ł��傤�B6.7M�������ʂ͍s���Ǝv���܂��B�p�C�v���C�����g���Ȃ��̂ŁALUT���́A�������܂��B
| No | ���� | �d�l | �P�� | ���l |
| �P | Clock���g�� | T.B.D. | MH�� | Sartan3�@RAM��Speed��� |
| �Q | Carrior���g�� | T.B.D. | MH�� | �Px Oversampling |
| �R | Modulation Index | 0.3 | Bluetooth | |
| �S | BT | 0.5 | Bluetooth | |
| �T | �]��Rate | T.B.D. | M������ | T.B.D.*0.01*2/0.3 |
| �U | Demodulator�@Slice�� | 80�ȉ� | ��Z��2�́A��p�B | |
| �V | RAM | T.B.D. | �� | Dual�@Port�@���o�͌��p |
=>
�ǂ��ɂ��쓮���g����������܂���B�����A�Ϙa���Z���PCLOCK�ŏ������悤�Ƃ���ƁA130MHz�ʂ����E�Ȃ̂ł͂Ȃ��ł��傤���H
�Ƃ������ƂŁAIIR���~�߂ɂ��ăf�V���[�V���������ōs�����Ƃɂ��܂����B����ŁA150MHz�_���ŁA10M�������ɂȂ�܂��B10Mbps�Ƃ����̂́A�ۑ��1000�{�Ȃ̂ŁA�_���Ƃ��ẮA������������܂���B
���ʂ́A�v���i�ނɂ�āALUT�����オ��̂ɁA����́A�������Ă����Ƃ����s�v�c�Ȏ���ł��B
���ߐ���߂��̂ŁA�n�[�h��FIX�����āA���@�œ������Ă݂邱�Ƃɂ��܂��傤�B
�@
=>���̑O�Ɏ���TEST��H�������Ȃ��Ă͂����܂���B�R���e�X�g�ۑ�́A�ŏI�I�ɂ́A70�s�̓��ĂɂȂ��Ă��܂����̂ł����A���Ӊ�H�̋L�q�́A���̐��\�{�ł��B���������ԂƔ���Ⴕ�Ă��܂��B
�i�d���̗ʂ��A�\�[�X�s���Ő����ʂ�Ȃ���ł��ˁB
�x���V�~�����[�V�����ł́A150MHz�̔g�`���A�ϑ��\�ł����A���f�o�C�X��ł́A�i���x�ȃ��W�A�i���������킹�Ă��Ȃ��̂Łj�A�o��Data��DUAL�@PORT�@RAM�ɕۑ����Ă����āA��CLOCK�i�T�OMH���j��UART�ɏo�͂��܂��B
�����ł́AVerilog2001�A��*�@�̋L�q���Q�l�ɂȂ邩������܂���BSensibity�@List���������������Ȃ��Ă悢�̂ŁA�g�ݍ��킹��H�Ń��b�`����������Ă��܂��Ƃ����A�N�ł���x�͔Ƃ������낤�o�O��������邱�Ƃ��ł��܂��B
�@RTL�e�X�g����Ƃ��́AUART�̃u���b�N�����Ńe�X�g���܂��B����\1ps�̐��E�ƃ�sec�̐��E���ꏏ�Ƀe�X�g���悤�Ƃ��Ă����Ԃ̘Q��ł��B
��̉�H�́A1ps�̃W�b�^������ƁA�g�`��ŁA�m�C�Y�Ƃ��Ċϑ��ł��܂����A���̉�H�́A��%�N���b�N����������Ă����Ƃ���ŁA���Ȃ������ł��傤�B����������H���o�Ńe�X�g�x���`���L�q���邱�Ƃ��d�v��������܂���B
UART�̃e�X�g�ł��B�g�`�����Ă��āA�u�����Ă���݂��������A���������ǂ����킩��Ȃ��v�Ƃ�������܂��B�i�V���A����l��UART����̂͂炢�B�j����ȂƂ��́A�ڑ������|�[�g�����f�����O���Ă��܂��܂��B
����́AREAD��UART��ڑ����ăR���\�[���Ƀ��b�Z�[�W�������Ƃ悢�ł��傤�B�g�`�́A�X�e�[�g�}�V���̏�ԑJ�ڂƃ{�[���[�g�̊m�F�Ɏg���܂��B
//Jan20.2005 115.Kbps �ɒ���
//Jan.19.2005
//uart control �d�l
// 50MHz Clock�œ���
// 12bit RAM ��UART�Ń_���v����
// 50MHz sync_reset ���o��
// �_���v�́@ASYNC_RESET������A�QCLOCK�@WAIT��������@RAM�@����ʂSBIT����A�N�Z�X
// HEX �ŏo�́@�@�@ABCLF�@LF=0A�łSDIGIT�P�ʂɏo��
// 4KADDRESS �́A���b�v����Ƃ��A�OA���o��
// => 50M CLOCK
// => ASYNC_RESET
// => RAM_ADDRESS[11:0]
// <= RAM_DATA�@�@[11:0]
// => TXD
//
//
//
module uart_ctrl( input ASYNC_RESET,
input clk_50M,
input wire [11:0] ram_data,
output reg [11:0] ram_address,
output TXD);
parameter [7:0] CR=8'h0d;
reg sync_reset1,sync_reset2,sync_reset;
reg [3:0] state;
wire busy;
//monitor address
always @* $display("UART RAM_ADDRESS=%h",ram_address);
//combinatial logics
reg write_request;
reg [7:0] set_data;
always @(posedge clk_50M, posedge ASYNC_RESET) begin
if (ASYNC_RESET) sync_reset1<=1;
else sync_reset1 <=0;
end
always @(posedge clk_50M) sync_reset2<=sync_reset1;
always @(posedge clk_50M) sync_reset <=sync_reset2;
localparam idle_state=4'b0000,
state1=4'b0001,
uart_set_msb=4'b0010,
waiting_msb_write_done=4'b0011,
uart_set_middle=4'b0100,
waiting_middle_write_done=4'b0101,
uart_set_lsb=4'b0110,
waiting_lsb_write_done=4'b0111,
uart_set_lf=4'b1000,
address_check_state=4'b1001,
waiting_lf_write_done=4'b1010,
address_inc_state=4'b1011,
state12=4'b1100;
//state machine
always @(posedge clk_50M) begin
if (sync_reset) state <=0;
else case (state)
idle_state: state<=state1;
state1: if (busy) ;//wait
else state <=uart_set_msb;
uart_set_msb: state <=waiting_msb_write_done;
waiting_msb_write_done: if (busy);//wait
else state <=uart_set_middle;
uart_set_middle: state <=waiting_middle_write_done;
waiting_middle_write_done: if (busy);//wait
else state <=uart_set_lsb;
uart_set_lsb: state <=waiting_lsb_write_done;
waiting_lsb_write_done: if (busy);//wait
else state <=uart_set_lf;
uart_set_lf: state <=address_check_state;
address_check_state: state<=waiting_lf_write_done; //if (address_last) uart_set
waiting_lf_write_done: if (busy);//wait
else state <=address_inc_state;
address_inc_state: state<=idle_state;
default : state <=idle_state;
endcase
end
//ram address
always @(posedge clk_50M) begin
if (sync_reset) ram_address<=0;
else if (state==address_inc_state) ram_address <=ram_address+1;
end
//uart
uart_write uw( .sync_reset(sync_reset),
.clk(clk_50M),
.txd(TXD),
.data_in(set_data) ,
.write_request(write_request),
.write_done(),
.write_busy(busy));
//combinational logic
//write_request
always @* begin
case (state)
uart_set_msb,uart_set_middle,uart_set_lsb,uart_set_lf: write_request=1;//uart set
address_check_state: if (ram_address==12'hfff) write_request=1;//wrap address
else write_request=0;
default:write_request=0;
endcase
end
//set_data
always @* begin
case (state)
uart_set_msb: set_data=num_to_ascii(ram_data[ 11:8]);
uart_set_middle:set_data=num_to_ascii(ram_data[ 7:4]);
uart_set_lsb: set_data=num_to_ascii(ram_data[ 3:0]);
address_check_state:set_data=CR;//Jan.24.2005 wrap address
uart_set_lf: set_data=CR;//Jan.24.2005
default :set_data=8'hxx;
endcase
end
//digit to ascii code
function [7:0] num_to_ascii (input [3:0] num);
begin
if (num<=9) num_to_ascii=num+8'h30;
else num_to_ascii=num+55;// 41hex =>A decimal65=A a=>10
end
endfunction
endmodule
//YACC ���玝���Ă����B
module uart_write( sync_reset, clk, txd, data_in , write_request,write_done,write_busy);
input sync_reset,clk;
input [7:0] data_in;
input write_request;
output txd,write_done;
output write_busy;
parameter MAX_DEPTH=7;
parameter ADDRESS_MSB=2;
reg [7:0] queue[0:MAX_DEPTH];
reg [ADDRESS_MSB:0] wpointer,rpointer;
reg [ADDRESS_MSB+1:0] queue_counter;
wire queue_full;
wire queing, read_request;
wire [7:0] queue_data;
reg read_request_ff;
reg [8:0] clk_ctr;
reg [2:0] bit_ctr;
reg [2:0] ua_state;
reg [7:0] tx_sr;
reg write_done_n;
reg txd;
wire clk_ctr_equ15, clk_ctr_equ31, bit_ctr_equ7,
clk_ctr_enable_state, bit_ctr_enable_state ;
wire tx_state;
always @ (posedge clk) begin
if (sync_reset) begin
wpointer <=0;
end else if (write_request) begin
queue[wpointer]<=data_in;
wpointer <=wpointer+1;
end
end
always @ (posedge clk) begin
if (sync_reset) read_request_ff<=1'b0;
else read_request_ff<=read_request;
end
always @ (posedge clk) begin
if (sync_reset) begin
rpointer <=0;
end else if (read_request_ff) begin
rpointer <=rpointer+1;
end
end
always @ (posedge clk) begin
if (sync_reset) begin
queue_counter <=000;
end else if (!read_request_ff && write_request) begin
queue_counter <=queue_counter+1;
end else if ( read_request_ff && !write_request) begin
queue_counter <=queue_counter-1;
end
end
assign queue_full = (queue_counter == MAX_DEPTH+1);
assign queing= queue_counter !=000;
assign read_request = queing && ua_state==3'b000;
assign queue_data =queue[rpointer];
assign write_done=ua_state==3'b101;
assign write_busy=queue_full;
always @(posedge clk ) begin
if (sync_reset)
clk_ctr <= 0;
else if (clk_ctr_enable_state && clk_ctr_equ31) clk_ctr<=0;
else if (clk_ctr_enable_state) clk_ctr <= clk_ctr + 1;
else clk_ctr <= 0;
end
assign clk_ctr_equ15 = clk_ctr== 216; //orig 206
assign clk_ctr_equ31 = clk_ctr== 433;//413
always @(posedge clk) begin
if (sync_reset)
bit_ctr <= 0;
else if (bit_ctr_enable_state) begin
if (clk_ctr_equ15)
bit_ctr <= bit_ctr + 1;
end
else
bit_ctr <= 0;
end
assign bit_ctr_equ7 = (bit_ctr==7);
assign clk_ctr_enable_state = bit_ctr_enable_state || ua_state==3'b001 || ua_state==3'b100 ;
assign bit_ctr_enable_state = ua_state==3'b010 || ua_state==3'b011;
always @(posedge clk ) begin
if (sync_reset) ua_state <= 3'b000;
else begin
case (ua_state)
3'b000: if (queing) ua_state <= 3'b001;
3'b001: if ( clk_ctr_equ15) ua_state <= 3'b010;
3'b010: if (bit_ctr_equ7 & clk_ctr_equ15) ua_state <= 3'b011;
3'b011: if (clk_ctr_equ15) ua_state <= 3'b100;
3'b100: if (clk_ctr_equ15) ua_state <= 3'b101;
3'b101: ua_state <= 3'h0;
default: ua_state <= 3'h0;
endcase
end
end
always @(posedge clk ) begin
if (sync_reset) tx_sr<=0;
else if (read_request_ff) tx_sr <= queue_data[7:0];
else if (tx_state ) tx_sr <= {1'b0, tx_sr[7:1]};
end
assign tx_state=( ua_state==3'h2 || ua_state==3'h3) && clk_ctr_equ15;
always @(posedge clk ) begin
if (sync_reset) txd <=1'b1;
else if (sync_reset) txd<=1'b1;
else if (ua_state==3'h0) txd<=1'b1;
else if (ua_state==3'h1 && clk_ctr_equ15) txd<=1'b0;
else if (ua_state==3'h2 && clk_ctr_equ15) txd<=tx_sr[0];
else if (ua_state==3'h3 && clk_ctr_equ15) txd<=1'b1;
end
endmodule
//�ȉ���UART��p�e�X�g�x���`
//`define UART_CTRL_TEST //UART RTL�e�X�g�������A���̑��̓R�����g�A�E�g�̂���
//UART RTL �e�X�g���́A�P�ƃt�@�C���ʼn�
`ifdef UART_CTRL_TEST
module uart_ctrl_test;
parameter CR=8'h0d;
reg ASYNC_RESET=0;
reg clk_50M=0;
reg [11:0] ram_data=0;
wire [11:0] ram_address;
wire TXD;
wire RXD;
wire [7:0] buffer_reg;
wire int_req;
always #10 clk_50M =~clk_50M;
always @* ram_data=ram_address;
initial begin
#1 ASYNC_RESET=1;
#105 ASYNC_RESET=0;
$display("UART WRITE PORT Test Using UART READ PORT.");
end
uart_ctrl uart_write_port( ASYNC_RESET,
clk_50M,
ram_data,
ram_address,
TXD);
reg sync_reset;
always @(posedge clk_50M ,posedge ASYNC_RESET )
if (ASYNC_RESET) sync_reset<=1'b1;
else sync_reset<=1'b0;
uart_read uart_read_port( .sync_reset(sync_reset), .clk(clk_50M), .rxd(TXD),.buffer_reg(buffer_reg), .int_req(int_req));
always @(posedge int_req) begin
begin :local
reg [7:0] local_mem [0:3];
integer i=0;
if (i>=4) $stop;//Assert(0);
if (buffer_reg==CR) begin :local2 //pop stack
integer j;
j=0;
while( j < i) begin
$write( "%c",local_mem[j]);
j=j+1;
end
$write(" : time=%t\n",$time);
i=0;//clear stack
end else begin//push stack
local_mem[i]=buffer_reg;
i=i+1;
end
end
end
endmodule
`endif
module uart_read( sync_reset, clk, rxd,buffer_reg, int_req);
input sync_reset;
input clk, rxd;
output [7:0] buffer_reg;
output int_req;
//________|-|______int_req (This module,, posedge interrupt)
//
//Spec. Upper module must service within 115.2Kbpsx8bit time. Maybe enough time..hom.
//
//No error handling (overrun ) is supported.
localparam COUNTER_VALUE1 = 216;//207
localparam COUNTER_VALUE2 =COUNTER_VALUE1*2+1;//415
localparam COUNTER_VALUE3 =COUNTER_VALUE1+3;//210
reg rxq1;
reg [8:0] clk_ctr;
reg [2:0] bit_ctr;
reg [2:0] ua_state;
reg [7:0] rx_sr; //.,tx_sr;
reg int_req;
reg [7:0] buffer_reg;
wire clk_ctr_equ15, clk_ctr_equ31, bit_ctr_equ7,
clk_ctr_enable_state, bit_ctr_enable_state ;
wire clk_ctr_equ0;
//sync_reset
//synchronization
always @(posedge clk ) begin
rxq1 <=rxd ;
end
// 7bit counter
always @(posedge clk ) begin
if (sync_reset)
clk_ctr <= 0;
else if (clk_ctr_enable_state && clk_ctr_equ31) clk_ctr<=0;
else if (clk_ctr_enable_state) clk_ctr <= clk_ctr + 1;
else clk_ctr <= 0;
end
// When clock is 24MHz ,followings should be set Do not forget to change simulation file too.
assign clk_ctr_equ15 = (clk_ctr==COUNTER_VALUE1) ; // 416/2-1 Feb.9
assign clk_ctr_equ31 = (clk_ctr==COUNTER_VALUE2) ; // 416-1 Feb.9
assign clk_ctr_equ0= (clk_ctr==COUNTER_VALUE3); // for write strobe Feb.9
// 3bit counter
always @(posedge clk) begin
if (sync_reset)
bit_ctr <= 0;
else if (bit_ctr_enable_state) begin
if (clk_ctr_equ15)
bit_ctr <= bit_ctr + 1;
end
else
bit_ctr <= 0;
end
assign bit_ctr_equ7 = (bit_ctr==7);
assign clk_ctr_enable_state = ua_state !=3'b000 && ua_state<=3'b011;
assign bit_ctr_enable_state = ua_state==3'h2;
//
always @(posedge clk ) begin
if (sync_reset) ua_state <= 3'h0;
else begin
case (ua_state)
3'h0: if (rxq1==0) ua_state <= 3'h1; // if rxd==0 then goto next state and enable clock // start bit search
3'h1: if (clk_ctr_equ15) ua_state <= 3'h2; // start bit receive
3'h2: if (bit_ctr_equ7 & clk_ctr_equ15) ua_state <= 3'h3;
3'h3: if (clk_ctr_equ15) ua_state <=3'h4; // stop bit receive
3'h4: ua_state <= 3'b000;
default: ua_state <= 3'b000;
endcase
end
end
//reg_we
always @(posedge clk ) begin
if (sync_reset) buffer_reg<=8'h00;
else if (ua_state==3'h3 && clk_ctr_equ0) buffer_reg<=rx_sr;
end
//int_req
always @(posedge clk ) begin
if (sync_reset) int_req<=1'b0;
// else if (ua_state==3'h3 && clk_ctr_equ15) int_req<=1'b1;
else if (ua_state==3'h4 ) int_req<=1'b1; //Feb.1 After buffer_reg_set
else int_req<=1'b0;
end
// rx shift reg.
always @(posedge clk ) begin
if (sync_reset) rx_sr <= 0;
else if (clk_ctr_equ15) rx_sr <= {rxq1, rx_sr[7:1]};
end
endmodule
|
=> �悤�₭�A�ŏI��H��150MHz���邱�Ƃ��ł��x���V�~�����[�V�������ʂ�܂����BUART�́A50MHz�@CLOCK�Ȃ̂Ŋy���ł��B��͉�����邾���ł��B������u�Ԃ͂������N���N���܂��B
=>������Ă݂܂����B
�{�[���[�g115.2Kbps�Őڑ�����ƁA�v�ʂ�AUART�̐��ꗬ����ԂɂȂ��Ă��܂��B
������A�e�L�X�g�t�@�C���ɗ��Ƃ���Verilog��12�r�b�g�̕����t�œǂ߂A�V�~�����[�V�������̔g�`���Č�����Ƃ�����ł��B
Xilinx��Starter Kit��UCF�t�@�C�����́A��������̃t�@�C�����Q�l�ɂ����Ă��������܂����B
$readmemh�ŁA��̃e�L�X�g�t�@�C����ǂݍ��݂܂��BUART�́A���ꗬ���Ȃ̂ŁA�ǂݍ��g�`�ʒu(���ԁj��RTL�g�`�Ɠ����ɂȂ�悤�ɒ������܂��B���o�I�ɂ́A�����悤�Ɍ�����̂ő���OK�ł��B
���m�ɂ́A���̂悤�ɁARTL�V�~�����[�V�����g�`(demodulated_output)�Ɠǂݍ��g�`�iUART�����������:uart_output)�Ɣg�`��r�R�}���h�Ŕ�r���āA���Ⴊ�Ȃ����Ƃ��m�F���Ă����܂��B
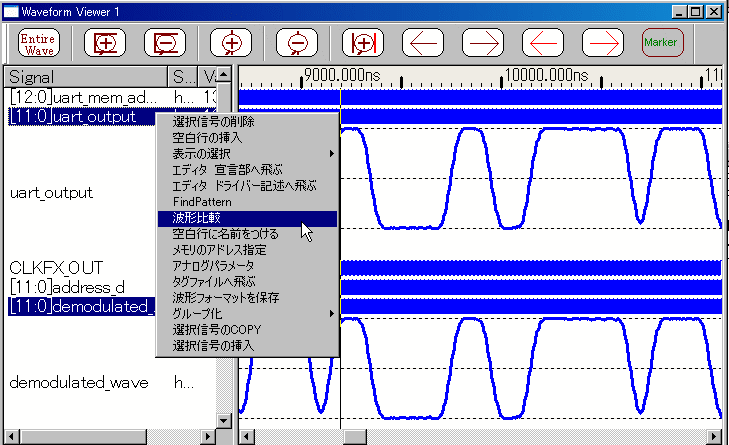
�@
�ȏ�ŁARTL�V�~�����[�V�����Ǝ��@�Ƃ̐��������������܂����B
�ۑ�ɑ���ŏI�������ʂł��B(�z�u�z���O�ł��B�j
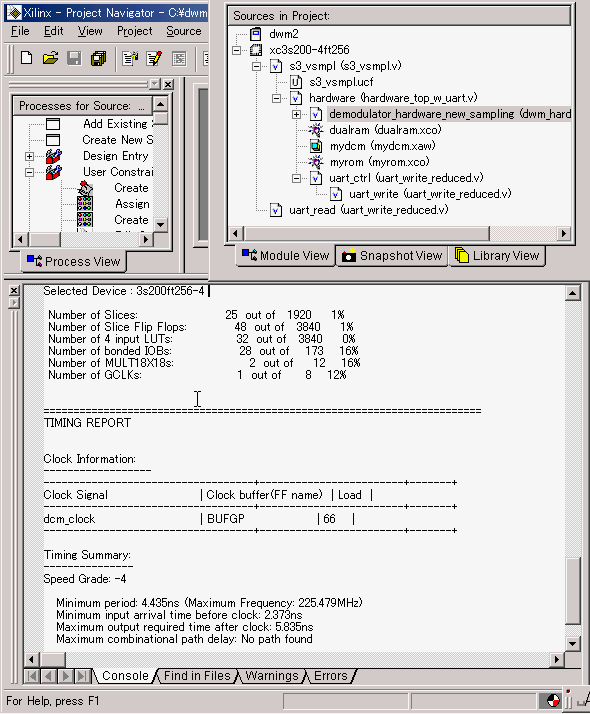
���t�@�����X��H(parity.vhdl)�̍������ʂł��B(�z�u�z���O�ł��B�j
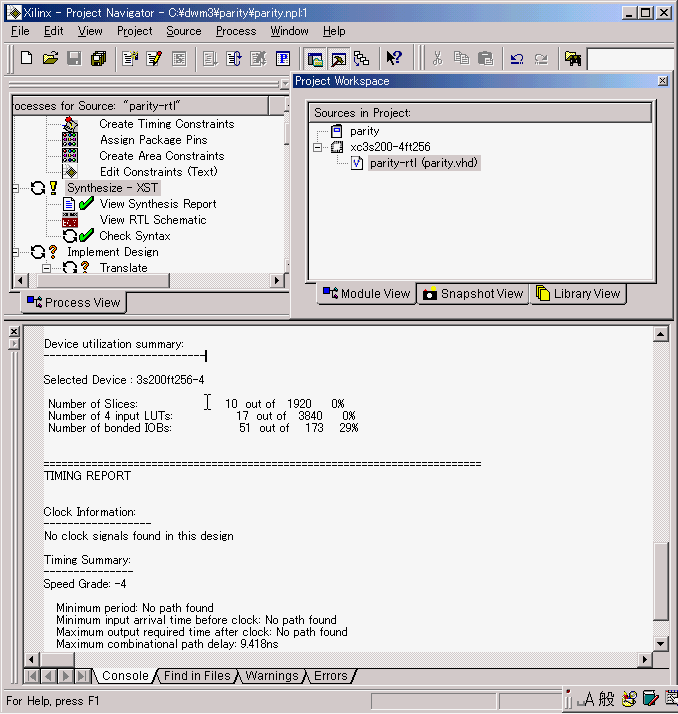
�ŏI�I�Ȍ��؉�H�ł̏����ł��B
| No | ���� | �d�l | �P�� | ���l |
| �P | Clock���g�� | 50 | MH�� | Sartan3�@RAM��Speed��� |
| �Q | Carrior���g�� | 150 | MH�� | �Px Oversampling |
| �R | Modulation Index | 0.3 | Bluetooth | |
| �S | BT | 0.5 | Bluetooth | |
| �T | ���]��Rate | 10 | M������ | 150*0.01*2/0.3 |
| �U | Demodulator�@Slice�� | 25 | ��Z��2�́A��p�B |
����ŁA�I���ł��B�P2��������\�z���n�߂āA�v�A����ƍs���āA�قڋx���́A���̍�Ƃł����B���ς��莞�Ԃ�3�{�ʂ������Ă��܂��܂����B
��o�������|�[�g�́A�����Y��ɂ܂Ƃ܂��Ă���悤�Ɍ����܂����A���ۂ́A��̂悤�����]�Ȑ܂��Ȃ���̐v�ł��B
�Ƃ�����A�v�������A�C�f�A�����o�I�Ɍ����邱�Ƃ��ł��A���ʂ��ł�܂ʼn��X�ƃR�[�f�B���O����X�g���X���Ȃ��v���̂��y���ނ��Ƃ��ł��܂����B�i�ۑ肩��傫����������Ă��܂����悤�Ȃ̂ŁA���܂͓���Ǝv���܂����B�j
��o�������|�[�g�ł��B
�A�i���OFM�̔ėp�I�ȃA���S���Y���ł���i�܂�A150MHz�̃A�i���OFM�M�������̂܂܂ŕ����\�ł��B�j���Ƃ��⑫���Ă����܂��B�I�[�v���R�A�ł�FM�̃v���W�F�N�g������̂ŁA���̂�����Ă��Ă݂邩���B
����ɂ��Ă�FM�Ƃ����ÓT�I�ȃe�[�}�ł���Ȃ���A���낢��Ȑv��������̂ł��ˁB���J����Ă��Ȃ����̃`�[���̐v�����Ă݂����Ǝv���܂����B
���Z�@���Z/�ΐ�/��������H/W�A���S���Y��(�I���j
Opencores�ɂ�IEEE754�K����FPU�\�[�X������܂��B�������A�e�X�g�x���`�̃f�[�^��W�J����ƂT�O�OMB �ɂ��Ȃ��Ă��܂��̂ŁA��ł�Up���܂���ł����B
Opencores�łȂ��Ă��A���K�͂ȉ��Z�\�[�X�����J����Ă�����������܂����B
VHDL�ŏ����Ă�����̂ŁA�g�����X���[�^���g����Verilog�ɂ��Ă݂����Ǝv���܂��B�iVersion1.47�ł́ASingle�@VHDL�t�@�C���Ȃ�Drag&Drop�Ńg�����X���[�g���܂��B�j
�f�ڋ������������܂������A�e�X�g�x���`���������Ă��܂��������ł��B�����ŁAVerilog�ɂ��e�X�g�x���`�������Ă݂邱�Ƃɂ��܂����B�ȉ��́A
- ����҂̕���VHDL�̃\�[�X
- �g�����X���[�^��ʂ������Verilog�\�[�X
- Verilog�@�e�X�g�x���`
���ӁF�Ȃ��A�t���[�n�[�h�E�F�A�ł����A���쌠��������ɂ���܂��B�T�|�[�g�͂���܂��������������Ă���\��������܂��B�g�����̎��ȐӔC�łǂ����B
1)������
36bit����18�r�b�g�̍����o�͂��܂��B
�e�X�g�x���`�́A�菑���ŏ����܂����B�ԗ��I�Ƀ`�F�b�N���܂����BOK�ł��B
����Ȋ����ł��B
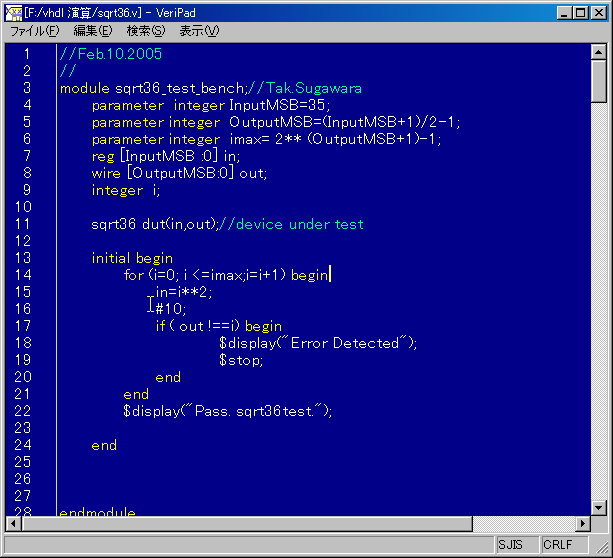
�I���W�i���̃\�[�X�R�[�h�ƃg�����X���[�^�o�͂ł��B�g�ݍ��킹��H�݂̂ŋL�q����Ă��܂��B���ۓI�ɂ́A�p�C�v���C�������K�v�ɂȂ�ł��傤�B
------------------------------------------------------------------------
-- File SQRT36.vhd --
-- Entity SQRT36 --
-- rev date coded contents --
-- 001 98/06/10 ueno Make Original --
------------------------------------------------------------------------
library ieee ;
use ieee.std_logic_1164.all ;
use ieee.std_logic_unsigned.all ;
--use IEEE.std_logic_signed.all;
use IEEE.std_logic_arith.all;
------------------------------------------------------------------------
-- entity --
------------------------------------------------------------------------
entity SQRT36 is
port(
X : in std_logic_vector(35 downto 0) ; -- Input(36bit)
Z : out std_logic_vector(17 downto 0) -- Output(18bit)
);
end SQRT36 ;
------------------------------------------------------------------------
-- architecture --
------------------------------------------------------------------------
architecture RTL of SQRT36 is
begin
--------------------------------
-- Square Root
--------------------------------
SQRT_LOOP : process( X )
variable R : std_logic_vector(35 downto 0); -- Remain
variable S : std_logic_vector(17 downto 0); -- Result
variable T : std_logic_vector(35 downto 0); -- Calclate Value
begin
-- Initialize value
R := X ;
-- Calculate MSB(bit 17)
if( R(35 downto 34) >= "01" ) then
S(17) := '1' ;
R(35 downto 34) := R(35 downto 34) - "01" ;
else
S(17) := '0' ;
R(35 downto 34) := R(35 downto 34) ;
end if;
-- Calculate 2nd bit(bit 16)
T(35 downto 32) := '0' & S(17) & "01" ;
if( R(35 downto 32) >= T(35 downto 32) ) then
S(16) := '1' ;
R(35 downto 32) := R(35 downto 32) - T(35 downto 32) ;
else
S(16) := '0' ;
end if;
-- Calculate 3rd bit(bit 15)
T(35 downto 30) := '0' & T(35 downto 34) & S(16) & "01" ;
if( R(35 downto 30) >= T(35 downto 30) ) then
S(15) := '1' ;
R(35 downto 30) := R(35 downto 30) - T(35 downto 30) ;
else
S(15) := '0' ;
end if;
-- Calculate 4th bit(bit 14)
T(35 downto 28) := '0' & T(35 downto 32) & S(15) & "01" ;
if( R(35 downto 28) >= T(35 downto 28) ) then
S(14) := '1' ;
R(35 downto 28) := R(35 downto 28) - T(35 downto 28) ;
else
S(14) := '0' ;
end if;
-- Calculate bit 13
T(35 downto 26) := '0' & T(35 downto 30) & S(14) & "01" ;
if( R(35 downto 26) >= T(35 downto 26) ) then
S(13) := '1' ;
R(35 downto 26) := R(35 downto 26) - T(35 downto 26) ;
else
S(13) := '0' ;
end if;
-- Calculate bit 12
T(35 downto 24) := '0' & T(35 downto 28) & S(13) & "01" ;
if( R(35 downto 24) >= T(35 downto 24) ) then
S(12) := '1' ;
R(35 downto 24) := R(35 downto 24) - T(35 downto 24) ;
else
S(12) := '0' ;
end if;
-- Calculate bit 11
T(35 downto 22) := '0' & T(35 downto 26) & S(12) & "01" ;
if( R(35 downto 22) >= T(35 downto 22) ) then
S(11) := '1' ;
R(35 downto 22) := R(35 downto 22) - T(35 downto 22) ;
else
S(11) := '0' ;
end if;
-- Calculate bit 10
T(35 downto 20) := '0' & T(35 downto 24) & S(11) & "01" ;
if( R(35 downto 20) >= T(35 downto 20) ) then
S(10) := '1' ;
R(35 downto 20) := R(35 downto 20) - T(35 downto 20) ;
else
S(10) := '0' ;
end if;
-- Calculate bit 9
T(35 downto 18) := '0' & T(35 downto 22) & S(10) & "01" ;
if( R(35 downto 18) >= T(35 downto 18) ) then
S(9) := '1' ;
R(35 downto 18) := R(35 downto 18) - T(35 downto 18) ;
else
S(9) := '0' ;
end if;
-- Calculate bit 8
T(35 downto 16) := '0' & T(35 downto 20) & S(9) & "01" ;
if( R(35 downto 16) >= T(35 downto 16) ) then
S(8) := '1' ;
R(35 downto 16) := R(35 downto 16) - T(35 downto 16) ;
else
S(8) := '0' ;
end if;
-- Calculate bit 7
T(35 downto 14) := '0' & T(35 downto 18) & S(8) & "01" ;
if( R(35 downto 14) >= T(35 downto 14) ) then
S(7) := '1' ;
R(35 downto 14) := R(35 downto 14) - T(35 downto 14) ;
else
S(7) := '0' ;
end if;
-- Calculate bit 6
T(35 downto 12) := '0' & T(35 downto 16) & S(7) & "01" ;
if( R(35 downto 12) >= T(35 downto 12) ) then
S(6) := '1' ;
R(35 downto 12) := R(35 downto 12) - T(35 downto 12) ;
else
S(6) := '0' ;
end if;
-- Calculate bit 5
T(35 downto 10) := '0' & T(35 downto 14) & S(6) & "01" ;
if( R(35 downto 10) >= T(35 downto 10) ) then
S(5) := '1' ;
R(35 downto 10) := R(35 downto 10) - T(35 downto 10) ;
else
S(5) := '0' ;
end if;
-- Calculate bit 4
T(35 downto 8) := '0' & T(35 downto 12) & S(5) & "01" ;
if( R(35 downto 8) >= T(35 downto 8) ) then
S(4) := '1' ;
R(35 downto 8) := R(35 downto 8) - T(35 downto 8) ;
else
S(4) := '0' ;
end if;
-- Calculate bit 3
T(35 downto 6) := '0' & T(35 downto 10) & S(4) & "01" ;
if( R(35 downto 6) >= T(35 downto 6) ) then
S(3) := '1' ;
R(35 downto 6) := R(35 downto 6) - T(35 downto 6) ;
else
S(3) := '0' ;
end if;
-- Calculate bit 2
T(35 downto 4) := '0' & T(35 downto 8) & S(3) & "01" ;
if( R(35 downto 4) >= T(35 downto 4) ) then
S(2) := '1' ;
R(35 downto 4) := R(35 downto 4) - T(35 downto 4) ;
else
S(2) := '0' ;
end if;
-- Calculate bit 1
T(35 downto 2) := '0' & T(35 downto 6) & S(2) & "01" ;
if( R(35 downto 2) >= T(35 downto 2) ) then
S(1) := '1' ;
R(35 downto 2) := R(35 downto 2) - T(35 downto 2) ;
else
S(1) := '0' ;
end if;
-- Calculate bit 0
T(35 downto 0) := '0' & T(35 downto 4) & S(1) & "01" ;
if( R(35 downto 0) >= T(35 downto 0) ) then
S(0) := '1' ;
R(35 downto 0) := R(35 downto 0) - T(35 downto 0) ;
else
S(0) := '0' ;
end if;
-- Result
Z <= S ;
end process ;
end RTL ;
------------------------------------------------------------------------
-- End of File --
------------------------------------------------------------------------
|
//-------------------------------------------------------------------
//
// This file is automatically generated by VHDL to Verilog Translator.
// Ver.1.08 Build Mar.6.2004
// www.sugawara-systems.com
// tech-support@sugawara-systems.com
// See Original Copyright Notice for property of the file .( somewhere in this file.)
//
//--------------------------------------------------------------------
//----------------------------------------------------------------------
// File SQRT36.vhd --
// Entity SQRT36 --
// rev date coded contents --
// 001 98/06/10 ueno Make Original --
//----------------------------------------------------------------------
`timescale 1ns/1ns
`define ns 1
`define us (1000*`ns)
`define ms (1000*`us)
`define sec (1000*`ms)
module sqrt36 ( x, z );
input [35:0] x ;
output [17:0] z ;
reg [35:0] sqrt_loop__r;
reg [17:0] sqrt_loop__s;
reg [35:0] sqrt_loop__t;
reg [17:0] z;
always @ (x ) begin
sqrt_loop__r = x;
if ((sqrt_loop__r[35:34] >= 2'b01))
begin
sqrt_loop__s[17] = 1'b1;
sqrt_loop__r[35:34] = (sqrt_loop__r[35:34] - 2'b01);
end
else
begin
sqrt_loop__s[17] = 1'b0;
sqrt_loop__r[35:34] = sqrt_loop__r[35:34];
end
sqrt_loop__t[35:32] = {{1'b0,sqrt_loop__s[17]},2'b01};
if ((sqrt_loop__r[35:32] >= sqrt_loop__t[35:32]))
begin
sqrt_loop__s[16] = 1'b1;
sqrt_loop__r[35:32] = (sqrt_loop__r[35:32] - sqrt_loop__t[35:32]);
end
else
sqrt_loop__s[16] = 1'b0;
sqrt_loop__t[35:30] = {{{1'b0,sqrt_loop__t[35:34]},sqrt_loop__s[16]},2'b01};
if ((sqrt_loop__r[35:30] >= sqrt_loop__t[35:30]))
begin
sqrt_loop__s[15] = 1'b1;
sqrt_loop__r[35:30] = (sqrt_loop__r[35:30] - sqrt_loop__t[35:30]);
end
else
sqrt_loop__s[15] = 1'b0;
sqrt_loop__t[35:28] = {{{1'b0,sqrt_loop__t[35:32]},sqrt_loop__s[15]},2'b01};
if ((sqrt_loop__r[35:28] >= sqrt_loop__t[35:28]))
begin
sqrt_loop__s[14] = 1'b1;
sqrt_loop__r[35:28] = (sqrt_loop__r[35:28] - sqrt_loop__t[35:28]);
end
else
sqrt_loop__s[14] = 1'b0;
sqrt_loop__t[35:26] = {{{1'b0,sqrt_loop__t[35:30]},sqrt_loop__s[14]},2'b01};
if ((sqrt_loop__r[35:26] >= sqrt_loop__t[35:26]))
begin
sqrt_loop__s[13] = 1'b1;
sqrt_loop__r[35:26] = (sqrt_loop__r[35:26] - sqrt_loop__t[35:26]);
end
else
sqrt_loop__s[13] = 1'b0;
sqrt_loop__t[35:24] = {{{1'b0,sqrt_loop__t[35:28]},sqrt_loop__s[13]},2'b01};
if ((sqrt_loop__r[35:24] >= sqrt_loop__t[35:24]))
begin
sqrt_loop__s[12] = 1'b1;
sqrt_loop__r[35:24] = (sqrt_loop__r[35:24] - sqrt_loop__t[35:24]);
end
else
sqrt_loop__s[12] = 1'b0;
sqrt_loop__t[35:22] = {{{1'b0,sqrt_loop__t[35:26]},sqrt_loop__s[12]},2'b01};
if ((sqrt_loop__r[35:22] >= sqrt_loop__t[35:22]))
begin
sqrt_loop__s[11] = 1'b1;
sqrt_loop__r[35:22] = (sqrt_loop__r[35:22] - sqrt_loop__t[35:22]);
end
else
sqrt_loop__s[11] = 1'b0;
sqrt_loop__t[35:20] = {{{1'b0,sqrt_loop__t[35:24]},sqrt_loop__s[11]},2'b01};
if ((sqrt_loop__r[35:20] >= sqrt_loop__t[35:20]))
begin
sqrt_loop__s[10] = 1'b1;
sqrt_loop__r[35:20] = (sqrt_loop__r[35:20] - sqrt_loop__t[35:20]);
end
else
sqrt_loop__s[10] = 1'b0;
sqrt_loop__t[35:18] = {{{1'b0,sqrt_loop__t[35:22]},sqrt_loop__s[10]},2'b01};
if ((sqrt_loop__r[35:18] >= sqrt_loop__t[35:18]))
begin
sqrt_loop__s[9] = 1'b1;
sqrt_loop__r[35:18] = (sqrt_loop__r[35:18] - sqrt_loop__t[35:18]);
end
else
sqrt_loop__s[9] = 1'b0;
sqrt_loop__t[35:16] = {{{1'b0,sqrt_loop__t[35:20]},sqrt_loop__s[9]},2'b01};
if ((sqrt_loop__r[35:16] >= sqrt_loop__t[35:16]))
begin
sqrt_loop__s[8] = 1'b1;
sqrt_loop__r[35:16] = (sqrt_loop__r[35:16] - sqrt_loop__t[35:16]);
end
else
sqrt_loop__s[8] = 1'b0;
sqrt_loop__t[35:14] = {{{1'b0,sqrt_loop__t[35:18]},sqrt_loop__s[8]},2'b01};
if ((sqrt_loop__r[35:14] >= sqrt_loop__t[35:14]))
begin
sqrt_loop__s[7] = 1'b1;
sqrt_loop__r[35:14] = (sqrt_loop__r[35:14] - sqrt_loop__t[35:14]);
end
else
sqrt_loop__s[7] = 1'b0;
sqrt_loop__t[35:12] = {{{1'b0,sqrt_loop__t[35:16]},sqrt_loop__s[7]},2'b01};
if ((sqrt_loop__r[35:12] >= sqrt_loop__t[35:12]))
begin
sqrt_loop__s[6] = 1'b1;
sqrt_loop__r[35:12] = (sqrt_loop__r[35:12] - sqrt_loop__t[35:12]);
end
else
sqrt_loop__s[6] = 1'b0;
sqrt_loop__t[35:10] = {{{1'b0,sqrt_loop__t[35:14]},sqrt_loop__s[6]},2'b01};
if ((sqrt_loop__r[35:10] >= sqrt_loop__t[35:10]))
begin
sqrt_loop__s[5] = 1'b1;
sqrt_loop__r[35:10] = (sqrt_loop__r[35:10] - sqrt_loop__t[35:10]);
end
else
sqrt_loop__s[5] = 1'b0;
sqrt_loop__t[35:8] = {{{1'b0,sqrt_loop__t[35:12]},sqrt_loop__s[5]},2'b01};
if ((sqrt_loop__r[35:8] >= sqrt_loop__t[35:8]))
begin
sqrt_loop__s[4] = 1'b1;
sqrt_loop__r[35:8] = (sqrt_loop__r[35:8] - sqrt_loop__t[35:8]);
end
else
sqrt_loop__s[4] = 1'b0;
sqrt_loop__t[35:6] = {{{1'b0,sqrt_loop__t[35:10]},sqrt_loop__s[4]},2'b01};
if ((sqrt_loop__r[35:6] >= sqrt_loop__t[35:6]))
begin
sqrt_loop__s[3] = 1'b1;
sqrt_loop__r[35:6] = (sqrt_loop__r[35:6] - sqrt_loop__t[35:6]);
end
else
sqrt_loop__s[3] = 1'b0;
sqrt_loop__t[35:4] = {{{1'b0,sqrt_loop__t[35:8]},sqrt_loop__s[3]},2'b01};
if ((sqrt_loop__r[35:4] >= sqrt_loop__t[35:4]))
begin
sqrt_loop__s[2] = 1'b1;
sqrt_loop__r[35:4] = (sqrt_loop__r[35:4] - sqrt_loop__t[35:4]);
end
else
sqrt_loop__s[2] = 1'b0;
sqrt_loop__t[35:2] = {{{1'b0,sqrt_loop__t[35:6]},sqrt_loop__s[2]},2'b01};
if ((sqrt_loop__r[35:2] >= sqrt_loop__t[35:2]))
begin
sqrt_loop__s[1] = 1'b1;
sqrt_loop__r[35:2] = (sqrt_loop__r[35:2] - sqrt_loop__t[35:2]);
end
else
sqrt_loop__s[1] = 1'b0;
sqrt_loop__t[35:0] = {{{1'b0,sqrt_loop__t[35:4]},sqrt_loop__s[1]},2'b01};
if ((sqrt_loop__r[35:0] >= sqrt_loop__t[35:0]))
begin
sqrt_loop__s[0] = 1'b1;
sqrt_loop__r[35:0] = (sqrt_loop__r[35:0] - sqrt_loop__t[35:0]);
end
else
sqrt_loop__s[0] = 1'b0;
z <= sqrt_loop__s;
end //always
endmodule
|
�Q)���Z
���̐��� X 18�r�b�g�𐳂̐��� Y 18�r�b�g�ŏ��Z�����H�ł��B
�e�X�g�x���`�́A���Ԃ�������̂Ŗԗ��I�ɂ��Ă��܂���B$random�̂������A����ȉ��̑S�Ă�y�ɑ��ă`�F�b�N���Ă��܂��B
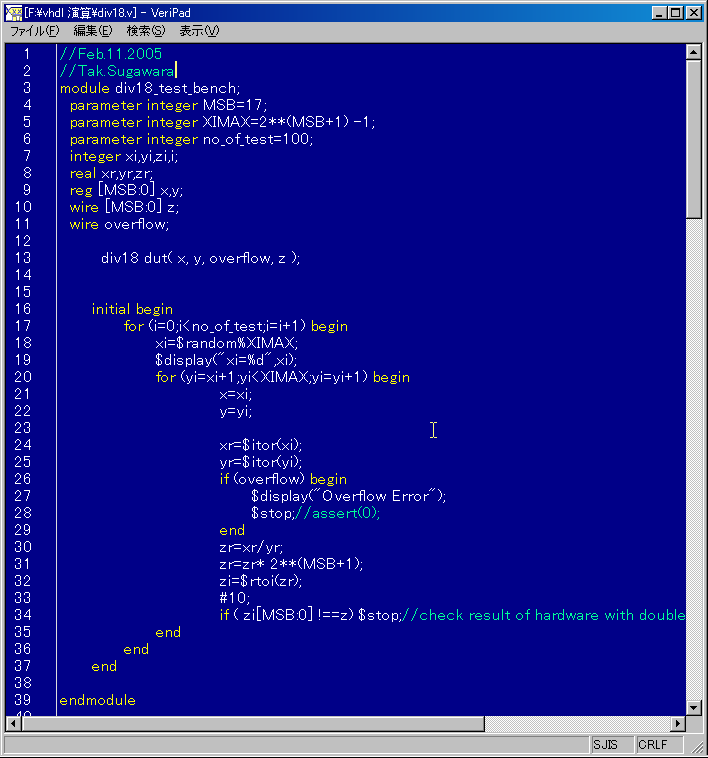
�I���W�i���̃\�[�X�R�[�h�ƃg�����X���[�^�o�͂ł��B
------------------------------------------------------------------------
-- File DIV18.vhd --
-- Entity DIV18 --
-- rev date coded contents --
-- 001 98/06/23 ueno Make Original --
------------------------------------------------------------------------
library ieee ;
use ieee.std_logic_1164.all ;
use ieee.std_logic_unsigned.all ;
--use IEEE.std_logic_signed.all;
--use IEEE.std_logic_arith.all;
------------------------------------------------------------------------
-- entity --
------------------------------------------------------------------------
entity DIV18 is
port(
X : in std_logic_vector(17 downto 0) ; -- Input(18bit)
Y : in std_logic_vector(17 downto 0) ; -- Input(18bit)
C : out std_logic ; -- OverFlow Flag
Z : out std_logic_vector(17 downto 0) -- Output(18bit)
);
end DIV18 ;
------------------------------------------------------------------------
-- architecture --
------------------------------------------------------------------------
architecture RTL of DIV18 is
begin
--------------------------------
-- X divide by Y (X < Y)
--------------------------------
DIVIDE_LOOP : process( X, Y )
variable R : std_logic_vector(19 downto 0); -- Remain
variable S : std_logic_vector(17 downto 0); -- Result
variable T : std_logic_vector(19 downto 0); -- Temporaly
begin
if( X < Y ) then
-- Initialize value
R := '0' & X & '0' ; -- R = 2 * X
T := "00" & Y ; -- T = Y
for i in 17 downto 0 loop
if( R >= T ) then
S(i) := '1' ;
R := R - T ;
else
S(i) := '0' ;
end if ;
R := R(18 downto 0) & '0' ;
end loop ;
-- Result
Z <= S ;
C <= '0' ;
else
C <= '1' ;
Z <= "000000000000000000" ;
end if ;
end process ;
end RTL ;
------------------------------------------------------------------------
-- End of File --
------------------------------------------------------------------------
|
//-------------------------------------------------------------------
//
// This file is automatically generated by VHDL to Verilog Translator.
// Ver.1.08 Build Mar.6.2004
// www.sugawara-systems.com
// tech-support@sugawara-systems.com
// See Original Copyright Notice for property of the file .( somewhere in this file.)
//
//--------------------------------------------------------------------
//----------------------------------------------------------------------
// File DIV18.vhd --
// Entity DIV18 --
// rev date coded contents --
// 001 98/06/23 ueno Make Original --
//----------------------------------------------------------------------
`timescale 1ns/1ns
`define ns 1
`define us (1000*`ns)
`define ms (1000*`us)
`define sec (1000*`ms)
module div18 ( x, y, c, z );
input [17:0] x ;
input [17:0] y ;
output c;
output [17:0] z ;
reg [19:0] divide_loop__r;
reg [17:0] divide_loop__s;
reg [19:0] divide_loop__t;
reg c;
reg [17:0] z;
always @ (x or y ) begin
if ((x < y))
begin
divide_loop__r = {{1'b0,x},1'b0};
divide_loop__t = {2'b00,y};
begin :Block_Name_1
integer i;
for (i=17;i>=0;i=i-1) begin
begin
if ((divide_loop__r >= divide_loop__t))
begin
divide_loop__s[i] = 1'b1;
divide_loop__r = (divide_loop__r - divide_loop__t);
end
else
divide_loop__s[i] = 1'b0;
divide_loop__r = {divide_loop__r[18:0],1'b0};
end
end //for
end //end Block
z <= divide_loop__s;
c <= 1'b0;
end
else
begin
c <= 1'b1;
z <= 18'b000000000000000000;
end
end //always
endmodule
|
�R�j�������̋t��Part�T
Z = 1/��X (�A�� X=0 �̏ꍇ Z=0) ���̐��� X 20 �r�b�g�̕������̋t�����Ƃ��H �o�͕͂��������_�`���Ŏw����(ZN) 4 �r�b�g�C������(ZM) 20 �r�b�g�ł��B
�e�X�g�x���`�́A�ԗ��I�ɏ����܂����B
�I���W�i���̃\�[�X�R�[�h�ƃg�����X���[�^�o�͂ł��B
------------------------------------------------------------------------
-- Title Reverse Square-Root (1/sqr(X)) --
-- File RSQRT.vhd --
-- Entity RSQRT --
-- rev date coded contents --
-- 001 98/11/05 ueno Make Original --
------------------------------------------------------------------------
library ieee ;
use ieee.std_logic_1164.all ;
use ieee.std_logic_unsigned.all ;
--use IEEE.std_logic_signed.all ;
use IEEE.std_logic_arith.all ;
------------------------------------------------------------------------
-- entity --
------------------------------------------------------------------------
entity RSQRT is
port(
X : in std_logic_vector(19 downto 0) ; -- Input(20bit)
ZN : out std_logic_vector(3 downto 0) ; -- Exp(4bit)
ZM : out std_logic_vector(19 downto 0) -- Man(20bit)
);
end RSQRT ;
------------------------------------------------------------------------
-- architecture --
------------------------------------------------------------------------
architecture RTL of RSQRT is
--
-- 1st stages
-- 10bit calc
-- XX.XXXXXXXX
signal A : std_logic_vector(9 downto 0) ; --
constant CONSA : std_logic_vector(9 downto 0) := "1000000111" ; -- 2.02734375
--
-- 2nd stages
-- 16bit calc
-- XX.XXXXXXXXXXXXXXXX
signal B : std_logic_vector(15 downto 0) ; --
--
-- 3rd stages
-- 26bit calc
-- XX.XXXXXXXXXXXXXXXXXXXXXXXX
signal C : std_logic_vector(25 downto 0) ; --
--
-- Constant Value
constant CONSX : std_logic_vector(31 downto 0) := "11000000000000000000000000000000" ; -- 3.0
--
--
-- 0.XXXXXXXX
signal M : std_logic_vector(19 downto 0) ; -- Mantissa
signal N : std_logic_vector(3 downto 0) ; -- Expornent
begin
--------------------------------
-- Reverse Square-Root Argolizm
--
-- X = m x 4^n (m = 0.25~0.999999)
-- Z = 1/sqrt(X) = sqrt(m)/m x 2^-n
-- ^^^^^^^^^ |
-- ZM ZN
-- --1st stage (3.16bit)
-- a = (2.0275551-m) -- a = 1.78~1.02
-- --2nd stage (5.70bit) : 1000 LCs
-- b1 = (a*a) -- b1 = +3.17~+1.04
-- b2 = (m*b1) -- b2 = +0.813~+1.0208
-- b3 = (3-b2)/2 -- b3 = +0.99~+1.094
-- b4 = a*b3 -- b4 = +1.00~+1.98
-- b = b4
-- --3nd stage (10.82bit) : 2500 LCs
-- c1 = (b*b) -- c1 = +3.92~+1.00
-- c2 = (m*c1) -- c2 = +0.99~+1.01
-- c3 = (3-c2)/2 -- c3 = +0.99~+1.01
-- c4 = b*c3 -- c4 = +1.00~+1.99
-- c = c4
-- --4th stage (21.06bit) : ???? LCs
-- d1 = (c*c) -- d1 = +3.98~+1.00
-- d2 = (m*d1) -- d2 = +0.99~+1.01
-- d3 = (3-d2)/2 -- d3 = +0.99~+1.01
-- d4 = c*d3 -- d4 = +1.00~+1.99
-- d = d4
--
-- ZM = g3
-- ZN = n
--------------------------------
-----------------------------------------------------------
-- Initialize --
-----------------------------------------------------------
RSQRT_INIT : process( X )
begin
if( X(19 downto 0) = "00000000000000000000" ) then
M <= (others=>'0') ;
N <= (others=>'0') ;
else
-- Generate M,N
if( X(19 downto 2) = "000000000000000000" ) then
M <= X(1 downto 0) & "000000000000000000" ;
N <= "0001" ;
elsif( X(19 downto 4) = "0000000000000000" ) then
M <= X(3 downto 0) & "0000000000000000" ;
N <= "0010" ;
elsif( X(19 downto 6) = "00000000000000" ) then
M <= X(5 downto 0) & "00000000000000" ;
N <= "0011" ;
elsif( X(19 downto 8) = "000000000000" ) then
M <= X(7 downto 0) & "000000000000" ;
N <= "0100" ;
elsif( X(19 downto 10) = "0000000000" ) then
M <= X(9 downto 0) & "0000000000" ;
N <= "0101" ;
elsif( X(19 downto 12) = "00000000" ) then
M <= X(11 downto 0) & "00000000" ;
N <= "0110" ;
elsif( X(19 downto 14) = "000000" ) then
M <= X(13 downto 0) & "000000" ;
N <= "0111" ;
elsif( X(19 downto 16) = "0000" ) then
M <= X(15 downto 0) & "0000" ;
N <= "1000" ;
elsif( X(19 downto 18) = "00" ) then
M <= X(17 downto 0) & "00" ;
N <= "1001" ;
else
M <= X ;
N <= "1010" ;
end if ;
end if ;
end process ;
-----------------------------------------------------------
-- 1st stage --
-----------------------------------------------------------
RSQRT_1ST : process( M )
begin
if( M = "00000000000000000000" ) then
A <= (others=>'0') ;
else
-- A = 2.03-M
A <= CONSA - ("00" & M(19 downto 12)) ;
end if ;
end process ;
-----------------------------------------------------------
-- 2nd stage --
-----------------------------------------------------------
RSQRT_1ND : process( A )
variable B1 : std_logic_vector(17 downto 0); -- A(9bit)*A(9bit)
variable B2 : std_logic_vector(16 downto 0); -- M(8bit)*B1(9bit)
variable B3 : std_logic_vector(10 downto 0); -- 3-B2(11bit)
variable B4 : std_logic_vector(19 downto 0); -- A(9bit)*B3(11bit)
begin
if( A = "0000000000" ) then
B <= (others=>'0') ;
else
B1 := A(8 downto 0) * A(8 downto 0) ;
B2 := B1(17 downto 9) * M(19 downto 12) ;
B3 := CONSX(31 downto 21) - B2(16 downto 6) ;
B4 := B3 * A(8 downto 0) ;
B <= B4(19 downto 4) ;
end if ;
end process ;
-----------------------------------------------------------
-- 3rd stage --
-----------------------------------------------------------
RSQRT_3RD : process( B )
variable C1 : std_logic_vector(29 downto 0); -- B(15bit)*B(15bit)
variable C2 : std_logic_vector(31 downto 0); -- M(16bit)*C1(16bit)
variable C3 : std_logic_vector(18 downto 0); -- 3-C2(19bit)
variable C4 : std_logic_vector(33 downto 0); -- B(15bit)*C3(19bit)
begin
if( B = "0000000000000000" ) then
C <= (others=>'0') ;
else
C1 := B(14 downto 0) * B(14 downto 0) ;
C2 := C1(29 downto 14) * M(19 downto 4) ;
C3 := CONSX(31 downto 13) - C2(31 downto 13) ;
C4 := C3 * B(14 downto 0) ;
C <= C4(33 downto 8) ;
end if ;
end process ;
ZN <= N ;
--ZM <= A & "00000000000" ;
--ZM <= B & "0000" ;
ZM <= C(24 downto 5) ;
end RTL ;
------------------------------------------------------------------------
-- End of File --
------------------------------------------------------------------------
|
//-------------------------------------------------------------------
//
// This file is automatically generated by VHDL to Verilog Translator.
// Ver.1.08 Build Mar.6.2004
// www.sugawara-systems.com
// tech-support@sugawara-systems.com
// See Original Copyright Notice for property of the file .( somewhere in this file.)
//
//--------------------------------------------------------------------
//----------------------------------------------------------------------
// Title Reverse Square-Root (1/sqr(X)) --
// File RSQRT.vhd --
// Entity RSQRT --
// rev date coded contents --
// 001 98/11/05 ueno Make Original --
//----------------------------------------------------------------------
`timescale 1ns/1ns
`define ns 1
`define us (1000*`ns)
`define ms (1000*`us)
`define sec (1000*`ms)
module rsqrt ( x, zn, zm );
input [19:0] x ;
output [3:0] zn ;
output [19:0] zm ;
reg [17:0] rsqrt_1nd__b1;
reg [16:0] rsqrt_1nd__b2;
reg [10:0] rsqrt_1nd__b3;
reg [19:0] rsqrt_1nd__b4;
reg [29:0] rsqrt_3rd__c1;
reg [31:0] rsqrt_3rd__c2;
reg [18:0] rsqrt_3rd__c3;
reg [33:0] rsqrt_3rd__c4;
reg [9:0] a;
parameter [9:0] consa=10'b1000000111;
reg [15:0] b;
reg [25:0] c;
parameter [31:0] consx=32'b11000000000000000000000000000000;
reg [19:0] m;
reg [3:0] n;
wire [3:0] zn;
wire [19:0] zm;
always @ (x ) begin
if ((x[19:0] === 20'b00000000000000000000))
begin
m <= {(19-0+1- 0){1'b0}};
n <= {(3-0+1- 0){1'b0}};
end
else
begin
if ((x[19:2] === 18'b000000000000000000))
begin
m <= {x[1:0],18'b000000000000000000};
n <= 4'b0001;
end
else if ((x[19:4] === 16'b0000000000000000))
begin
m <= {x[3:0],16'b0000000000000000};
n <= 4'b0010;
end
else if ((x[19:6] === 14'b00000000000000))
begin
m <= {x[5:0],14'b00000000000000};
n <= 4'b0011;
end
else if ((x[19:8] === 12'b000000000000))
begin
m <= {x[7:0],12'b000000000000};
n <= 4'b0100;
end
else if ((x[19:10] === 10'b0000000000))
begin
m <= {x[9:0],10'b0000000000};
n <= 4'b0101;
end
else if ((x[19:12] === 8'b00000000))
begin
m <= {x[11:0],8'b00000000};
n <= 4'b0110;
end
else if ((x[19:14] === 6'b000000))
begin
m <= {x[13:0],6'b000000};
n <= 4'b0111;
end
else if ((x[19:16] === 4'b0000))
begin
m <= {x[15:0],4'b0000};
n <= 4'b1000;
end
else if ((x[19:18] === 2'b00))
begin
m <= {x[17:0],2'b00};
n <= 4'b1001;
end
else
begin
m <= x;
n <= 4'b1010;
end
end
end //always
always @ (m ) begin
if ((m === 20'b00000000000000000000))
a <= {(9-0+1- 0){1'b0}};
else
a <= (consa - {2'b00,m[19:12]});
end //always
always @ (a ) begin
if ((a === 10'b0000000000))
b <= {(15-0+1- 0){1'b0}};
else
begin
rsqrt_1nd__b1 = (a[8:0] * a[8:0]);
rsqrt_1nd__b2 = (rsqrt_1nd__b1[17:9] * m[19:12]);
rsqrt_1nd__b3 = (consx[31:21] - rsqrt_1nd__b2[16:6]);
rsqrt_1nd__b4 = (rsqrt_1nd__b3 * a[8:0]);
b <= rsqrt_1nd__b4[19:4];
end
end //always
always @ (b ) begin
if ((b === 16'b0000000000000000))
c <= {(25-0+1- 0){1'b0}};
else
begin
rsqrt_3rd__c1 = (b[14:0] * b[14:0]);
rsqrt_3rd__c2 = (rsqrt_3rd__c1[29:14] * m[19:4]);
rsqrt_3rd__c3 = (consx[31:13] - rsqrt_3rd__c2[31:13]);
rsqrt_3rd__c4 = (rsqrt_3rd__c3 * b[14:0]);
c <= rsqrt_3rd__c4[33:8];
end
end //always
assign {zn}=n;
assign {zm}=c[24:5];
endmodule
|
�R�j�������̋t��Part�U
Z = 1/��X (�A�� X=0 �̏ꍇ Z=0) ���̐��� X 20 �r�b�g�̕������̋t�����Ƃ��H �o�͕͂��������_�`���Ŏw����(ZN) 4 �r�b�g�C������(ZM) 20 �r�b�g�ł��B
�e�X�g�x���`�́A�ԗ��I�ɏ����܂����B�p�[�g�T�Ƃ̈Ⴂ�́A���x�ł��B
------------------------------------------------------------------------
-- Title Reverse Square-Root (1/sqr(X)) --
-- File RSQRT.vhd --
-- Entity RSQRT --
-- rev date coded contents --
-- 001 98/11/05 ueno Make Original --
-- 002 98/11/10 ueno 4th stage up --
------------------------------------------------------------------------
library ieee ;
use ieee.std_logic_1164.all ;
use ieee.std_logic_unsigned.all ;
--use IEEE.std_logic_signed.all ;
use IEEE.std_logic_arith.all ;
------------------------------------------------------------------------
-- entity --
------------------------------------------------------------------------
entity RSQRT is
port(
X : in std_logic_vector(19 downto 0) ; -- Input(20bit)
ZN : out std_logic_vector(3 downto 0) ; -- Exp(4bit)
ZM : out std_logic_vector(19 downto 0) -- Man(20bit)
);
end RSQRT ;
------------------------------------------------------------------------
-- architecture --
------------------------------------------------------------------------
architecture RTL of RSQRT is
--
-- 1st stages
-- 10bit calc
-- XX.XXXXXXXX
signal A : std_logic_vector(9 downto 0) ; --
constant CONSA : std_logic_vector(9 downto 0) := "1000000111" ; -- 2.02734375
--
-- 2nd stages
-- 16bit calc
-- XX.XXXXXXXXXXXXXXXX
signal B : std_logic_vector(15 downto 0) ; --
--
-- 3rd stages
-- 24bit calc
-- XX.XXXXXXXXXXXXXXXXXXXXXX
signal C : std_logic_vector(23 downto 0) ; --
--
-- 4th stages
-- 24bit calc
-- XX.XXXXXXXXXXXXXXXXXXXXXX
signal D : std_logic_vector(23 downto 0) ; --
--
-- Constant Value
constant CONSX : std_logic_vector(31 downto 0) := "11000000000000000000000000000000" ; -- 3.0
--
--
-- 0.XXXXXXXX
signal M : std_logic_vector(19 downto 0) ; -- Mantissa
signal N : std_logic_vector(3 downto 0) ; -- Expornent
begin
--------------------------------
-- Reverse Square-Root Argolizm
--
-- X = m x 4^n (m = 0.25~0.999999)
-- Z = 1/sqrt(X) = sqrt(m)/m x 2^-n
-- ^^^^^^^^^ |
-- ZM ZN
-- --1st stage (3.16bit)
-- a = (2.0275551-m) -- a = 1.78~1.02
-- --2nd stage (5.70bit) : 1000 LCs
-- b1 = (a*a) -- b1 = +3.17~+1.04
-- b2 = (m*b1) -- b2 = +0.813~+1.0208
-- b3 = (3-b2)/2 -- b3 = +0.99~+1.094
-- b4 = a*b3 -- b4 = +1.00~+1.98
-- b = b4
-- --3nd stage (10.82bit) : 2500 LCs
-- c1 = (b*b) -- c1 = +3.92~+1.00
-- c2 = (m*c1) -- c2 = +0.99~+1.01
-- c3 = (3-c2)/2 -- c3 = +0.99~+1.01
-- c4 = b*c3 -- c4 = +1.00~+1.99
-- c = c4
-- --4th stage (21.06bit) : 5000 LCs
-- d1 = (c*c) -- d1 = +3.98~+1.00
-- d2 = (m*d1) -- d2 = +0.99~+1.01
-- d3 = (3-d2)/2 -- d3 = +0.99~+1.01
-- d4 = c*d3 -- d4 = +1.00~+1.99
-- d = d4
--
-- ZM = g3
-- ZN = n
--------------------------------
-----------------------------------------------------------
-- Initialize --
-----------------------------------------------------------
RSQRT_INIT : process( X )
begin
if( X(19 downto 0) = "00000000000000000000" ) then
M <= (others=>'0') ;
N <= (others=>'0') ;
else
-- Generate M,N
if( X(19 downto 2) = "000000000000000000" ) then
M <= X(1 downto 0) & "000000000000000000" ;
N <= "0001" ;
elsif( X(19 downto 4) = "0000000000000000" ) then
M <= X(3 downto 0) & "0000000000000000" ;
N <= "0010" ;
elsif( X(19 downto 6) = "00000000000000" ) then
M <= X(5 downto 0) & "00000000000000" ;
N <= "0011" ;
elsif( X(19 downto 8) = "000000000000" ) then
M <= X(7 downto 0) & "000000000000" ;
N <= "0100" ;
elsif( X(19 downto 10) = "0000000000" ) then
M <= X(9 downto 0) & "0000000000" ;
N <= "0101" ;
elsif( X(19 downto 12) = "00000000" ) then
M <= X(11 downto 0) & "00000000" ;
N <= "0110" ;
elsif( X(19 downto 14) = "000000" ) then
M <= X(13 downto 0) & "000000" ;
N <= "0111" ;
elsif( X(19 downto 16) = "0000" ) then
M <= X(15 downto 0) & "0000" ;
N <= "1000" ;
elsif( X(19 downto 18) = "00" ) then
M <= X(17 downto 0) & "00" ;
N <= "1001" ;
else
M <= X ;
N <= "1010" ;
end if ;
end if ;
end process ;
-----------------------------------------------------------
-- 1st stage --
-----------------------------------------------------------
RSQRT_1ST : process( M )
begin
if( M = "00000000000000000000" ) then
A <= (others=>'0') ;
else
-- A = 2.03-M
A <= CONSA - ("00" & M(19 downto 12)) ;
end if ;
end process ;
-----------------------------------------------------------
-- 2nd stage --
-----------------------------------------------------------
RSQRT_1ND : process( M, A )
variable B1 : std_logic_vector(17 downto 0); -- A(9bit)*A(9bit)
variable B2 : std_logic_vector(16 downto 0); -- M(8bit)*B1(9bit)
variable B3 : std_logic_vector(10 downto 0); -- 3-B2(11bit)
variable B4 : std_logic_vector(19 downto 0); -- A(9bit)*B3(11bit)
begin
if( A = "0000000000" ) then
B <= (others=>'0') ;
else
B1 := A(8 downto 0) * A(8 downto 0) ;
B2 := B1(17 downto 9) * M(19 downto 12) ;
B3 := CONSX(31 downto 21) - B2(16 downto 6) ;
B4 := B3 * A(8 downto 0) ;
B <= B4(19 downto 4) ;
end if ;
end process ;
-----------------------------------------------------------
-- 3rd stage --
-----------------------------------------------------------
RSQRT_3RD : process( M, B )
variable C1 : std_logic_vector(29 downto 0); -- B(15bit)*B(15bit)
variable C2 : std_logic_vector(31 downto 0); -- M(16bit)*C1(16bit)
variable C3 : std_logic_vector(18 downto 0); -- 3-C2(19bit)
variable C4 : std_logic_vector(33 downto 0); -- B(15bit)*C3(19bit)
begin
if( B = "0000000000000000" ) then
C <= (others=>'0') ;
else
C1 := B(14 downto 0) * B(14 downto 0) ;
C2 := C1(29 downto 14) * M(19 downto 4) ;
C3 := CONSX(31 downto 13) - C2(31 downto 13) ;
C4 := C3 * B(14 downto 0) ;
C <= C4(33 downto 10) ;
end if ;
end process ;
-----------------------------------------------------------
-- 4th stage --
-----------------------------------------------------------
RSQRT_4TH : process( M, C )
variable D1 : std_logic_vector(39 downto 0); -- C(20bit)*C(20bit)
variable D2 : std_logic_vector(39 downto 0); -- M(20bit)*D1(20bit)
variable D3 : std_logic_vector(23 downto 0); -- 3-D2(24bit)
variable D4 : std_logic_vector(43 downto 0); -- C(20bit)*D3(24bit)
begin
if( C = "000000000000000000000000" ) then
D <= (others=>'0') ;
else
D1 := C(22 downto 3) * C(22 downto 3) ;
D2 := D1(39 downto 20) * M(19 downto 0) ;
D3 := CONSX(31 downto 8) - D2(39 downto 16) ;
D4 := D3 * C(22 downto 3) ;
D <= D4(43 downto 20) ;
end if ;
end process ;
ZN <= N ;
--ZM <= A & "00000000000" ;
--ZM <= B & "0000" ;
--ZM <= C(22 downto 3) ;
ZM <= D(22 downto 3) ;
end RTL ;
------------------------------------------------------------------------
-- End of File --
------------------------------------------------------------------------
|
//-------------------------------------------------------------------
//
// This file is automatically generated by VHDL to Verilog Translator.
// Ver.1.08 Build Mar.6.2004
// www.sugawara-systems.com
// tech-support@sugawara-systems.com
// See Original Copyright Notice for property of the file .( somewhere in this file.)
//
//--------------------------------------------------------------------
//----------------------------------------------------------------------
// Title Reverse Square-Root (1/sqr(X)) --
// File RSQRT.vhd --
// Entity RSQRT --
// rev date coded contents --
// 001 98/11/05 ueno Make Original --
// 002 98/11/10 ueno 4th stage up --
//----------------------------------------------------------------------
`timescale 1ns/1ns
`define ns 1
`define us (1000*`ns)
`define ms (1000*`us)
`define sec (1000*`ms)
module rsqrt ( x, zn, zm );
input [19:0] x ;
output [3:0] zn ;
output [19:0] zm ;
reg [17:0] rsqrt_1nd__b1;
reg [16:0] rsqrt_1nd__b2;
reg [10:0] rsqrt_1nd__b3;
reg [19:0] rsqrt_1nd__b4;
reg [29:0] rsqrt_3rd__c1;
reg [31:0] rsqrt_3rd__c2;
reg [18:0] rsqrt_3rd__c3;
reg [33:0] rsqrt_3rd__c4;
reg [39:0] rsqrt_4th__d1;
reg [39:0] rsqrt_4th__d2;
reg [23:0] rsqrt_4th__d3;
reg [43:0] rsqrt_4th__d4;
reg [9:0] a;
parameter [9:0] consa=10'b1000000111;
reg [15:0] b;
reg [23:0] c;
reg [23:0] d;
parameter [31:0] consx=32'b11000000000000000000000000000000;
reg [19:0] m;
reg [3:0] n;
wire [3:0] zn;
wire [19:0] zm;
always @ (x ) begin
if ((x[19:0] === 20'b00000000000000000000))
begin
m <= {(19-0+1- 0){1'b0}};
n <= {(3-0+1- 0){1'b0}};
end
else
begin
if ((x[19:2] === 18'b000000000000000000))
begin
m <= {x[1:0],18'b000000000000000000};
n <= 4'b0001;
end
else if ((x[19:4] === 16'b0000000000000000))
begin
m <= {x[3:0],16'b0000000000000000};
n <= 4'b0010;
end
else if ((x[19:6] === 14'b00000000000000))
begin
m <= {x[5:0],14'b00000000000000};
n <= 4'b0011;
end
else if ((x[19:8] === 12'b000000000000))
begin
m <= {x[7:0],12'b000000000000};
n <= 4'b0100;
end
else if ((x[19:10] === 10'b0000000000))
begin
m <= {x[9:0],10'b0000000000};
n <= 4'b0101;
end
else if ((x[19:12] === 8'b00000000))
begin
m <= {x[11:0],8'b00000000};
n <= 4'b0110;
end
else if ((x[19:14] === 6'b000000))
begin
m <= {x[13:0],6'b000000};
n <= 4'b0111;
end
else if ((x[19:16] === 4'b0000))
begin
m <= {x[15:0],4'b0000};
n <= 4'b1000;
end
else if ((x[19:18] === 2'b00))
begin
m <= {x[17:0],2'b00};
n <= 4'b1001;
end
else
begin
m <= x;
n <= 4'b1010;
end
end
end //always
always @ (m ) begin
if ((m === 20'b00000000000000000000))
a <= {(9-0+1- 0){1'b0}};
else
a <= (consa - {2'b00,m[19:12]});
end //always
always @ (m or a ) begin
if ((a === 10'b0000000000))
b <= {(15-0+1- 0){1'b0}};
else
begin
rsqrt_1nd__b1 = (a[8:0] * a[8:0]);
rsqrt_1nd__b2 = (rsqrt_1nd__b1[17:9] * m[19:12]);
rsqrt_1nd__b3 = (consx[31:21] - rsqrt_1nd__b2[16:6]);
rsqrt_1nd__b4 = (rsqrt_1nd__b3 * a[8:0]);
b <= rsqrt_1nd__b4[19:4];
end
end //always
always @ (m or b ) begin
if ((b === 16'b0000000000000000))
c <= {(23-0+1- 0){1'b0}};
else
begin
rsqrt_3rd__c1 = (b[14:0] * b[14:0]);
rsqrt_3rd__c2 = (rsqrt_3rd__c1[29:14] * m[19:4]);
rsqrt_3rd__c3 = (consx[31:13] - rsqrt_3rd__c2[31:13]);
rsqrt_3rd__c4 = (rsqrt_3rd__c3 * b[14:0]);
c <= rsqrt_3rd__c4[33:10];
end
end //always
always @ (m or c ) begin
if ((c === 24'b000000000000000000000000))
d <= {(23-0+1- 0){1'b0}};
else
begin
rsqrt_4th__d1 = (c[22:3] * c[22:3]);
rsqrt_4th__d2 = (rsqrt_4th__d1[39:20] * m[19:0]);
rsqrt_4th__d3 = (consx[31:8] - rsqrt_4th__d2[39:16]);
rsqrt_4th__d4 = (rsqrt_4th__d3 * c[22:3]);
d <= rsqrt_4th__d4[43:20];
end
end //always
assign {zn}=n;
assign {zm}=d[22:3];
endmodule
|
�S�j�t��Part�T
Z = 1/X (�A�� X>0, X=0 �̏ꍇ Z=0) ���̐��� X 20 �r�b�g�̋t�����Ƃ��H �o�͕͂��������_�`���Ŏw����(ZN) 5 �r�b�g�C������(ZM) 20 �r�b�g �ł��B
�e�X�g�x���`�ł��B
------------------------------------------------------------------------
-- Title Reverse X (1/X) --
-- File REVX.vhd --
-- Entity REVX --
-- rev date coded contents --
-- 001 98/11/10 ueno Make Original --
------------------------------------------------------------------------
library ieee ;
use ieee.std_logic_1164.all ;
use ieee.std_logic_unsigned.all ;
--use IEEE.std_logic_signed.all ;
use IEEE.std_logic_arith.all ;
------------------------------------------------------------------------
-- entity --
------------------------------------------------------------------------
entity REVX is
port(
X : in std_logic_vector(19 downto 0) ; -- Input(20bit)
ZN : out std_logic_vector(4 downto 0) ; -- Exp(5bit)
ZM : out std_logic_vector(19 downto 0) -- Man(20bit)
);
end REVX ;
------------------------------------------------------------------------
-- architecture --
------------------------------------------------------------------------
architecture RTL of REVX is
--
-- 1st stages
-- 10bit calc
-- XX.XXXXXXXX
signal A : std_logic_vector(9 downto 0) ; --
constant CONSA : std_logic_vector(9 downto 0) := "1100000000" ; -- 3
--
-- 2nd stages
-- 16bit calc
-- XX.XXXXXXXXXXXXXXXX
signal B : std_logic_vector(15 downto 0) ; --
--
-- 3rd stages
-- 24bit calc
-- XX.XXXXXXXXXXXXXXXXXXXXXX
signal C : std_logic_vector(23 downto 0) ; --
--
-- 4th stages
-- 24bit calc
-- XX.XXXXXXXXXXXXXXXXXXXXXX
signal D : std_logic_vector(23 downto 0) ; --
--
-- Constant Value
constant CONSX : std_logic_vector(31 downto 0) := "10000000000000000000000000000000" ; -- 2.0
--
--
-- 0.XXXXXXXX
signal M : std_logic_vector(19 downto 0) ; -- Mantissa
signal N : std_logic_vector(4 downto 0) ; -- Expornent
begin
--------------------------------
-- Reverse X Argolizm (X>0)
--
-- X = m x 2^n (m = 0.5~0.999999)
-- Z = 1/X = 1/m x 2^-n
-- | |
-- ZM ZN
-- --1st stage (3bit)
-- a = (3-2*m) -- a = 1~2 (3.00bit)
-- a = (723-482*m)/256 -- a = 1~2 (4.08bit)
-- --2nd stage (6bit) : xxxx LCs
-- b1 = (m*a) -- b1 = 1~1.125
-- b2 = (2-b1) -- b2 = 0.875~1
-- b3 = a*b2 -- b3 = 1~2
-- b = b3
-- --3nd stage (12bit) : xxxx LCs
-- c1 = (m*b) -- c1 = 0.98~1
-- c2 = (2-c1) -- c2 = 1~1.01
-- c3 = b*c2 -- c3 = 1~2
-- c = c4
-- --4th stage (24bit) : ???? LCs
-- d1 = (m*c) -- d1 = 0.99~1
-- d2 = (3-d1) -- d2 = 1~1.00
-- d3 = c*d2 -- d3 = 1~2
-- d = d4
--
-- ZM = d
-- ZN = n
--------------------------------
-----------------------------------------------------------
-- Initialize --
-----------------------------------------------------------
REVX_INIT : process( X )
begin
if( X(19 downto 0) = "00000000000000000000" ) then
M <= (others=>'0') ;
N <= (others=>'0') ;
else
-- Generate M,N
if( X(19 downto 1) = "0000000000000000000" ) then
M <= X(0) & "0000000000000000000" ;
N <= "00001" ;
elsif( X(19 downto 2) = "000000000000000000" ) then
M <= X(1 downto 0) & "000000000000000000" ;
N <= "00010" ;
elsif( X(19 downto 3) = "00000000000000000" ) then
M <= X(2 downto 0) & "00000000000000000" ;
N <= "00011" ;
elsif( X(19 downto 4) = "0000000000000000" ) then
M <= X(3 downto 0) & "0000000000000000" ;
N <= "00100" ;
elsif( X(19 downto 5) = "000000000000000" ) then
M <= X(4 downto 0) & "000000000000000" ;
N <= "00101" ;
elsif( X(19 downto 6) = "00000000000000" ) then
M <= X(5 downto 0) & "00000000000000" ;
N <= "00110" ;
elsif( X(19 downto 7) = "0000000000000" ) then
M <= X(6 downto 0) & "0000000000000" ;
N <= "00111" ;
elsif( X(19 downto 8) = "000000000000" ) then
M <= X(7 downto 0) & "000000000000" ;
N <= "01000" ;
elsif( X(19 downto 9) = "00000000000" ) then
M <= X(8 downto 0) & "00000000000" ;
N <= "01001" ;
elsif( X(19 downto 10) = "0000000000" ) then
M <= X(9 downto 0) & "0000000000" ;
N <= "01010" ;
elsif( X(19 downto 11) = "000000000" ) then
M <= X(10 downto 0) & "000000000" ;
N <= "01011" ;
elsif( X(19 downto 12) = "00000000" ) then
M <= X(11 downto 0) & "00000000" ;
N <= "01100" ;
elsif( X(19 downto 13) = "0000000" ) then
M <= X(12 downto 0) & "0000000" ;
N <= "01101" ;
elsif( X(19 downto 14) = "000000" ) then
M <= X(13 downto 0) & "000000" ;
N <= "01110" ;
elsif( X(19 downto 15) = "00000" ) then
M <= X(14 downto 0) & "00000" ;
N <= "01111" ;
elsif( X(19 downto 16) = "0000" ) then
M <= X(15 downto 0) & "0000" ;
N <= "10000" ;
elsif( X(19 downto 17) = "000" ) then
M <= X(16 downto 0) & "000" ;
N <= "10001" ;
elsif( X(19 downto 18) = "00" ) then
M <= X(17 downto 0) & "00" ;
N <= "10010" ;
elsif( X(19) = '0' ) then
M <= X(18 downto 0) & '0' ;
N <= "10011" ;
else
M <= X ;
N <= "10100" ;
end if ;
end if ;
end process ;
-----------------------------------------------------------
-- 1st stage --
-----------------------------------------------------------
REVX_1ST : process( M )
begin
if( M = "00000000000000000000" ) then
A <= (others=>'0') ;
else
-- A = 3-2*M
A <= CONSA - ('0' & M(19 downto 11)) ;
end if ;
end process ;
-----------------------------------------------------------
-- 2nd stage --
-----------------------------------------------------------
REVX_1ND : process( M, A )
variable B1 : std_logic_vector(19 downto 0); -- M(10bit)*A(10bit) XX.XX....
variable B2 : std_logic_vector(11 downto 0); -- 2-B1(12bit) X.XX....
variable B3 : std_logic_vector(21 downto 0); -- A(10bit)*B2(12bit) XXX.XX....
begin
if( A = "0000000000" ) then
B <= (others=>'0') ;
else
B1 := M(19 downto 10) * A ;
B2 := CONSX(30 downto 19) - B1(18 downto 7) ;
B3 := B2 * A ;
B <= B3(20 downto 5) ;
end if ;
end process ;
-----------------------------------------------------------
-- 3rd stage --
-----------------------------------------------------------
REVX_3RD : process( M, B )
variable C1 : std_logic_vector(31 downto 0); -- M(16bit)*B(16bit) XX.XX...
variable C2 : std_logic_vector(19 downto 0); -- 2-C1(20bit) X.XX...
variable C3 : std_logic_vector(35 downto 0); -- B(16bit)*C2(20bit) XXX.XX...
begin
if( B = "0000000000000000" ) then
C <= (others=>'0') ;
else
C1 := B * M(19 downto 4) ;
C2 := CONSX(30 downto 11) - C1(30 downto 11) ;
C3 := C2 * B ;
C <= C3(34 downto 11) ;
end if ;
end process ;
-----------------------------------------------------------
-- 4th stage --
-----------------------------------------------------------
REVX_4TH : process( M, C )
variable D1 : std_logic_vector(39 downto 0); -- M(20bit)*C(20bit) XX.XX...
variable D2 : std_logic_vector(23 downto 0); -- 2-D1(24bit) X.XX...
variable D3 : std_logic_vector(43 downto 0); -- C(20bit)*D2(24bit) XXX.XX...
begin
if( C = "000000000000000000000000" ) then
D <= (others=>'0') ;
else
D1 := C(23 downto 4) * M ;
D2 := CONSX(30 downto 7) - D1(38 downto 15) ;
D3 := D2 * C(23 downto 4) ;
D <= D3(42 downto 19) ;
end if ;
end process ;
ZN <= N ;
--ZM <= A & "0000000000" ;
--ZM <= B & "0000" ;
ZM <= C(23 downto 4) ;
--ZM <= D(23 downto 4) ;
end RTL ;
------------------------------------------------------------------------
-- End of File --
------------------------------------------------------------------------
|
//-------------------------------------------------------------------
//
// This file is automatically generated by VHDL to Verilog Translator.
// Ver.1.08 Build Mar.6.2004
// www.sugawara-systems.com
// tech-support@sugawara-systems.com
// See Original Copyright Notice for property of the file .( somewhere in this file.)
//
//--------------------------------------------------------------------
//----------------------------------------------------------------------
// Title Reverse X (1/X) --
// File REVX.vhd --
// Entity REVX --
// rev date coded contents --
// 001 98/11/10 ueno Make Original --
//----------------------------------------------------------------------
`timescale 1ns/1ns
`define ns 1
`define us (1000*`ns)
`define ms (1000*`us)
`define sec (1000*`ms)
module revx ( x, zn, zm );
input [19:0] x ;
output [4:0] zn ;
output [19:0] zm ;
reg [19:0] revx_1nd__b1;
reg [11:0] revx_1nd__b2;
reg [21:0] revx_1nd__b3;
reg [31:0] revx_3rd__c1;
reg [19:0] revx_3rd__c2;
reg [35:0] revx_3rd__c3;
reg [39:0] revx_4th__d1;
reg [23:0] revx_4th__d2;
reg [43:0] revx_4th__d3;
reg [9:0] a;
parameter [9:0] consa=10'b1100000000;
reg [15:0] b;
reg [23:0] c;
reg [23:0] d;
parameter [31:0] consx=32'b10000000000000000000000000000000;
reg [19:0] m;
reg [4:0] n;
wire [4:0] zn;
wire [19:0] zm;
always @ (x ) begin
if ((x[19:0] === 20'b00000000000000000000))
begin
m <= {(19-0+1- 0){1'b0}};
n <= {(4-0+1- 0){1'b0}};
end
else
begin
if ((x[19:1] === 19'b0000000000000000000))
begin
m <= {x[0],19'b0000000000000000000};
n <= 5'b00001;
end
else if ((x[19:2] === 18'b000000000000000000))
begin
m <= {x[1:0],18'b000000000000000000};
n <= 5'b00010;
end
else if ((x[19:3] === 17'b00000000000000000))
begin
m <= {x[2:0],17'b00000000000000000};
n <= 5'b00011;
end
else if ((x[19:4] === 16'b0000000000000000))
begin
m <= {x[3:0],16'b0000000000000000};
n <= 5'b00100;
end
else if ((x[19:5] === 15'b000000000000000))
begin
m <= {x[4:0],15'b000000000000000};
n <= 5'b00101;
end
else if ((x[19:6] === 14'b00000000000000))
begin
m <= {x[5:0],14'b00000000000000};
n <= 5'b00110;
end
else if ((x[19:7] === 13'b0000000000000))
begin
m <= {x[6:0],13'b0000000000000};
n <= 5'b00111;
end
else if ((x[19:8] === 12'b000000000000))
begin
m <= {x[7:0],12'b000000000000};
n <= 5'b01000;
end
else if ((x[19:9] === 11'b00000000000))
begin
m <= {x[8:0],11'b00000000000};
n <= 5'b01001;
end
else if ((x[19:10] === 10'b0000000000))
begin
m <= {x[9:0],10'b0000000000};
n <= 5'b01010;
end
else if ((x[19:11] === 9'b000000000))
begin
m <= {x[10:0],9'b000000000};
n <= 5'b01011;
end
else if ((x[19:12] === 8'b00000000))
begin
m <= {x[11:0],8'b00000000};
n <= 5'b01100;
end
else if ((x[19:13] === 7'b0000000))
begin
m <= {x[12:0],7'b0000000};
n <= 5'b01101;
end
else if ((x[19:14] === 6'b000000))
begin
m <= {x[13:0],6'b000000};
n <= 5'b01110;
end
else if ((x[19:15] === 5'b00000))
begin
m <= {x[14:0],5'b00000};
n <= 5'b01111;
end
else if ((x[19:16] === 4'b0000))
begin
m <= {x[15:0],4'b0000};
n <= 5'b10000;
end
else if ((x[19:17] === 3'b000))
begin
m <= {x[16:0],3'b000};
n <= 5'b10001;
end
else if ((x[19:18] === 2'b00))
begin
m <= {x[17:0],2'b00};
n <= 5'b10010;
end
else if ((x[19] === 1'b0))
begin
m <= {x[18:0],1'b0};
n <= 5'b10011;
end
else
begin
m <= x;
n <= 5'b10100;
end
end
end //always
always @ (m ) begin
if ((m === 20'b00000000000000000000))
a <= {(9-0+1- 0){1'b0}};
else
a <= (consa - {1'b0,m[19:11]});
end //always
always @ (m or a ) begin
if ((a === 10'b0000000000))
b <= {(15-0+1- 0){1'b0}};
else
begin
revx_1nd__b1 = (m[19:10] * a);
revx_1nd__b2 = (consx[30:19] - revx_1nd__b1[18:7]);
revx_1nd__b3 = (revx_1nd__b2 * a);
b <= revx_1nd__b3[20:5];
end
end //always
always @ (m or b ) begin
if ((b === 16'b0000000000000000))
c <= {(23-0+1- 0){1'b0}};
else
begin
revx_3rd__c1 = (b * m[19:4]);
revx_3rd__c2 = (consx[30:11] - revx_3rd__c1[30:11]);
revx_3rd__c3 = (revx_3rd__c2 * b);
c <= revx_3rd__c3[34:11];
end
end //always
always @ (m or c ) begin
if ((c === 24'b000000000000000000000000))
d <= {(23-0+1- 0){1'b0}};
else
begin
revx_4th__d1 = (c[23:4] * m);
revx_4th__d2 = (consx[30:7] - revx_4th__d1[38:15]);
revx_4th__d3 = (revx_4th__d2 * c[23:4]);
d <= revx_4th__d3[42:19];
end
end //always
assign {zn}=n;
assign {zm}=c[23:4];
endmodule
|
Z = 1/X (�A�� X>0, X=0 �̏ꍇ Z=0) ���̐��� X 20 �r�b�g�̋t�����Ƃ��H �o�͕͂��������_�`���Ŏw����(ZN) 5 �r�b�g�C������(ZM) 20 �r�b�g �ł��B
�e�X�g�x���`�ł��B�p�[�g�T�Ƃ̈Ⴂ�́A���x�ł��B
------------------------------------------------------------------------
-- Title Reverse X (1/X) --
-- File REVX.vhd --
-- Entity REVX --
-- rev date coded contents --
-- 001 98/11/10 ueno Make Original --
------------------------------------------------------------------------
library ieee ;
use ieee.std_logic_1164.all ;
use ieee.std_logic_unsigned.all ;
--use IEEE.std_logic_signed.all ;
use IEEE.std_logic_arith.all ;
------------------------------------------------------------------------
-- entity --
------------------------------------------------------------------------
entity REVX is
port(
X : in std_logic_vector(19 downto 0) ; -- Input(20bit)
ZN : out std_logic_vector(4 downto 0) ; -- Exp(5bit)
ZM : out std_logic_vector(19 downto 0) -- Man(20bit)
);
end REVX ;
------------------------------------------------------------------------
-- architecture --
------------------------------------------------------------------------
architecture RTL of REVX is
--
-- 1st stages
-- 10bit calc
-- XX.XXXXXXXX
signal A : std_logic_vector(9 downto 0) ; --
constant CONSA : std_logic_vector(9 downto 0) := "1100000000" ; -- 3
--
-- 2nd stages
-- 16bit calc
-- XX.XXXXXXXXXXXXXXXX
signal B : std_logic_vector(15 downto 0) ; --
--
-- 3rd stages
-- 24bit calc
-- XX.XXXXXXXXXXXXXXXXXXXXXX
signal C : std_logic_vector(23 downto 0) ; --
--
-- 4th stages
-- 24bit calc
-- XX.XXXXXXXXXXXXXXXXXXXXXX
signal D : std_logic_vector(23 downto 0) ; --
--
-- Constant Value
constant CONSX : std_logic_vector(31 downto 0) := "10000000000000000000000000000000" ; -- 2.0
--
--
-- 0.XXXXXXXX
signal M : std_logic_vector(19 downto 0) ; -- Mantissa
signal N : std_logic_vector(4 downto 0) ; -- Expornent
begin
--------------------------------
-- Reverse X Argolizm (X>0)
--
-- X = m x 2^n (m = 0.5~0.999999)
-- Z = 1/X = 1/m x 2^-n
-- | |
-- ZM ZN
-- --1st stage (3bit)
-- a = (3-2*m) -- a = 1~2 (3.00bit)
-- a = (723-482*m)/256 -- a = 1~2 (4.08bit)
-- --2nd stage (6bit) : xxxx LCs
-- b1 = (m*a) -- b1 = 1~1.125
-- b2 = (2-b1) -- b2 = 0.875~1
-- b3 = a*b2 -- b3 = 1~2
-- b = b3
-- --3nd stage (12bit) : xxxx LCs
-- c1 = (m*b) -- c1 = 0.98~1
-- c2 = (2-c1) -- c2 = 1~1.01
-- c3 = b*c2 -- c3 = 1~2
-- c = c4
-- --4th stage (24bit) : ???? LCs
-- d1 = (m*c) -- d1 = 0.99~1
-- d2 = (3-d1) -- d2 = 1~1.00
-- d3 = c*d2 -- d3 = 1~2
-- d = d4
--
-- ZM = d
-- ZN = n
--------------------------------
-----------------------------------------------------------
-- Initialize --
-----------------------------------------------------------
REVX_INIT : process( X )
begin
if( X(19 downto 0) = "00000000000000000000" ) then
M <= (others=>'0') ;
N <= (others=>'0') ;
else
-- Generate M,N
if( X(19 downto 1) = "0000000000000000000" ) then
M <= X(0) & "0000000000000000000" ;
N <= "00001" ;
elsif( X(19 downto 2) = "000000000000000000" ) then
M <= X(1 downto 0) & "000000000000000000" ;
N <= "00010" ;
elsif( X(19 downto 3) = "00000000000000000" ) then
M <= X(2 downto 0) & "00000000000000000" ;
N <= "00011" ;
elsif( X(19 downto 4) = "0000000000000000" ) then
M <= X(3 downto 0) & "0000000000000000" ;
N <= "00100" ;
elsif( X(19 downto 5) = "000000000000000" ) then
M <= X(4 downto 0) & "000000000000000" ;
N <= "00101" ;
elsif( X(19 downto 6) = "00000000000000" ) then
M <= X(5 downto 0) & "00000000000000" ;
N <= "00110" ;
elsif( X(19 downto 7) = "0000000000000" ) then
M <= X(6 downto 0) & "0000000000000" ;
N <= "00111" ;
elsif( X(19 downto 8) = "000000000000" ) then
M <= X(7 downto 0) & "000000000000" ;
N <= "01000" ;
elsif( X(19 downto 9) = "00000000000" ) then
M <= X(8 downto 0) & "00000000000" ;
N <= "01001" ;
elsif( X(19 downto 10) = "0000000000" ) then
M <= X(9 downto 0) & "0000000000" ;
N <= "01010" ;
elsif( X(19 downto 11) = "000000000" ) then
M <= X(10 downto 0) & "000000000" ;
N <= "01011" ;
elsif( X(19 downto 12) = "00000000" ) then
M <= X(11 downto 0) & "00000000" ;
N <= "01100" ;
elsif( X(19 downto 13) = "0000000" ) then
M <= X(12 downto 0) & "0000000" ;
N <= "01101" ;
elsif( X(19 downto 14) = "000000" ) then
M <= X(13 downto 0) & "000000" ;
N <= "01110" ;
elsif( X(19 downto 15) = "00000" ) then
M <= X(14 downto 0) & "00000" ;
N <= "01111" ;
elsif( X(19 downto 16) = "0000" ) then
M <= X(15 downto 0) & "0000" ;
N <= "10000" ;
elsif( X(19 downto 17) = "000" ) then
M <= X(16 downto 0) & "000" ;
N <= "10001" ;
elsif( X(19 downto 18) = "00" ) then
M <= X(17 downto 0) & "00" ;
N <= "10010" ;
elsif( X(19) = '0' ) then
M <= X(18 downto 0) & '0' ;
N <= "10011" ;
else
M <= X ;
N <= "10100" ;
end if ;
end if ;
end process ;
-----------------------------------------------------------
-- 1st stage --
-----------------------------------------------------------
REVX_1ST : process( M )
begin
if( M = "00000000000000000000" ) then
A <= (others=>'0') ;
else
-- A = 3-2*M
A <= CONSA - ('0' & M(19 downto 11)) ;
end if ;
end process ;
-----------------------------------------------------------
-- 2nd stage --
-----------------------------------------------------------
REVX_1ND : process( M, A )
variable B1 : std_logic_vector(19 downto 0); -- M(10bit)*A(10bit) XX.XX....
variable B2 : std_logic_vector(11 downto 0); -- 2-B1(12bit) X.XX....
variable B3 : std_logic_vector(21 downto 0); -- A(10bit)*B2(12bit) XXX.XX....
begin
if( A = "0000000000" ) then
B <= (others=>'0') ;
else
B1 := M(19 downto 10) * A ;
B2 := CONSX(30 downto 19) - B1(18 downto 7) ;
B3 := B2 * A ;
B <= B3(20 downto 5) ;
end if ;
end process ;
-----------------------------------------------------------
-- 3rd stage --
-----------------------------------------------------------
REVX_3RD : process( M, B )
variable C1 : std_logic_vector(31 downto 0); -- M(16bit)*B(16bit) XX.XX...
variable C2 : std_logic_vector(19 downto 0); -- 2-C1(20bit) X.XX...
variable C3 : std_logic_vector(35 downto 0); -- B(16bit)*C2(20bit) XXX.XX...
begin
if( B = "0000000000000000" ) then
C <= (others=>'0') ;
else
C1 := B * M(19 downto 4) ;
C2 := CONSX(30 downto 11) - C1(30 downto 11) ;
C3 := C2 * B ;
C <= C3(34 downto 11) ;
end if ;
end process ;
-----------------------------------------------------------
-- 4th stage --
-----------------------------------------------------------
REVX_4TH : process( M, C )
variable D1 : std_logic_vector(39 downto 0); -- M(20bit)*C(20bit) XX.XX...
variable D2 : std_logic_vector(23 downto 0); -- 2-D1(24bit) X.XX...
variable D3 : std_logic_vector(43 downto 0); -- C(20bit)*D2(24bit) XXX.XX...
begin
if( C = "000000000000000000000000" ) then
D <= (others=>'0') ;
else
D1 := C(23 downto 4) * M ;
D2 := CONSX(30 downto 7) - D1(38 downto 15) ;
D3 := D2 * C(23 downto 4) ;
D <= D3(42 downto 19) ;
end if ;
end process ;
ZN <= N ;
--ZM <= A & "0000000000" ;
--ZM <= B & "0000" ;
--ZM <= C(23 downto 4) ;
ZM <= D(23 downto 4) ;
end RTL ;
------------------------------------------------------------------------
-- End of File --
------------------------------------------------------------------------
|
//-------------------------------------------------------------------
//
// This file is automatically generated by VHDL to Verilog Translator.
// Ver.1.08 Build Mar.6.2004
// www.sugawara-systems.com
// tech-support@sugawara-systems.com
// See Original Copyright Notice for property of the file .( somewhere in this file.)
//
//--------------------------------------------------------------------
//----------------------------------------------------------------------
// Title Reverse X (1/X) --
// File REVX.vhd --
// Entity REVX --
// rev date coded contents --
// 001 98/11/10 ueno Make Original --
//----------------------------------------------------------------------
`timescale 1ns/1ns
`define ns 1
`define us (1000*`ns)
`define ms (1000*`us)
`define sec (1000*`ms)
module revx ( x, zn, zm );
input [19:0] x ;
output [4:0] zn ;
output [19:0] zm ;
reg [19:0] revx_1nd__b1;
reg [11:0] revx_1nd__b2;
reg [21:0] revx_1nd__b3;
reg [31:0] revx_3rd__c1;
reg [19:0] revx_3rd__c2;
reg [35:0] revx_3rd__c3;
reg [39:0] revx_4th__d1;
reg [23:0] revx_4th__d2;
reg [43:0] revx_4th__d3;
reg [9:0] a;
parameter [9:0] consa=10'b1100000000;
reg [15:0] b;
reg [23:0] c;
reg [23:0] d;
parameter [31:0] consx=32'b10000000000000000000000000000000;
reg [19:0] m;
reg [4:0] n;
wire [4:0] zn;
wire [19:0] zm;
always @ (x ) begin
if ((x[19:0] === 20'b00000000000000000000))
begin
m <= {(19-0+1- 0){1'b0}};
n <= {(4-0+1- 0){1'b0}};
end
else
begin
if ((x[19:1] === 19'b0000000000000000000))
begin
m <= {x[0],19'b0000000000000000000};
n <= 5'b00001;
end
else if ((x[19:2] === 18'b000000000000000000))
begin
m <= {x[1:0],18'b000000000000000000};
n <= 5'b00010;
end
else if ((x[19:3] === 17'b00000000000000000))
begin
m <= {x[2:0],17'b00000000000000000};
n <= 5'b00011;
end
else if ((x[19:4] === 16'b0000000000000000))
begin
m <= {x[3:0],16'b0000000000000000};
n <= 5'b00100;
end
else if ((x[19:5] === 15'b000000000000000))
begin
m <= {x[4:0],15'b000000000000000};
n <= 5'b00101;
end
else if ((x[19:6] === 14'b00000000000000))
begin
m <= {x[5:0],14'b00000000000000};
n <= 5'b00110;
end
else if ((x[19:7] === 13'b0000000000000))
begin
m <= {x[6:0],13'b0000000000000};
n <= 5'b00111;
end
else if ((x[19:8] === 12'b000000000000))
begin
m <= {x[7:0],12'b000000000000};
n <= 5'b01000;
end
else if ((x[19:9] === 11'b00000000000))
begin
m <= {x[8:0],11'b00000000000};
n <= 5'b01001;
end
else if ((x[19:10] === 10'b0000000000))
begin
m <= {x[9:0],10'b0000000000};
n <= 5'b01010;
end
else if ((x[19:11] === 9'b000000000))
begin
m <= {x[10:0],9'b000000000};
n <= 5'b01011;
end
else if ((x[19:12] === 8'b00000000))
begin
m <= {x[11:0],8'b00000000};
n <= 5'b01100;
end
else if ((x[19:13] === 7'b0000000))
begin
m <= {x[12:0],7'b0000000};
n <= 5'b01101;
end
else if ((x[19:14] === 6'b000000))
begin
m <= {x[13:0],6'b000000};
n <= 5'b01110;
end
else if ((x[19:15] === 5'b00000))
begin
m <= {x[14:0],5'b00000};
n <= 5'b01111;
end
else if ((x[19:16] === 4'b0000))
begin
m <= {x[15:0],4'b0000};
n <= 5'b10000;
end
else if ((x[19:17] === 3'b000))
begin
m <= {x[16:0],3'b000};
n <= 5'b10001;
end
else if ((x[19:18] === 2'b00))
begin
m <= {x[17:0],2'b00};
n <= 5'b10010;
end
else if ((x[19] === 1'b0))
begin
m <= {x[18:0],1'b0};
n <= 5'b10011;
end
else
begin
m <= x;
n <= 5'b10100;
end
end
end //always
always @ (m ) begin
if ((m === 20'b00000000000000000000))
a <= {(9-0+1- 0){1'b0}};
else
a <= (consa - {1'b0,m[19:11]});
end //always
always @ (m or a ) begin
if ((a === 10'b0000000000))
b <= {(15-0+1- 0){1'b0}};
else
begin
revx_1nd__b1 = (m[19:10] * a);
revx_1nd__b2 = (consx[30:19] - revx_1nd__b1[18:7]);
revx_1nd__b3 = (revx_1nd__b2 * a);
b <= revx_1nd__b3[20:5];
end
end //always
always @ (m or b ) begin
if ((b === 16'b0000000000000000))
c <= {(23-0+1- 0){1'b0}};
else
begin
revx_3rd__c1 = (b * m[19:4]);
revx_3rd__c2 = (consx[30:11] - revx_3rd__c1[30:11]);
revx_3rd__c3 = (revx_3rd__c2 * b);
c <= revx_3rd__c3[34:11];
end
end //always
always @ (m or c ) begin
if ((c === 24'b000000000000000000000000))
d <= {(23-0+1- 0){1'b0}};
else
begin
revx_4th__d1 = (c[23:4] * m);
revx_4th__d2 = (consx[30:7] - revx_4th__d1[38:15]);
revx_4th__d3 = (revx_4th__d2 * c[23:4]);
d <= revx_4th__d3[42:19];
end
end //always
assign {zn}=n;
assign {zm}=d[23:4];
endmodule
|
�U�j���R�ΐ�
Z = log(X) (�A�� X>0, X=0 �̏ꍇ Z=0) ���̐��� X 20 �r�b�g�̎��R�ΐ����Ƃ��H �o�͂͌Œ菬���_�`���Ő����� 4 �r�b�g�C������ 16 �r�b�g
------------------------------------------------------------------------
-- Title Logalizm X (log(X)) --
-- File LOG.vhd --
-- Entity LOG --
-- rev date coded contents --
-- 001 98/11/17 ueno Make Original --
------------------------------------------------------------------------
library ieee ;
use ieee.std_logic_1164.all ;
use ieee.std_logic_unsigned.all ;
--use IEEE.std_logic_signed.all ;
use IEEE.std_logic_arith.all ;
------------------------------------------------------------------------
-- entity --
------------------------------------------------------------------------
entity LOG is
port(
-- XXXXXXXXXXXXXXXXXXXX. Integer Value
X : in std_logic_vector(19 downto 0) ; -- Input(20bit)
-- XXXX.XXXXXXXXXXXXXXXX Fixed Point Value
Z : out std_logic_vector(19 downto 0) -- Output(20bit)
);
end LOG ;
------------------------------------------------------------------------
-- architecture --
------------------------------------------------------------------------
architecture RTL of LOG is
-- log(2)
-- .XXXXXXXXXXXXXXXX
constant LOG2V : std_logic_vector(15 downto 0) := "1011000101110010" ;
-- 1/2 = shift1
-- 1/3
constant CONS3 : std_logic_vector(15 downto 0) := "0101010101010101" ; -- 4bit
-- 1/4 = shift2
-- 1/5
-- 1/6 = 1/3&shift
-- 1/7
constant CONS5 : std_logic_vector(15 downto 0) := "0011001100110011" ; -- 7bit
constant CONS7 : std_logic_vector(15 downto 0) := "0010010010010010" ; -- 9bit
-- 1/8 = shift3
-- 1/9
-- 1/10 = 1/5&shift
-- 1/11
-- 1/12 = 1/3&shift2
-- 1/13
-- 1/14 = 1/7&shift2
-- 1/15
constant CONS9 : std_logic_vector(15 downto 0) := "0001110001110001" ; -- 11bit
constant CONS11 : std_logic_vector(15 downto 0) := "0001011101000101" ; -- 14bit
constant CONS13 : std_logic_vector(15 downto 0) := "0001001110110001" ; -- 16bit
constant CONS15 : std_logic_vector(15 downto 0) := "0001000100010001" ; -- 18bit
--
-- .XXXXXXXXXXXXXXXX
signal Y : std_logic_vector(15 downto 0) ; -- Log( M )
--
signal F : std_logic_vector(20 downto 0) ; -- N*log(2)
signal G : std_logic_vector(20 downto 0) ; -- temp Z
--
-- 0.XXXXXXXX
signal M : std_logic_vector(19 downto 0) ; -- Mantissa
signal N : std_logic_vector(4 downto 0) ; -- Expornent
begin
--------------------------------
-- Reverse X Argolizm (X>0)
--
-- X = m x 2^n (m = 0.5~0.999999)
-- m = 1-h
-- Z = log(2)*n+log(m)
-- log(2)*n-(h+h^2/2+h^3/3+h^4/4+ ....)
--
--------------------------------
-----------------------------------------------------------
-- Initialize --
-----------------------------------------------------------
FLOT_INIT : process( X )
begin
if( X(19 downto 0) = "00000000000000000000" ) then
M <= (others=>'0') ;
N <= (others=>'0') ;
else
-- Generate M,N
if( X(19 downto 1) = "0000000000000000000" ) then
M <= X(0) & "0000000000000000000" ;
N <= "00001" ;
elsif( X(19 downto 2) = "000000000000000000" ) then
M <= X(1 downto 0) & "000000000000000000" ;
N <= "00010" ;
elsif( X(19 downto 3) = "00000000000000000" ) then
M <= X(2 downto 0) & "00000000000000000" ;
N <= "00011" ;
elsif( X(19 downto 4) = "0000000000000000" ) then
M <= X(3 downto 0) & "0000000000000000" ;
N <= "00100" ;
elsif( X(19 downto 5) = "000000000000000" ) then
M <= X(4 downto 0) & "000000000000000" ;
N <= "00101" ;
elsif( X(19 downto 6) = "00000000000000" ) then
M <= X(5 downto 0) & "00000000000000" ;
N <= "00110" ;
elsif( X(19 downto 7) = "0000000000000" ) then
M <= X(6 downto 0) & "0000000000000" ;
N <= "00111" ;
elsif( X(19 downto 8) = "000000000000" ) then
M <= X(7 downto 0) & "000000000000" ;
N <= "01000" ;
elsif( X(19 downto 9) = "00000000000" ) then
M <= X(8 downto 0) & "00000000000" ;
N <= "01001" ;
elsif( X(19 downto 10) = "0000000000" ) then
M <= X(9 downto 0) & "0000000000" ;
N <= "01010" ;
elsif( X(19 downto 11) = "000000000" ) then
M <= X(10 downto 0) & "000000000" ;
N <= "01011" ;
elsif( X(19 downto 12) = "00000000" ) then
M <= X(11 downto 0) & "00000000" ;
N <= "01100" ;
elsif( X(19 downto 13) = "0000000" ) then
M <= X(12 downto 0) & "0000000" ;
N <= "01101" ;
elsif( X(19 downto 14) = "000000" ) then
M <= X(13 downto 0) & "000000" ;
N <= "01110" ;
elsif( X(19 downto 15) = "00000" ) then
M <= X(14 downto 0) & "00000" ;
N <= "01111" ;
elsif( X(19 downto 16) = "0000" ) then
M <= X(15 downto 0) & "0000" ;
N <= "10000" ;
elsif( X(19 downto 17) = "000" ) then
M <= X(16 downto 0) & "000" ;
N <= "10001" ;
elsif( X(19 downto 18) = "00" ) then
M <= X(17 downto 0) & "00" ;
N <= "10010" ;
elsif( X(19) = '0' ) then
M <= X(18 downto 0) & '0' ;
N <= "10011" ;
else
M <= X ;
N <= "10100" ;
end if ;
end if ;
end process ;
-----------------------------------------------------------
-- logalizm calculate --
-----------------------------------------------------------
LOG_CONV : process( M )
variable TMP : std_logic_vector(19 downto 0); -- 1-m
variable H : std_logic_vector(15 downto 0); -- 1-m
variable B1 : std_logic_vector(15 downto 0); -- H
variable B2 : std_logic_vector(31 downto 0); -- H^2
variable B3 : std_logic_vector(31 downto 0); -- H^3
variable B4 : std_logic_vector(31 downto 0); -- H^4
variable B5 : std_logic_vector(31 downto 0); --
variable B6 : std_logic_vector(31 downto 0); --
variable B7 : std_logic_vector(31 downto 0); --
variable B8 : std_logic_vector(31 downto 0); --
variable B9 : std_logic_vector(31 downto 0); --
variable B10 : std_logic_vector(31 downto 0); --
variable B11 : std_logic_vector(31 downto 0); --
variable B12 : std_logic_vector(31 downto 0); --
variable B13 : std_logic_vector(31 downto 0); --
variable C1 : std_logic_vector(15 downto 0); -- H
variable C2 : std_logic_vector(15 downto 0); -- H^2
variable C3 : std_logic_vector(15 downto 0); -- H^3
variable C4 : std_logic_vector(15 downto 0); -- H^4
variable C5 : std_logic_vector(15 downto 0); --
variable C6 : std_logic_vector(15 downto 0); --
variable C7 : std_logic_vector(15 downto 0); --
variable C8 : std_logic_vector(15 downto 0); --
variable C9 : std_logic_vector(15 downto 0); --
variable C10 : std_logic_vector(15 downto 0); --
variable C11 : std_logic_vector(15 downto 0); --
variable C12 : std_logic_vector(15 downto 0); --
variable C13 : std_logic_vector(15 downto 0); --
variable D : std_logic_vector(15 downto 0); --
begin
if( M = "00000000000000000000" ) then
Y <= (others=>'0') ;
else
-- TMP = -M
TMP := "00000000000000000000" - M ;
H := TMP(19 downto 4) ;
-- BEKI
B1 := H ;
B2 := H*H ;
B3 := B2(31 downto 16)*H ;
B4 := B2(31 downto 16)*B2(31 downto 16) ;
B5 := B4(31 downto 16)*H ;
B6 := B4(31 downto 16)*B2(31 downto 16) ;
B7 := B4(31 downto 16)*B3(31 downto 16) ;
B8 := B4(31 downto 16)*B4(31 downto 16) ;
B9 := B8(31 downto 16)*H ;
B10 := B8(31 downto 16)*B2(31 downto 16) ;
B11 := B8(31 downto 16)*B3(31 downto 16) ;
B12 := B8(31 downto 16)*B4(31 downto 16) ;
B13 := B8(31 downto 16)*B5(31 downto 16) ;
-- KEISU
C1 := B1 ;
C2 := '0' & B2(31 downto 17) ;
B3 := B3(31 downto 16)*CONS3 ;
C3 := B3(31 downto 16) ;
C4 := "00" & B4(31 downto 18) ;
B5 := B5(31 downto 16)*CONS5 ;
C5 := B5(31 downto 16) ;
B6 := B6(31 downto 16)*CONS3 ;
C6 := '0' & B6(31 downto 17) ;
B7 := B7(31 downto 16)*CONS7 ;
C7 := B7(31 downto 16) ;
C8 := "000" & B8(31 downto 19) ;
B9 := B9(31 downto 16)*CONS9 ;
C9 := B9(31 downto 16) ;
B10 := B10(31 downto 16)*CONS5 ;
C10 := '0' & B10(31 downto 17) ;
B11 := B11(31 downto 16)*CONS11 ;
C11 := B11(31 downto 16) ;
B12 := B12(31 downto 16)*CONS3 ;
C12 := "00" & B12(31 downto 18) ;
B13 := B13(31 downto 16)*CONS13 ;
C13 := B13(31 downto 16) ;
-- KASAN
D := C1+C2+C3+C4+C5+C6+C7+C8+C9+C10+C11+C12+C13 ;
-- KEKKA
Y <= D ;
end if ;
end process ;
-----------------------------------------------------------
-- output calculate --
-----------------------------------------------------------
--Feb.14.2005 TAK
OUTPUT_CALC : process( M,G) -- N, Y )
begin
if( M = "00000000000000000000" ) then
Z <= (others=>'0') ;
else
-- F <= N * LOG2V ;
-- G <= F - ("00000" & Y) ;
Z <= G(19 downto 0) ;
end if ;
end process ;
F <= N * LOG2V ;
G <= F - ("00000" & Y) ;
end RTL ;
------------------------------------------------------------------------
-- End of File --
------------------------------------------------------------------------
|
//-------------------------------------------------------------------
//
// This file is automatically generated by VHDL to Verilog Translator.
// Ver.1.08 Build Mar.6.2004
// www.sugawara-systems.com
// tech-support@sugawara-systems.com
// See Original Copyright Notice for property of the file .( somewhere in this file.)
//
//--------------------------------------------------------------------
//----------------------------------------------------------------------
// Title Logalizm X (log(X)) --
// File LOG.vhd --
// Entity LOG --
// rev date coded contents --
// 001 98/11/17 ueno Make Original --
//----------------------------------------------------------------------
`timescale 1ns/1ns
`define ns 1
`define us (1000*`ns)
`define ms (1000*`us)
`define sec (1000*`ms)
module log ( x, z );
input [19:0] x ;
output [19:0] z ;
reg [19:0] log_conv__tmp;
reg [15:0] log_conv__h;
reg [15:0] log_conv__b1;
reg [31:0] log_conv__b2;
reg [31:0] log_conv__b3;
reg [31:0] log_conv__b4;
reg [31:0] log_conv__b5;
reg [31:0] log_conv__b6;
reg [31:0] log_conv__b7;
reg [31:0] log_conv__b8;
reg [31:0] log_conv__b9;
reg [31:0] log_conv__b10;
reg [31:0] log_conv__b11;
reg [31:0] log_conv__b12;
reg [31:0] log_conv__b13;
reg [15:0] log_conv__c1;
reg [15:0] log_conv__c2;
reg [15:0] log_conv__c3;
reg [15:0] log_conv__c4;
reg [15:0] log_conv__c5;
reg [15:0] log_conv__c6;
reg [15:0] log_conv__c7;
reg [15:0] log_conv__c8;
reg [15:0] log_conv__c9;
reg [15:0] log_conv__c10;
reg [15:0] log_conv__c11;
reg [15:0] log_conv__c12;
reg [15:0] log_conv__c13;
reg [15:0] log_conv__d;
parameter [15:0] log2v=16'b1011000101110010;
parameter [15:0] cons3=16'b0101010101010101;
parameter [15:0] cons5=16'b0011001100110011;
parameter [15:0] cons7=16'b0010010010010010;
parameter [15:0] cons9=16'b0001110001110001;
parameter [15:0] cons11=16'b0001011101000101;
parameter [15:0] cons13=16'b0001001110110001;
parameter [15:0] cons15=16'b0001000100010001;
reg [15:0] y;
wire [20:0] f;
wire [20:0] g;
reg [19:0] m;
reg [4:0] n;
reg [19:0] z;
always @ (x ) begin
if ((x[19:0] === 20'b00000000000000000000))
begin
m <= {(19-0+1- 0){1'b0}};
n <= {(4-0+1- 0){1'b0}};
end
else
begin
if ((x[19:1] === 19'b0000000000000000000))
begin
m <= {x[0],19'b0000000000000000000};
n <= 5'b00001;
end
else if ((x[19:2] === 18'b000000000000000000))
begin
m <= {x[1:0],18'b000000000000000000};
n <= 5'b00010;
end
else if ((x[19:3] === 17'b00000000000000000))
begin
m <= {x[2:0],17'b00000000000000000};
n <= 5'b00011;
end
else if ((x[19:4] === 16'b0000000000000000))
begin
m <= {x[3:0],16'b0000000000000000};
n <= 5'b00100;
end
else if ((x[19:5] === 15'b000000000000000))
begin
m <= {x[4:0],15'b000000000000000};
n <= 5'b00101;
end
else if ((x[19:6] === 14'b00000000000000))
begin
m <= {x[5:0],14'b00000000000000};
n <= 5'b00110;
end
else if ((x[19:7] === 13'b0000000000000))
begin
m <= {x[6:0],13'b0000000000000};
n <= 5'b00111;
end
else if ((x[19:8] === 12'b000000000000))
begin
m <= {x[7:0],12'b000000000000};
n <= 5'b01000;
end
else if ((x[19:9] === 11'b00000000000))
begin
m <= {x[8:0],11'b00000000000};
n <= 5'b01001;
end
else if ((x[19:10] === 10'b0000000000))
begin
m <= {x[9:0],10'b0000000000};
n <= 5'b01010;
end
else if ((x[19:11] === 9'b000000000))
begin
m <= {x[10:0],9'b000000000};
n <= 5'b01011;
end
else if ((x[19:12] === 8'b00000000))
begin
m <= {x[11:0],8'b00000000};
n <= 5'b01100;
end
else if ((x[19:13] === 7'b0000000))
begin
m <= {x[12:0],7'b0000000};
n <= 5'b01101;
end
else if ((x[19:14] === 6'b000000))
begin
m <= {x[13:0],6'b000000};
n <= 5'b01110;
end
else if ((x[19:15] === 5'b00000))
begin
m <= {x[14:0],5'b00000};
n <= 5'b01111;
end
else if ((x[19:16] === 4'b0000))
begin
m <= {x[15:0],4'b0000};
n <= 5'b10000;
end
else if ((x[19:17] === 3'b000))
begin
m <= {x[16:0],3'b000};
n <= 5'b10001;
end
else if ((x[19:18] === 2'b00))
begin
m <= {x[17:0],2'b00};
n <= 5'b10010;
end
else if ((x[19] === 1'b0))
begin
m <= {x[18:0],1'b0};
n <= 5'b10011;
end
else
begin
m <= x;
n <= 5'b10100;
end
end
end //always
always @ (m ) begin
if ((m === 20'b00000000000000000000))
y <= {(15-0+1- 0){1'b0}};
else
begin
log_conv__tmp = (20'b00000000000000000000 - m);
log_conv__h = log_conv__tmp[19:4];
log_conv__b1 = log_conv__h;
log_conv__b2 = (log_conv__h * log_conv__h);
log_conv__b3 = (log_conv__b2[31:16] * log_conv__h);
log_conv__b4 = (log_conv__b2[31:16] * log_conv__b2[31:16]);
log_conv__b5 = (log_conv__b4[31:16] * log_conv__h);
log_conv__b6 = (log_conv__b4[31:16] * log_conv__b2[31:16]);
log_conv__b7 = (log_conv__b4[31:16] * log_conv__b3[31:16]);
log_conv__b8 = (log_conv__b4[31:16] * log_conv__b4[31:16]);
log_conv__b9 = (log_conv__b8[31:16] * log_conv__h);
log_conv__b10 = (log_conv__b8[31:16] * log_conv__b2[31:16]);
log_conv__b11 = (log_conv__b8[31:16] * log_conv__b3[31:16]);
log_conv__b12 = (log_conv__b8[31:16] * log_conv__b4[31:16]);
log_conv__b13 = (log_conv__b8[31:16] * log_conv__b5[31:16]);
log_conv__c1 = log_conv__b1;
log_conv__c2 = {1'b0,log_conv__b2[31:17]};
log_conv__b3 = (log_conv__b3[31:16] * cons3);
log_conv__c3 = log_conv__b3[31:16];
log_conv__c4 = {2'b00,log_conv__b4[31:18]};
log_conv__b5 = (log_conv__b5[31:16] * cons5);
log_conv__c5 = log_conv__b5[31:16];
log_conv__b6 = (log_conv__b6[31:16] * cons3);
log_conv__c6 = {1'b0,log_conv__b6[31:17]};
log_conv__b7 = (log_conv__b7[31:16] * cons7);
log_conv__c7 = log_conv__b7[31:16];
log_conv__c8 = {3'b000,log_conv__b8[31:19]};
log_conv__b9 = (log_conv__b9[31:16] * cons9);
log_conv__c9 = log_conv__b9[31:16];
log_conv__b10 = (log_conv__b10[31:16] * cons5);
log_conv__c10 = {1'b0,log_conv__b10[31:17]};
log_conv__b11 = (log_conv__b11[31:16] * cons11);
log_conv__c11 = log_conv__b11[31:16];
log_conv__b12 = (log_conv__b12[31:16] * cons3);
log_conv__c12 = {2'b00,log_conv__b12[31:18]};
log_conv__b13 = (log_conv__b13[31:16] * cons13);
log_conv__c13 = log_conv__b13[31:16];
log_conv__d = ((((((((((((log_conv__c1 + log_conv__c2) + log_conv__c3) + log_conv__c4) + log_conv__c5) + log_conv__c6) + log_conv__c7) + log_conv__c8) + log_conv__c9) + log_conv__c10) + log_conv__c11) + log_conv__c12) + log_conv__c13);
y <= log_conv__d;
end
end //always
always @ (m or g ) begin
if ((m === 20'b00000000000000000000))
z <= {(19-0+1- 0){1'b0}};
else
z <= g[19:0];
end //always
assign {f}=(n * log2v);
assign {g}=(f - {5'b00000,y});
endmodule
|
�V�jCordic
sin,cos,atan(y/x)�̌v�Z���s���܂��B
�e�X�g�x���`�ł��Bsigned���g���đf���ɏ����܂��B
//Feb.13.2005
//Feb.15.2005
//Tak.Sugawara
module cordic_bench_test;
parameter cos_sin_mode=1'b0,atan_mode=1'b1;
parameter integer bit_precision=10;//11 fails
parameter integer atan_precision=11;//12 fails
parameter integer precision=bit_precision;//
parameter real allowable_error=1.0/(2**precision);
parameter real allowable_error_atan=1.0/(2**atan_precision);
parameter integer scale_power=14;//bit
parameter integer scale=2**scale_power;//16384
parameter real max_test_angle_degree=91;//max of 100 degree
reg [15:0] in_x=0 ;
reg [15:0] in_y=0 ;
reg signed [15:0] in_angle=0 ;
reg in_start=0;
reg in_mode=cos_sin_mode;
reg clk=0;
reg enable=0;
reg xrst=0;
wire out_finish;
wire signed [15:0] out_x ;
wire signed [15:0] out_y ;
wire signed [15:0] out_z ;
//
real in_angle_r;
real max_in_angle_r;//
real hard_sin,hard_cos;//
real max_angle_r;
real h_sin_limit,l_sin_limit;
real h_cos_limit,l_cos_limit;
integer i;
real work,work1;
real x_r,y_r,hard_z,angle_z;
always #10 clk=~clk;
cordic dut ( in_x, in_y, in_angle, in_start, in_mode, clk, enable, xrst, out_finish, out_x, out_y, out_z );
initial begin
//sin/cos test
//test 0->90degree
repeat(2) @(posedge clk);
@(negedge clk);
xrst=1;
in_start=1;
enable=1;
begin :for_loop1
for (i=0; 1;i=i+1) begin
in_angle=i;
@(negedge clk) in_start=0;
repeat(3) @(negedge clk);
wait (out_finish);//wait hardware calculation
in_angle_r=$itor(in_angle)/$itor(scale);
hard_sin=$itor(out_y)/$itor(scale);
hard_cos=$itor(out_x)/$itor(scale);
work=$sin(in_angle_r);
work1=allowable_error;
h_sin_limit=$sin(in_angle_r)+allowable_error;//evaluate as output-bit-precision
l_sin_limit=$sin(in_angle_r)-allowable_error;
h_cos_limit=$cos(in_angle_r)+allowable_error;
l_cos_limit=$cos(in_angle_r)-allowable_error;
if (h_sin_limit < hard_sin)begin
$display("sin max error detected %g %g",h_sin_limit,hard_sin);
$stop;
end
if (l_sin_limit > hard_sin) begin
$display("sin min error detected %g %g",l_sin_limit,hard_sin);
end
if (h_cos_limit < hard_cos)begin
$display("cos max error detected %g %g",h_cos_limit,hard_sin);
$stop;
end
if (l_cos_limit > hard_cos) begin
$display("cos min error detected %g %g",l_cos_limit,hard_sin);
end
if (i%1000==0)
$display("i=%d in_angle_r=%g sin=%g hadware_result=%g",i,in_angle_r,$sin(in_angle_r),hard_sin);
max_angle_r=max_test_angle_degree/180.*$M_PI;
if (max_angle_r < in_angle_r) disable for_loop1;//exit test loop
@(negedge clk) in_start=1;
end
end //for loop
//test 0->-90degree
@(negedge clk);
in_start=1;
enable=1;
begin :for_loop2
for (i=0; 1;i=i+1) begin
in_angle=-i;
@(negedge clk) in_start=0;
repeat(3) @(negedge clk);
wait (out_finish);//wait hardware calculation
in_angle_r=$itor(in_angle)/$itor(scale);
hard_sin=$itor(out_y)/$itor(scale);
hard_cos=$itor(out_x)/$itor(scale);
work=$sin(in_angle_r);
work1=allowable_error;
h_sin_limit=$sin(in_angle_r)+allowable_error;//evaluate as output-bit-precision
l_sin_limit=$sin(in_angle_r)-allowable_error;
h_cos_limit=$cos(in_angle_r)+allowable_error;
l_cos_limit=$cos(in_angle_r)-allowable_error;
if (h_sin_limit < hard_sin)begin
$display("sin max error detected %g %g",h_sin_limit,hard_sin);
$stop;
end
if (l_sin_limit > hard_sin) begin
$display("sin min error detected %g %g",l_sin_limit,hard_sin);
end
if (h_cos_limit < hard_cos)begin
$display("cos max error detected %g %g",h_cos_limit,hard_sin);
$stop;
end
if (l_cos_limit > hard_cos) begin
$display("cos min error detected %g %g",l_cos_limit,hard_sin);
end
if (i%1000==0)
$display("i=%d in_angle_r=%g sin=%g hadware_result=%g",i,in_angle_r,$sin(in_angle_r),hard_sin);
max_angle_r=max_test_angle_degree/180.*$M_PI;
if (-max_angle_r > in_angle_r) disable for_loop2;//exit test loop
@(negedge clk) in_start=1;
end
end //for loop
$display("Cordic sin/cos test passed");
//atan (y/x)
//test scheme
// 1>=x>0 assuming x**2+y**2=1 y=sqrt(1-xx*2);
//
xrst=0;
repeat(2) @(negedge clk);
@(negedge clk);
in_start=1;
enable=1;
xrst=1;
in_mode=atan_mode;
for (i=0;i<= scale;i=i+1) begin
in_x=i;//Start, with given in_x and in_y
x_r=$itor(i)/scale;
work=1.0-x_r**2;
y_r=$sqrt(work);
work1=y_r*scale;
in_y=$rtoi(work1);
@(negedge clk) in_start=0;//deassert _instart
repeat(3) @(negedge clk);
wait (out_finish);//wait hardware calculation
@(negedge clk);
hard_z=$itor(out_z)/scale;//get hardware result.
if (i==0) angle_z=$M_PI/2.0;
else if (i==scale) angle_z=0.0;
else angle_z=$atan(y_r/x_r);
if (hard_z > angle_z+allowable_error_atan) begin
$display("Error Detected atan max");
$stop;//assert(0);
end
if (hard_z < angle_z-allowable_error_atan) begin
$display("Error Detected atan min");
$stop;//assert(0);
end
@(negedge clk) in_start=1;
end
$display("atan(y/x) test passed");
$finish;
end
endmodule
|
| F:\vhdl ���Z\cordic_test.v(4)::cordic_bench_test Verilog�̃V�~�����[�V�����̏������������܂����B�X�^�[�g��,Go�{�^���������Ă��������B ------------- �V�~�����[�V�������J�n���܂��B-------------------- i= 0 in_angle_r=0 sin=0 hadware_result=0.000244141 i= 1000 in_angle_r=0.0610352 sin=0.0609973 hadware_result=0.0609131 i= 2000 in_angle_r=0.12207 sin=0.121767 hadware_result=0.121948 i= 3000 in_angle_r=0.183105 sin=0.182084 hadware_result=0.18219 i= 4000 in_angle_r=0.244141 sin=0.241723 hadware_result=0.241943 i= 5000 in_angle_r=0.305176 sin=0.300461 hadware_result=0.300415 i= 6000 in_angle_r=0.366211 sin=0.35808 hadware_result=0.357971 i= 7000 in_angle_r=0.427246 sin=0.414366 hadware_result=0.414246 i= 8000 in_angle_r=0.488281 sin=0.469109 hadware_result=0.469177 i= 9000 in_angle_r=0.549316 sin=0.522104 hadware_result=0.521973 i= 10000 in_angle_r=0.610352 sin=0.573156 hadware_result=0.573181 i= 11000 in_angle_r=0.671387 sin=0.622072 hadware_result=0.622009 i= 12000 in_angle_r=0.732422 sin=0.668672 hadware_result=0.668701 i= 13000 in_angle_r=0.793457 sin=0.712782 hadware_result=0.712769 i= 14000 in_angle_r=0.854492 sin=0.754238 hadware_result=0.754395 i= 15000 in_angle_r=0.915527 sin=0.792884 hadware_result=0.79303 i= 16000 in_angle_r=0.976563 sin=0.828578 hadware_result=0.828491 i= 17000 in_angle_r=1.0376 sin=0.861186 hadware_result=0.861328 i= 18000 in_angle_r=1.09863 sin=0.890586 hadware_result=0.890686 i= 19000 in_angle_r=1.15967 sin=0.91667 hadware_result=0.91687 i= 20000 in_angle_r=1.2207 sin=0.939341 hadware_result=0.93927 i= 21000 in_angle_r=1.28174 sin=0.958513 hadware_result=0.958435 i= 22000 in_angle_r=1.34277 sin=0.974115 hadware_result=0.974121 i= 23000 in_angle_r=1.40381 sin=0.98609 hadware_result=0.986145 i= 24000 in_angle_r=1.46484 sin=0.994392 hadware_result=0.994324 i= 25000 in_angle_r=1.52588 sin=0.998991 hadware_result=0.999023 i= 26000 in_angle_r=1.58691 sin=0.99987 hadware_result=0.999573 i= 0 in_angle_r=0 sin=0 hadware_result=0.000244141 i= 1000 in_angle_r=-0.0610352 sin=-0.0609973 hadware_result=-0.0606689 i= 2000 in_angle_r=-0.12207 sin=-0.121767 hadware_result=-0.121582 i= 3000 in_angle_r=-0.183105 sin=-0.182084 hadware_result=-0.181946 i= 4000 in_angle_r=-0.244141 sin=-0.241723 hadware_result=-0.241943 i= 5000 in_angle_r=-0.305176 sin=-0.300461 hadware_result=-0.300415 i= 6000 in_angle_r=-0.366211 sin=-0.35808 hadware_result=-0.358032 i= 7000 in_angle_r=-0.427246 sin=-0.414366 hadware_result=-0.414307 i= 8000 in_angle_r=-0.488281 sin=-0.469109 hadware_result=-0.468872 i= 9000 in_angle_r=-0.549316 sin=-0.522104 hadware_result=-0.52179 i= 10000 in_angle_r=-0.610352 sin=-0.573156 hadware_result=-0.573181 i= 11000 in_angle_r=-0.671387 sin=-0.622072 hadware_result=-0.622009 i= 12000 in_angle_r=-0.732422 sin=-0.668672 hadware_result=-0.668701 i= 13000 in_angle_r=-0.793457 sin=-0.712782 hadware_result=-0.712769 i= 14000 in_angle_r=-0.854492 sin=-0.754238 hadware_result=-0.754395 i= 15000 in_angle_r=-0.915527 sin=-0.792884 hadware_result=-0.792908 i= 16000 in_angle_r=-0.976563 sin=-0.828578 hadware_result=-0.828369 i= 17000 in_angle_r=-1.0376 sin=-0.861186 hadware_result=-0.861206 i= 18000 in_angle_r=-1.09863 sin=-0.890586 hadware_result=-0.890564 i= 19000 in_angle_r=-1.15967 sin=-0.91667 hadware_result=-0.91687 i= 20000 in_angle_r=-1.2207 sin=-0.939341 hadware_result=-0.93927 i= 21000 in_angle_r=-1.28174 sin=-0.958513 hadware_result=-0.958435 i= 22000 in_angle_r=-1.34277 sin=-0.974115 hadware_result=-0.974121 i= 23000 in_angle_r=-1.40381 sin=-0.98609 hadware_result=-0.986023 i= 24000 in_angle_r=-1.46484 sin=-0.994392 hadware_result=-0.994324 i= 25000 in_angle_r=-1.52588 sin=-0.998991 hadware_result=-0.999023 i= 26000 in_angle_r=-1.58691 sin=-0.99987 hadware_result=-0.999451 Cordic sin/cos test passed atan(y/x) test passed Info: $finish�R�}���h�����s���܂��Btime=24962940 |
|---|
�I���W�i���\�[�X�ƃg�����X���[�g��ł��B
------------------------------------------------------------------------
-- Title CORDIC calculater sin(x), cos(x), atan(y/x) --
-- File CORDIC.vhd --
-- Entity CORDIC --
-- rev date coded contents --
-- 001 99/01/06 ueno Make Original --
------------------------------------------------------------------------
library ieee ;
use ieee.std_logic_1164.all ;
use ieee.std_logic_unsigned.all ;
--use IEEE.std_logic_signed.all ;
--use IEEE.std_logic_arith.all ;
------------------------------------------------------------------------
-- entity --
------------------------------------------------------------------------
entity CORDIC is
port(
-- Input/Output Data format = Fixed Point Value
-- range -1.99994 to 1.99994 2's complement
-- 15 14 . 13 12 11 10 09 08 07 06 05 04 03 02 01 00
-- Sign ^point
--
IN_X : in std_logic_vector(15 downto 0) ; -- atan(y/X) -0.15 to 1.00
IN_Y : in std_logic_vector(15 downto 0) ; -- atan(Y/x) -1.00 to 1.00
IN_ANGLE : in std_logic_vector(15 downto 0) ; -- angle(thita) -1.74 to 1.74
IN_START : in std_logic ; -- convert start
IN_MODE : in std_logic ; -- 1=atan/0=sin,cos
CLK : in std_logic ; -- System Clock
ENABLE : in std_logic ; -- Clock Enable
XRST : in std_logic ; -- Reset
OUT_FINISH : out std_logic ; -- Convert end
OUT_X : out std_logic_vector(15 downto 0) ; -- Calculate X
OUT_Y : out std_logic_vector(15 downto 0) ; -- Calculate Y
OUT_Z : out std_logic_vector(15 downto 0) -- Calculate Z
);
end CORDIC ;
------------------------------------------------------------------------
-- architecture --
------------------------------------------------------------------------
architecture RTL of CORDIC is
--constant ENABLE : std_logic := '1' ;
-----------------------------------------------------------
-- Constants --
-----------------------------------------------------------
constant VAL0 : std_logic_vector(15 downto 0) := "0000000000000000" ; -- 0.000000000
constant VALX : std_logic_vector(15 downto 0) := "0010011011011101" ; -- 0.607252935
constant ATAN00 : std_logic_vector(15 downto 0) := "0011001001000100" ; -- atan(1/1)
constant ATAN01 : std_logic_vector(15 downto 0) := "0001110110101100" ; -- atan(1/2)
constant ATAN02 : std_logic_vector(15 downto 0) := "0000111110101110" ; -- atan(1/4)
constant ATAN03 : std_logic_vector(15 downto 0) := "0000011111110101" ; -- atan(1/8)
constant ATAN04 : std_logic_vector(15 downto 0) := "0000001111111111" ; -- atan(1/16)
constant ATAN05 : std_logic_vector(15 downto 0) := "0000001000000000" ; -- atan(1/32)
constant ATAN06 : std_logic_vector(15 downto 0) := "0000000100000000" ; -- atan(1/64)
constant ATAN07 : std_logic_vector(15 downto 0) := "0000000010000000" ; -- atan(1/128)
constant ATAN08 : std_logic_vector(15 downto 0) := "0000000001000000" ; -- atan(1/256)
constant ATAN09 : std_logic_vector(15 downto 0) := "0000000000100000" ; -- atan(1/512)
constant ATAN10 : std_logic_vector(15 downto 0) := "0000000000010000" ; -- atan(1/1024)
constant ATAN11 : std_logic_vector(15 downto 0) := "0000000000001000" ; -- atan(1/2048)
constant ATAN12 : std_logic_vector(15 downto 0) := "0000000000000100" ; -- atan(1/4096)
constant ATAN13 : std_logic_vector(15 downto 0) := "0000000000000010" ; -- atan(1/8192)
constant ATAN14 : std_logic_vector(15 downto 0) := "0000000000000001" ; -- atan(1/16384)
constant ATAN15 : std_logic_vector(15 downto 0) := "0000000000000000" ; -- atan(1/32768)
-----------------------------------------------------------
-- Signals --
-----------------------------------------------------------
signal REG_X : std_logic_vector(15 downto 0) ; -- Xn Register
signal REG_Y : std_logic_vector(15 downto 0) ; -- Yn Register
signal REG_Z : std_logic_vector(15 downto 0) ; -- Zn Register
signal REG_J : std_logic_vector(3 downto 0) ; -- 0 to 15 counter
signal AX : std_logic_vector(15 downto 0) ; -- Ballel Shift X
signal BX : std_logic_vector(15 downto 0) ; -- Ballel Shift X
signal CX : std_logic_vector(15 downto 0) ; -- Ballel Shift X
signal DX : std_logic_vector(15 downto 0) ; -- Ballel Shift X
signal AY : std_logic_vector(15 downto 0) ; -- Ballel Shift Y
signal BY : std_logic_vector(15 downto 0) ; -- Ballel Shift Y
signal CY : std_logic_vector(15 downto 0) ; -- Ballel Shift Y
signal DY : std_logic_vector(15 downto 0) ; -- Ballel Shift Y
signal TAB_Z : std_logic_vector(15 downto 0) ; -- Table Select Z
signal INIT_LOAD : std_logic ; -- X,Y,Z Initialize
signal NOW_CONVERT : std_logic ; -- Now Conveting for CORDIC
signal ADD_SUB : std_logic ; -- Next Calculate '1'=ADD/'0'=SUB
-----------------------------------------------------------
-- Architectures --
-----------------------------------------------------------
begin
-----------------------------------------------------------
-- Flag Control --
-----------------------------------------------------------
INIT_FLAG : process( CLK, XRST )
begin
if( XRST='0' ) then
INIT_LOAD <= '0' ;
elsif( CLK'event and CLK='1' ) then
if( ENABLE='1' ) then
if( IN_START='1' and INIT_LOAD='0' and NOW_CONVERT='0' ) then
INIT_LOAD <= '1' ;
else
INIT_LOAD <= '0' ;
end if ;
end if ;
end if ;
end process ;
CONVERT_FLAG : process( CLK, XRST )
begin
if( XRST='0' ) then
NOW_CONVERT <= '0' ;
elsif( CLK'event and CLK='1' ) then
if( ENABLE='1' ) then
if( INIT_LOAD='1' ) then
NOW_CONVERT <= '1' ;
elsif( REG_J="1111" ) then
NOW_CONVERT <= '0' ;
end if ;
end if ;
end if ;
end process ;
-----------------------------------------------------------
-- Sequence Counter --
-----------------------------------------------------------
COUNTER_GEN : process( CLK, XRST )
begin
if( XRST='0' ) then
REG_J <= "0000" ;
elsif( CLK'event and CLK='1' ) then
if( ENABLE='1' ) then
if( NOW_CONVERT='1' ) then
REG_J <= REG_J + 1 ;
end if ;
end if ;
end if ;
end process ;
-----------------------------------------------------------
-- ADD/SUB Flag --
-----------------------------------------------------------
SELECT_ADD_SUB : ADD_SUB <= not REG_Y(15) when IN_MODE='1' else REG_Z(15) ;
-----------------------------------------------------------
-- Ballel Shifter --
-----------------------------------------------------------
BALLEL_AX : process( REG_X, REG_J )
begin
if( REG_J(3)='1' ) then
AX <= REG_X(15) & REG_X(15) & REG_X(15) & REG_X(15) & REG_X(15) & REG_X(15) & REG_X(15) & REG_X(15) & REG_X(15 downto 8);
else
AX <= REG_X ;
end if ;
end process ;
BALLEL_BX : process( AX, REG_J )
begin
if( REG_J(2)='1' ) then
BX <= AX(15) & AX(15) & AX(15) & AX(15) & AX(15 downto 4);
else
BX <= AX ;
end if ;
end process ;
BALLEL_CX : process( BX, REG_J )
begin
if( REG_J(1)='1' ) then
CX <= BX(15) & BX(15) & BX(15 downto 2);
else
CX <= BX ;
end if ;
end process ;
BALLEL_DX : process( CX, REG_J )
begin
if( REG_J(0)='1' ) then
DX <= CX(15) & CX(15 downto 1);
else
DX <= CX ;
end if ;
end process ;
BALLEL_AY : process( REG_Y, REG_J )
begin
if( REG_J(3)='1' ) then
AY <= REG_Y(15) & REG_Y(15) & REG_Y(15) & REG_Y(15) & REG_Y(15) & REG_Y(15) & REG_Y(15) & REG_Y(15) & REG_Y(15 downto 8);
else
AY <= REG_Y ;
end if ;
end process ;
BALLEL_BY : process( AY, REG_J )
begin
if( REG_J(2)='1' ) then
BY <= AY(15) & AY(15) & AY(15) & AY(15) & AY(15 downto 4);
else
BY <= AY ;
end if ;
end process ;
BALLEL_CY : process( BY, REG_J )
begin
if( REG_J(1)='1' ) then
CY <= BY(15) & BY(15) & BY(15 downto 2);
else
CY <= BY ;
end if ;
end process ;
BALLEL_DY : process( CY, REG_J )
begin
if( REG_J(0)='1' ) then
DY <= CY(15) & CY(15 downto 1);
else
DY <= CY ;
end if ;
end process ;
TABLE_Z : process( REG_J )
begin
case REG_J is
when "0000" => TAB_Z <= ATAN00 ;
when "0001" => TAB_Z <= ATAN01 ;
when "0010" => TAB_Z <= ATAN02 ;
when "0011" => TAB_Z <= ATAN03 ;
when "0100" => TAB_Z <= ATAN04 ;
when "0101" => TAB_Z <= ATAN05 ;
when "0110" => TAB_Z <= ATAN06 ;
when "0111" => TAB_Z <= ATAN07 ;
when "1000" => TAB_Z <= ATAN08 ;
when "1001" => TAB_Z <= ATAN09 ;
when "1010" => TAB_Z <= ATAN10 ;
when "1011" => TAB_Z <= ATAN11 ;
when "1100" => TAB_Z <= ATAN12 ;
when "1101" => TAB_Z <= ATAN13 ;
when "1110" => TAB_Z <= ATAN14 ;
when "1111" => TAB_Z <= ATAN15 ;
when others => TAB_Z <= VAL0 ;
end case ;
end process ;
-----------------------------------------------------------
-- Calculate --
-----------------------------------------------------------
CALC_X : process( CLK, XRST )
begin
if( XRST='0') then
REG_X <= (others=>'0') ;
elsif( CLK'event and CLK='1' ) then
if( ENABLE='1' ) then
-- Initial Value
if( INIT_LOAD = '1' ) then
if( IN_MODE='1' ) then
-- Atan Mode
REG_X <= IN_X ;
else
-- Sin/Cos Mode
REG_X <= VALX ;
end if ;
elsif( NOW_CONVERT='1' ) then
if( ADD_SUB='1' ) then
REG_X <= REG_X + DY ;
else
REG_X <= REG_X - DY ;
end if ;
end if ;
end if ;
end if ;
end process ;
CALC_Y : process( CLK, XRST )
begin
if( XRST='0') then
REG_Y <= (others=>'0') ;
elsif( CLK'event and CLK='1' ) then
if( ENABLE='1' ) then
-- Initial Value
if( INIT_LOAD = '1' ) then
if( IN_MODE='1' ) then
-- Atan Mode
REG_Y <= IN_Y ;
else
-- Sin/Cos Mode
REG_Y <= VAL0 ;
end if ;
elsif( NOW_CONVERT='1' ) then
if( ADD_SUB='1' ) then
REG_Y <= REG_Y - DX ;
else
REG_Y <= REG_Y + DX ;
end if ;
end if ;
end if ;
end if ;
end process ;
CALC_Z : process( CLK, XRST )
begin
if( XRST='0') then
REG_Z <= (others=>'0') ;
elsif( CLK'event and CLK='1' ) then
if( ENABLE='1' ) then
-- Initial Value
if( INIT_LOAD = '1' ) then
if( IN_MODE='1' ) then
-- Atan Mode
REG_Z <= VAL0 ;
else
-- Sin/Cos Mode
REG_Z <= IN_ANGLE ;
end if ;
elsif( NOW_CONVERT='1' ) then
if( ADD_SUB='1' ) then
REG_Z <= REG_Z + TAB_Z ;
else
REG_Z <= REG_Z - TAB_Z ;
end if ;
end if ;
end if ;
end if ;
end process ;
OUT_FINISH <= not NOW_CONVERT ;
OUT_X <= REG_X ;
OUT_Y <= REG_Y ;
OUT_Z <= REG_Z ;
end RTL ;
------------------------------------------------------------------------
-- End of File --
------------------------------------------------------------------------
|
//-------------------------------------------------------------------
//
// This file is automatically generated by VHDL to Verilog Translator.
// Ver.1.08 Build Mar.6.2004
// www.sugawara-systems.com
// tech-support@sugawara-systems.com
// See Original Copyright Notice for property of the file .( somewhere in this file.)
//
//--------------------------------------------------------------------
//----------------------------------------------------------------------
// Title CORDIC calculater sin(x), cos(x), atan(y/x) --
// File CORDIC.vhd --
// Entity CORDIC --
// rev date coded contents --
// 001 99/01/06 ueno Make Original --
//----------------------------------------------------------------------
`timescale 1ns/1ns
`define ns 1
`define us (1000*`ns)
`define ms (1000*`us)
`define sec (1000*`ms)
module cordic ( in_x, in_y, in_angle, in_start, in_mode, clk, enable, xrst, out_finish, out_x, out_y, out_z );
input [15:0] in_x ;
input [15:0] in_y ;
input [15:0] in_angle ;
input in_start;
input in_mode;
input clk;
input enable;
input xrst;
output out_finish;
output [15:0] out_x ;
output [15:0] out_y ;
output [15:0] out_z ;
parameter [15:0] val0=16'b0000000000000000;
parameter [15:0] valx=16'b0010011011011101;
parameter [15:0] atan00=16'b0011001001000100;
parameter [15:0] atan01=16'b0001110110101100;
parameter [15:0] atan02=16'b0000111110101110;
parameter [15:0] atan03=16'b0000011111110101;
parameter [15:0] atan04=16'b0000001111111111;
parameter [15:0] atan05=16'b0000001000000000;
parameter [15:0] atan06=16'b0000000100000000;
parameter [15:0] atan07=16'b0000000010000000;
parameter [15:0] atan08=16'b0000000001000000;
parameter [15:0] atan09=16'b0000000000100000;
parameter [15:0] atan10=16'b0000000000010000;
parameter [15:0] atan11=16'b0000000000001000;
parameter [15:0] atan12=16'b0000000000000100;
parameter [15:0] atan13=16'b0000000000000010;
parameter [15:0] atan14=16'b0000000000000001;
parameter [15:0] atan15=16'b0000000000000000;
reg [15:0] reg_x;
reg [15:0] reg_y;
reg [15:0] reg_z;
reg [3:0] reg_j;
reg [15:0] ax;
reg [15:0] bx;
reg [15:0] cx;
reg [15:0] dx;
reg [15:0] ay;
reg [15:0] by;
reg [15:0] cy;
reg [15:0] dy;
reg [15:0] tab_z;
reg init_load;
reg now_convert;
wire add_sub;
wire out_finish;
wire [15:0] out_x;
wire [15:0] out_y;
wire [15:0] out_z;
always @ (posedge clk or negedge xrst ) begin
if ((xrst === 1'b0))
init_load <= 1'b0;
else
begin
if ((enable === 1'b1))
begin
if ((((in_start === 1'b1) & (init_load === 1'b0)) & (now_convert === 1'b0)))
init_load <= 1'b1;
else
init_load <= 1'b0;
end
end
end //always
always @ (posedge clk or negedge xrst ) begin
if ((xrst === 1'b0))
now_convert <= 1'b0;
else
begin
if ((enable === 1'b1))
begin
if ((init_load === 1'b1))
now_convert <= 1'b1;
else if ((reg_j === 4'b1111))
now_convert <= 1'b0;
end
end
end //always
always @ (posedge clk or negedge xrst ) begin
if ((xrst === 1'b0))
reg_j <= 4'b0000;
else
begin
if ((enable === 1'b1))
begin
if ((now_convert === 1'b1))
reg_j <= (reg_j + 1);
end
end
end //always
assign {add_sub}=(in_mode === 1'b1) ?
~ (reg_y[15])
: reg_z[15];
always @ (reg_x or reg_j ) begin
if ((reg_j[3] === 1'b1))
ax <= {{{{{{{{reg_x[15],reg_x[15]},reg_x[15]},reg_x[15]},reg_x[15]},reg_x[15]},reg_x[15]},reg_x[15]},reg_x[15:8]};
else
ax <= reg_x;
end //always
always @ (ax or reg_j ) begin
if ((reg_j[2] === 1'b1))
bx <= {{{{ax[15],ax[15]},ax[15]},ax[15]},ax[15:4]};
else
bx <= ax;
end //always
always @ (bx or reg_j ) begin
if ((reg_j[1] === 1'b1))
cx <= {{bx[15],bx[15]},bx[15:2]};
else
cx <= bx;
end //always
always @ (cx or reg_j ) begin
if ((reg_j[0] === 1'b1))
dx <= {cx[15],cx[15:1]};
else
dx <= cx;
end //always
always @ (reg_y or reg_j ) begin
if ((reg_j[3] === 1'b1))
ay <= {{{{{{{{reg_y[15],reg_y[15]},reg_y[15]},reg_y[15]},reg_y[15]},reg_y[15]},reg_y[15]},reg_y[15]},reg_y[15:8]};
else
ay <= reg_y;
end //always
always @ (ay or reg_j ) begin
if ((reg_j[2] === 1'b1))
by <= {{{{ay[15],ay[15]},ay[15]},ay[15]},ay[15:4]};
else
by <= ay;
end //always
always @ (by or reg_j ) begin
if ((reg_j[1] === 1'b1))
cy <= {{by[15],by[15]},by[15:2]};
else
cy <= by;
end //always
always @ (cy or reg_j ) begin
if ((reg_j[0] === 1'b1))
dy <= {cy[15],cy[15:1]};
else
dy <= cy;
end //always
always @ (reg_j ) begin
case (reg_j)
4'b0000 :
tab_z <= 16'b0011001001000100;
4'b0001 :
tab_z <= 16'b0001110110101100;
4'b0010 :
tab_z <= 16'b0000111110101110;
4'b0011 :
tab_z <= 16'b0000011111110101;
4'b0100 :
tab_z <= 16'b0000001111111111;
4'b0101 :
tab_z <= 16'b0000001000000000;
4'b0110 :
tab_z <= 16'b0000000100000000;
4'b0111 :
tab_z <= 16'b0000000010000000;
4'b1000 :
tab_z <= 16'b0000000001000000;
4'b1001 :
tab_z <= 16'b0000000000100000;
4'b1010 :
tab_z <= 16'b0000000000010000;
4'b1011 :
tab_z <= 16'b0000000000001000;
4'b1100 :
tab_z <= 16'b0000000000000100;
4'b1101 :
tab_z <= 16'b0000000000000010;
4'b1110 :
tab_z <= 16'b0000000000000001;
4'b1111 :
tab_z <= 16'b0000000000000000;
default :
tab_z <= 16'b0000000000000000;
endcase
end //always
always @ (posedge clk or negedge xrst ) begin
if ((xrst === 1'b0))
reg_x <= {(15-0+1- 0){1'b0}};
else
begin
if ((enable === 1'b1))
begin
if ((init_load === 1'b1))
begin
if ((in_mode === 1'b1))
reg_x <= in_x;
else
reg_x <= 16'b0010011011011101;
end
else if ((now_convert === 1'b1))
begin
if ((add_sub === 1'b1))
reg_x <= (reg_x + dy);
else
reg_x <= (reg_x - dy);
end
end
end
end //always
always @ (posedge clk or negedge xrst ) begin
if ((xrst === 1'b0))
reg_y <= {(15-0+1- 0){1'b0}};
else
begin
if ((enable === 1'b1))
begin
if ((init_load === 1'b1))
begin
if ((in_mode === 1'b1))
reg_y <= in_y;
else
reg_y <= 16'b0000000000000000;
end
else if ((now_convert === 1'b1))
begin
if ((add_sub === 1'b1))
reg_y <= (reg_y - dx);
else
reg_y <= (reg_y + dx);
end
end
end
end //always
always @ (posedge clk or negedge xrst ) begin
if ((xrst === 1'b0))
reg_z <= {(15-0+1- 0){1'b0}};
else
begin
if ((enable === 1'b1))
begin
if ((init_load === 1'b1))
begin
if ((in_mode === 1'b1))
reg_z <= 16'b0000000000000000;
else
reg_z <= in_angle;
end
else if ((now_convert === 1'b1))
begin
if ((add_sub === 1'b1))
reg_z <= (reg_z + tab_z);
else
reg_z <= (reg_z - tab_z);
end
end
end
end //always
assign {out_finish}=~ (now_convert);
assign {out_x}=reg_x;
assign {out_y}=reg_y;
assign {out_z}=reg_z;
endmodule
|
���L�v�撆�̈ȉ��̃v���W�F�N�g�́A���x�~���Ă��܂��B
.�}�C�N���v���O�����ɂ��p�^�[���W�F�l���[�^
�}�C�N���v���O�����́A���x�ȏ��������Ƃ��Ă̑��ʂ������Ă��܂��B
CPU�ł͒x�����邵�A�X�e�[�g�}�V���ł͕��G�����鐧��ɍD�K�ł��B�ӊO�ƒm���Ă��Ȃ��̂łƂ肠���邱�Ƃɂ��܂��B���p��Ƃ��ăp�^�[���W�F�l���[�^��v���Ă݂܂��B
�D������
CRC��r�^�r�A���[�h�\����������ECC�R�A��v���Ă݂܂��B�܂��AYACC�v���W�F�N�g�ŁA�K���A��ALU�Ɖ��Z���߂�lj�����YACC�v���Z�b�T�ł�C����ŋL�q���Ă݂܂��B
�D�T�[�{����
���㐧�䗝�_�ɂ��T�[�{�����Veritak�V�~�����[�^��Ŏ������䂵�Ă݂܂��B���{�b�g���䓙�Ɏg���鐧�䗝�_�̊�b���Ƃ肠���܂��B
�DDPLL
�f�W�^��PLL�ɂ��ĂƂ肠���܂��B
�\�t�g���C�u����(�@�X,10)
�@
�Z�p���C�u�����@
�@Verilog2001��VPI�iPLI�@Version2.0)���g����C��Math���C�u�������Ăяo���܂����BVerilog�ƊO�������IF����ɂ́AC�܂��́AC++��DLL������Ă��̂��ȒP�ł��B���̗�ł́AC++�ŊȒP�ɋL�q���Ă݂܂����B
Verilog�Q�O�O�P�ɂȂ��ď]����PLI�́A�ێ爵���ɂȂ��Ă��܂��̂ł��ꂩ��Verilog�Ƃ�IF�𑼂̌���ŏ������Ƃ���ꍇ�́AVPI�������߂��܂��B
�Ƃ��낪�AVPI�́A�V�~�����[�^�̓�����Ԃ��Ɍ��܂Ő���ł���悤�ɂȂ��Ă��āA�ėp�I�Ȕ��ʁA���ۓI�ł킩�肸�炢�ʂ�����Ǝv���܂��B�\�[�X�̃R�����g���Q�l�ɕ��͋C������ł�����������A�Ǝv���܂��B
�Ȃ��A�{���C�u�����́AVeritak�@Version1.02���math_vpi.dll�Ƃ��ăC���X�g�[���p�b�P�[�W�ɒlj�����Ă��܂��B
�P�O�DVerilog�ŃA�i���O�V�~�����[�g�H
�@PLL/�T�[�{�n���܂V�X�e���ł́AVerilog�R�[�f�B���O�O��Matlab�������̓N���[���A��������C/C++�ŃV�X�e���V�~�����[�V����������̂����ʂł��B���̌�A�f�U�C���̍ŏI�i�K�ł���Verilog�ł͂ǂ����Ă���ł��傤���H
LSI�̓f�W�^���ł������̎��ӂ́A�A�i���O�t�B���^�ADC���[�^��VCM,���邢��OPAMP�Ƃ������A�i���O�œ����ꍇ������ł��傤�B
Verilog�ł��ׂĂ����f�����O���邱�Ƃ��s�\�ł͂Ȃ��ł����A�V�~�����[�V�����������猾���āA���܂蓾��Ƃ͌����܂���B
�i����Veritak�̏ꍇ�A�������C���^�v���^�R�[�h�ŁAREAL�̎�����BITVECTOR�Ɠ����S�l�ɂ��Ă��܂��Ă���̂�REAL�������ƃV�~�����[�V�����X�s�[�h�ƃ������������ቺ���Ă��܂��܂��B�j
����ȂƂ��́A�y�߂̃A�i���O�V�~�����[�^���g����ƕ֗��ł��B�����ŁA�����VPI���g���Đ��`�V�X�e���̃V���~���[�^���������Ă݂܂����B
�V�~�����[�^�́A��ԋ�Ԍ^�̍s����`�����e�L�X�g�t�@�C����ǂݍ���ŁA���N���b�N$runge_kutta(..�j�ŌĂяo���܂��B������REAL�^�A���[���L�q����IF���܂��B
SPICE�̂悤�ɔ���`�f�q�͈����܂��A�A�i���O�t�B���^�̎��ԉ���������Ƃ��A�T�[�{�n�̓��쌟�Ƃ������p�r�ɂ͎g����Ǝv���܂��B�܂��AVPI�̃T���v���Ƃ��Ă��悢��ɂȂ��Ă���Ǝv���܂��B
�M�҂̏����n�́AVC7C++�ł����A__int64��long�@long�Ƃ���AGCC�n�ł��R���p�C���ł���Ǝv���܂��B
�Ȃ��A�{���C�u�����́AVeritak�@Version1.02���math_vpi.dll�Ƃ��ăC���X�g�[���p�b�P�[�W�ɒlj�����Ă��܂��B(Jan.6.2005 update)
VeriPad
Veritak�ɕt�����Ă���e�L�X�g�G�f�B�^��VC++�\�[�X�ł��B�I���W�i���́ANYSL���C�Z���X��GreenPad�ł��B�@
Veritak�Ƃ̘A�g�����ׂ��M�҂��u���[�N�|�C���g�A�c�[���`�b�v�A�^�O�W�����v�A���̑�Veritak�@�Ƃ�IF��GreenPad�ɒlj��������VeriPad�Ƃ��Ă��܂��܂����B�@���̋C�̂�����́A���ɂ̃J�X�^�}�C�Y���\�ł��B
�I���W�i���́ASuper�@Tiny�L�q�ɂȂ��Ă��āAEXE�T�C�Y���T�OKB�Ƃ����ɏ��T�C�Y���������Ă��܂������A�M�҂�STL���g���Ă��܂����ʂ̃T�C�Y�ɂȂ��Ă��܂��܂����B
�D�݂�Editor�̃X�N���v�g�����g���āAVeriPad���ǂ����������������́AWindows�ʐM��IF�ł���GpMain.cpp���猩�Ă䂯�悢�ł��傤�B
�@�@VeriPad�\�[�X�̃_�E�����[�h�i�PMB�j Jul.11.2005��
�@
�@Release�@Note:
- Veritak�@Version 1.70A�ɑΉ����Ă��܂��B
- �I���W�i������̒lj����ɂ́A�hTAK�h�ŃR�����g���Ă��܂��B
�@�@�@