Verilog HDLでMixed Signal
DWMの2006年11月号にVerilog HDLでクロックリカバリー回路をシミュレーションする記事が掲載されています。クロックリカバリ、ルンゲクッタ、VCOのシミュレーションの仕方、動作原理についての詳しい解説は、記事を読んで頂くことにして、ここでは、VPIを適用してシミュレーションを高速化することを狙ってみます。
高速化の狙いどころーまとまったFunctionルーチンを呼び出す
記事では、ユーザVPIは使わずに、全てをVerilog HDLで書かれています。記事が書かれた当時、Veritakでは、未だVPIをサポートしていませんでしたが、現在は、VisualC++Expressという、高速なC++コンパイラを無償で使える環境も整ったので、VPIで処理を高速化してみたいと思います。
記事中、VCOの非線形部のモデリングや、ルンゲクッタなどは、処理としてまとまっており、VPIで呼び出すことで高速化が期待できます。
一般に、このようなモデリングで、
- 時間を消費する文がない
- 4値演算を適用する必要がない(XZは、不要、Native Cで書ける)
- real 演算(C言語のdouble)主体
という風に、計算自体に時間がかかっているところ、かつ、処理として一つのfunction
call にまとめられるところが、VPIによる高速化の狙いどころです。ルンゲクッタの方は、内部状態を持ちますので、単純なFunction CALLというより、一つのC++クラスによる実装になりますが、そういう場合でもVPIを適用することは可能です。
一方、VPI化によって、次のマイナス面についても考慮が必要です。
- VPIの呼び出しオーバヘッド
- IFにない信号は、観察ができなくなる(デバッグが難しくなる)
折角、VPI化しても、呼び出す引数の数が多いと、そこで時間を食ってしまいます。記述上の工夫は後述しますが、なるべくなら引数は、少ない方がよいです。また、引数にない内部信号は、観測ができませんので、デバッグが難しくなる問題もあります。
(今回は、Verilog HDLで記述されたソースをほぼそのままC++で書き換えるだけですので、その点では、あまり苦労はしませんでした。)
それでは、VPIの実装方法について見ていきましょう。
次は、VCOの非線形部のモデリング部ソース(抜粋)です。
initial begin
PI2 = 6.28318530717958647692528676655901;
theta=THETA_INIT;
dlt_t=TM_PRCS*CYCLE_VCO;
cycle=CYCLE_VCO;
vin24b_lmtH=24'h0E_6666;
vin24b_lmtL=24'h00_0000;
a0=4.6984;//a0〜a4:4次多項式近似の係数。
a1=0.2565;
a2=-0.9054;
a3=1.6146;
a4=-0.548;
end
always #(cycle) begin
if (rst) begin
theta=THETA_INIT;
out0p = 1'b0;
out0n = ~out0p;
out45p = 1'b0;
out45n = ~out45p;
out90p = 1'b0;
out90n = ~out90p;
out135p = 1'b0;
out135n = ~out135p;
end else begin
//シングルエンド入力vinに対するリミッタ。
if(vin[23]==1'b0)
vin2=(vin > vin24b_lmtH)? vin24b_lmtH : vin;
else
vin2=vin24b_lmtL;
//整数から実数へ変換。
tmp32b_1={ {8{vin2[23]} }, vin2};
tmp_r1=$itor(tmp32b_1);
vin_rl=tmp_r1/K_RTOI;
//入力電圧を、周波数、位相へ変換。
frq = a0
+a1*vin_rl
+a2*(vin_rl*vin_rl)
+a3*(vin_rl*vin_rl*vin_rl)
+a4*(vin_rl*vin_rl*vin_rl*vin_rl);
tmp_r2=theta +dlt_t*PI2*frq;
theta=(tmp_r2 > PI2)? (tmp_r2-PI2) : tmp_r2;
//位相(4つの位相)を電圧に変換し、ディジタル化する。
tmp_r3a=$sin(theta);
tmp_r3b=$sin(theta-(PI2/8.0));
tmp_r3c=$sin(theta-(PI2/4.0));
tmp_r3d=$sin(theta-(PI2*3/8.0));
tmp_r4a=tmp_r3a*K_RTOI;
tmp_r4b=tmp_r3b*K_RTOI;
tmp_r4c=tmp_r3c*K_RTOI;
tmp_r4d=tmp_r3d*K_RTOI;
tmp32b_2=$rtoi(tmp_r4a);
out0p = (tmp32b_2[31]==1'b0)? 1'b1: 1'b0;
out0n = ~out0p;
tmp32b_2=$rtoi(tmp_r4b);
out45p = (tmp32b_2[31]==1'b0)? 1'b1: 1'b0;
out45n = ~out45p;
tmp32b_2=$rtoi(tmp_r4c);
out90p = (tmp32b_2[31]==1'b0)? 1'b1: 1'b0;
out90n = ~out90p;
tmp32b_2=$rtoi(tmp_r4d);
out135p = (tmp32b_2[31]==1'b0)? 1'b1: 1'b0;
out135n = ~out135p;
end
end
//($sinは、Veritak Unique Functionです。内部実装は、やはりVPIを使っています。算術ライブラリ編をご参照ください。)
下は、VPIを使ったVersionです。初期化と毎回部分と二つのVPI CALLにまとめています。
initial begin
PI2 = 6.28318530717958647692528676655901;
theta=THETA_INIT;
dlt_t=TM_PRCS*CYCLE_VCO;
cycle=CYCLE_VCO;
vin24b_lmtH=24'h0E_6666;
vin24b_lmtL=24'h00_0000;
a0=4.6984;//a0〜a4:4次多項式近似の係数。
a1=0.2565;
a2=-0.9054;
a3=1.6146;
a4=-0.548;
THETA_INIT_val=THETA_INIT;
K_RTOI_val=K_RTOI;
$init_my_vco(theta,dlt_t,vin24b_lmtH,vin24b_lmtL,
a0,a1,a2,a3,a4,THETA_INIT_val,K_RTOI_val,rst,vin,out0p,out45p,out90p,out135p,vin_rl);//VCO のVPI初期化ルーチン
end
always #(cycle) begin
$calc_my_vco();//VCO VPI CALL
out0n = ~out0p;
out45n = ~out45p;
out90n = ~out90p;
out135n = ~out135p;
end
このVPI CALLの中身は、次のC++記述です。
最初のiniialize Callで、パラメータの初期値を渡しているほかに、毎回呼び出す部分のインターフェース信号のハンドルを渡している点がポイントです。
これで、毎回呼び出す部分では、お決まりの引数を呼び出す部分が不要になり、高速化に寄与します。
このソースの構造は、
本体の前で、Verilog HDL信号の値の読み込み、
本体:ほぼVerilogHDLソースをそのまま移植しただけ
本体後で、Verilog HDL信号への値の書き込み
になっています。それほど難しくはありませんね。
double theta;
double dlt_t;
unsigned vin24b_lmtH, vin24b_lmtL;
double a0,a1,a2,a3,a4;//a0〜a4:4次多項式近似の係数。
double K_RTOI_val,THETA_INIT;
vpiHandle vin_handle=0;
vpiHandle vco_reset_handle=0;
vpiHandle out0p_handle=0,out45p_handle=0,out90p_handle=0,out135p_handle=0;
vpiHandle vin_rl_handle=0;
static int init_my_vco_calltf(char* name)
{
vpiHandle systfref = vpi_handle(vpiSysTfCall, NULL); /* get system function that invoked C routine */
vpiHandle argsiter = vpi_iterate(vpiArgument, systfref);/* get iterator (list) of passed arguments */
vpiHandle argh=0;
s_vpi_value value;
vpi_printf(" Initializing vco parameter.\n");
while(argh = vpi_scan(argsiter)){
string str=vpi_get_str(vpiName,argh);
if (!str.compare("theta")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
theta=value.value.real;
vpi_printf("theta=%g\n",theta);
}else if (!str.compare("dlt_t")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
dlt_t=value.value.real;
vpi_printf("dlt_t=%g\n",dlt_t);
}else if (!str.compare("a0")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
a0=value.value.real;
vpi_printf("a0=%g\n",a0);
}else if (!str.compare("a1")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
a1=value.value.real;
vpi_printf("a1=%g\n",a1);
}else if (!str.compare("a2")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
a2=value.value.real;
vpi_printf("a2=%g\n",a2);
}else if (!str.compare("a3")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
a3=value.value.real;
vpi_printf("a3=%g\n",a3);
}else if (!str.compare("a4")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
a4=value.value.real;
vpi_printf("a3=%g\n",a4);
}else if (!str.compare("vin24b_lmtH")) {
value.format=vpiIntVal;
vpi_get_value(argh, &value);
vin24b_lmtH=value.value.integer;
vpi_printf("vin24b_lmtH=%d\n",vin24b_lmtH);
}else if (!str.compare("vin24b_lmtL")) {
value.format=vpiIntVal;
vpi_get_value(argh, &value);
vin24b_lmtL=value.value.integer;
vpi_printf("vin24b_lmtL=%d\n",vin24b_lmtL);
}else if (!str.compare("vin")) {
vin_handle=argh;
}else if (!str.compare("rst")) {
vco_reset_handle=argh;
}else if (!str.compare("out0p")) {
out0p_handle=argh;
}else if (!str.compare("out45p")) {
out45p_handle=argh;
}else if (!str.compare("out90p")) {
out90p_handle=argh;
}else if (!str.compare("out135p")) {
out135p_handle=argh;
}else if (!str.compare("vin_rl")) {
vin_rl_handle=argh;
}else if (!str.compare("K_RTOI_val")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
K_RTOI=value.value.real;
vpi_printf("K_RTOI_val=%g\n",K_RTOI);
}else if (!str.compare("THETA_INIT_val")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
THETA_INIT=value.value.real;
vpi_printf("THETA_INIT_val=%g\n",THETA_INIT);
}
}
vpi_printf("vco parameter initilization done.\n\n");
return 0;
}
static int calc_my_vco_calltf(char* name)
{
int out0p,out45p,out90p,out135p;
unsigned vin2,vin;
int rst;
double tmp_r3a,tmp_r3b,tmp_r3c,tmp_r3d;
double tmp_r4a,tmp_r4b,tmp_r4c,tmp_r4d;
double vin_rl;
double tmp_r1,tmp_r2;
double PI2=6.28318530717958647692528676655901;
double frq;
unsigned tmp32b_2;
//Verilogの値を読む
s_vpi_value value;
if (!vco_reset_handle ||
!vin_handle ||
!out0p_handle ||
!out45p_handle ||
!out90p_handle ||
!out135p_handle ||
!vin_rl_handle
) {
vpi_printf("VPI Programming Error. VCO Handle Error.\n");
vpi_sim_control(vpiFinish, 1);
return 0;
}
//rst
value.format = vpiScalarVal;
vpi_get_value(rst_handle, &value);
rst=value.value.scalar & 0x01;
//vin
value.format = vpiIntVal;
vpi_get_value(vin_handle, &value);
vin=value.value.integer;
//読み込み終了
//本体始まり
if (rst) {
theta=THETA_INIT;
out0p = 0;
// out0n = ~out0p;
out45p = 0;
// out45n = ~out45p;
out90p = 0;
// out90n = ~out90p;
out135p = 0;
// out135n = ~out135p;
} else {
//シングルエンド入力vinに対するリミッタ。
if(vin>>23 /*[23]*/==0)
vin2=(vin > vin24b_lmtH)? vin24b_lmtH : vin;
else
vin2=vin24b_lmtL;
//整数から実数へ変換。
if (vin2>> 23 ==1) tmp_r1=-(int)(vin2& 0x07ffffff);
else tmp_r1=vin2;
//tmp32b_1={ {8{vin2[23]} }, vin2};
//tmp_r1=$itor(tmp32b_1);
vin_rl=tmp_r1/K_RTOI;
value.format=vpiRealVal;
value.value.real=vin_rl;
vpi_put_value(vin_rl_handle, &value, NULL, vpiNoDelay);//
//入力電圧を、周波数、位相へ変換。
frq = a0
+a1*vin_rl
+a2*(vin_rl*vin_rl)
+a3*(vin_rl*vin_rl*vin_rl)
+a4*(vin_rl*vin_rl*vin_rl*vin_rl);
tmp_r2=theta +dlt_t*PI2*frq;
theta=(tmp_r2 > PI2)? (tmp_r2-PI2) : tmp_r2;
//位相(4つの位相)を電圧に変換し、ディジタル化する。
tmp_r3a=sin(theta);
tmp_r3b=sin(theta-(PI2/8.0));
tmp_r3c=sin(theta-(PI2/4.0));
tmp_r3d=sin(theta-(PI2*3/8.0));
tmp_r4a=tmp_r3a*K_RTOI;
tmp_r4b=tmp_r3b*K_RTOI;
tmp_r4c=tmp_r3c*K_RTOI;
tmp_r4d=tmp_r3d*K_RTOI;
tmp32b_2=/*$rtoi*/(tmp_r4a);
out0p = (tmp32b_2 >>31 /*[31]*/==0)? 1: 0;
//out0n = ~out0p;
tmp32b_2=/*$rtoi*/(tmp_r4b);
out45p = (tmp32b_2>>31 /*[31]*/==0)? 1: 0;
//out45n = ~out45p;
tmp32b_2=/*$rtoi*/(tmp_r4c);
out90p = (tmp32b_2>>31 /*[31]*/==0)? 1: 0;
//out90n = ~out90p;
tmp32b_2=/*$rtoi*/(tmp_r4d);
out135p = (tmp32b_2>>31/*[31]*/==0)? 1: 0;
//out135n = ~out135p;
}
//本体終わり
//Verilogに値を戻す。
value.format=vpiScalarVal;
value.value.scalar=out0p;
vpi_put_value(out0p_handle, &value, NULL, vpiNoDelay);//
value.value.scalar=out45p;
vpi_put_value(out45p_handle, &value, NULL, vpiNoDelay);//
value.value.scalar=out90p;
vpi_put_value(out90p_handle, &value, NULL, vpiNoDelay);//
value.value.scalar=out135p;
vpi_put_value(out135p_handle, &value, NULL, vpiNoDelay);//
return 0;
}
次は、ルンゲクッタ部の実装です。
VPI適用後のソースです。
上と同様に、初期化部と毎回部を分けています。
Verilog HDLソースで ノンブロッキングアサイン(<=)をしている信号があるのですが、VPIでは、ブロッキングアサイン(=)しかありません。そこで、Verilog HDLソースに信号を追加し、VPIで計算された信号*_BKの後に <=代入を行う文を追加しています。
initial begin
rl_relerr=RELERR;
rl_abserr=ABSERR;
rst_rk=1'b1;//サイクル数のリセット。
hit_min_h=0;//最小時間刻みの使用頻度を0にセット。
tmp_r1=TS_RK/TM_PRCS;
tmp_i1=tmp_r1;
cycle=(tmp_i1 < 1)? 1:tmp_i1;
tmp_r2=cycle;
a11=-(TM_PRCS*1000.0*tmp_r2)/(C2*RP);
a12=-a11;
a21=(TM_PRCS*1000.0*tmp_r2)/(CP*RP);
a22=-a21;
b1=(TM_PRCS*1000.0*tmp_r2)/C2;
tmp_r1=cycle;
tmp_r2=(N_STP_INI/(TM_PRCS*cycle));
tmp_i1=tmp_r2;
h_n0=(tmp_i1 < 1)? 1:tmp_i1;
ip_pd1=CUR_CP_PD1*0.000001;//[A]、PDにおける正側出力電流値。
in_pd1=-RTO_B_A_PD1*CUR_CP_PD1*0.000001;//[A]、PDにおける負側出力電流値。
ip_fd=CUR_CP_FD*0.000001;//[A]、FDにおける正側出力電流値。
in_fd=-RTO_B_A_FD*CUR_CP_FD*0.000001;//[A]、FDにおける負側出力電流値。
im_fd=OFS_CUR_CP_FD*0.000001;//[A]、FDにおける中間レベル出力電流値(理想は零)。
rl_x1=0;
rl_x2=0;
tmp32b_lmtH={8'h00, 24'h7F_FFFF};
tmp32b_lmtL=~tmp32b_lmtH;
K_RTOI_val=K_RTOI;
$init_my_runge_kutta(rl_relerr,rl_abserr,a11,a12,a21,a22,h_n,h_n0,rl_x1,rl_x2,
tmp32b_lmtH,tmp32b_lmtL,vout_BK,rst_rk_BK,rst,rst_rk,hit_min_h,K_RTOI_val,rl_b1_iin);
end
//チャージポンプ
always @ (pd1p or fdp) begin
if(pd1p==1'b1) i_pd1=ip_pd1;
else i_pd1=in_pd1;
if((fdp==1'b1) &(fdn==1'b0)) i_fd=ip_fd;
else if((fdp==1'b0) &(fdn==1'b1)) i_fd=in_fd;
else i_fd=im_fd;
//ルンゲクッタ用
rl_iin=i_pd1-i_fd;
rl_b1_iin=b1*rl_iin;
rst_rk <= 1'b1;
end
//Low Pass Filter
always #(cycle) begin
$calc_my_runge_kutta();
vout<=vout_BK;
rst_rk<=rst_rk_BK;
end
対応するVPIのソースです。C++のクラスにまとめたいところですが、Cから来ている人が見やすいようにStatic変数で書いています。
//STATIC 変数
// int cycle;//ルンゲクッタ処理の実行頻度の逆数。
int h_n, h_n0;//ルンゲクッタ計算でのスキップ数、スキップ数の初期値。
int cnt_dwn_rk;//ルンゲクッタ計算におけるスキップ数のカウンタ。
int hit_min_h;//ルンゲクッタ計算における最小時間刻みの使用頻度(CP出力更新時を除く)。
//double ip_pd1, in_pd1, ip_fd, im_fd, in_fd;
//double i_pd1, i_fd;
//double rl_iin;
double k1a, k1b, k2a=0.0, k2b=0.0, k3a, k3b;
double a11,a12, a21, a22;
double rl_b1_iin, rl_x1, rl_x2 ;
double rl_relerr, rl_abserr;
double K_RTOI;
unsigned tmp32b_lmtH,tmp32b_lmtL;
int cal_rk;
int good_err;
//読み込み用ハンドル
vpiHandle rst_handle=0;
vpiHandle rst_rk_handle=0;
vpiHandle rl_b1_iin_handle=0;
//書き込み用ハンドル
vpiHandle vout_BK_handle=0;
vpiHandle hit_min_h_handle=0;
vpiHandle rst_rk_BK_handle=0;
//初期値設定及び、毎回計算用の変数ハンドルを得る
//initial で一回だけ呼び出す
static int init_my_runge_kutta_calltf(char* name)
{
vpiHandle systfref = vpi_handle(vpiSysTfCall, NULL); /* get system function that invoked C routine */
vpiHandle argsiter = vpi_iterate(vpiArgument, systfref);/* get iterator (list) of passed arguments */
vpiHandle argh=0;
s_vpi_value value;
vpi_printf("Initializing parameter of Rungekutta.\n");
while(argh = vpi_scan(argsiter)){
string str=vpi_get_str(vpiName,argh);
if (!str.compare("rl_relerr")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
rl_relerr=value.value.real;
vpi_printf("r1_relerr=%g\n",rl_relerr);
}else if (!str.compare("rl_abserr")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
rl_abserr=value.value.real;
vpi_printf("rl_abserr=%g\n",rl_abserr);
}else if (!str.compare("a11")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
a11=value.value.real;
vpi_printf("a11=%g\n",a11);
}else if (!str.compare("a12")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
a12=value.value.real;
vpi_printf("a12=%g\n",a12);
}else if (!str.compare("a21")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
a21=value.value.real;
vpi_printf("a21=%g\n",a21);
}else if (!str.compare("a22")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
a22=value.value.real;
vpi_printf("a22=%g\n",a22);
}else if (!str.compare("rl_x1")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
rl_x1=value.value.real;
vpi_printf("rl_x1=%g\n",rl_x1);
}else if (!str.compare("rl_x2")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
rl_x2=value.value.real;
vpi_printf("rl_x2=%g\n",rl_x2);
}else if (!str.compare("tmp32b_lmtH")) {
value.format=vpiIntVal;
vpi_get_value(argh, &value);
tmp32b_lmtH=value.value.integer;
vpi_printf("tmp32b_lmtH=%d\n",tmp32b_lmtH);
}else if (!str.compare("tmp32b_lmtL")) {
value.format=vpiIntVal;
vpi_get_value(argh, &value);
tmp32b_lmtL=value.value.integer;
vpi_printf("tmp32b_lmtL=%d\n",tmp32b_lmtL);
}else if (!str.compare("h_n")) {
value.format=vpiIntVal;
vpi_get_value(argh, &value);
h_n=value.value.integer;
vpi_printf("h_n=%d\n",h_n);
}else if (!str.compare("h_n0")) {
value.format=vpiIntVal;
vpi_get_value(argh, &value);
h_n0=value.value.integer;
vpi_printf("h_n0=%d\n",h_n0);
}else if (!str.compare("rst")) {
rst_handle=argh;
}else if (!str.compare("rst_rk")) {
rst_rk_handle=argh;
}else if (!str.compare("vout_BK")) {
vout_BK_handle=argh;
}else if (!str.compare("hit_min_h")) {
hit_min_h_handle=argh;
value.format=vpiIntVal;
vpi_get_value(argh, &value);
hit_min_h=value.value.integer;
vpi_printf("hit_min_h=%d\n",hit_min_h);
}else if (!str.compare("rst_rk_BK")) {
rst_rk_BK_handle=argh;
vpi_printf("rst_rk_BK_handle=%x",rst_rk_BK_handle);
}else if (!str.compare("K_RTOI_val")) {
value.format=vpiRealVal;
vpi_get_value(argh, &value);
K_RTOI=value.value.real;
vpi_printf("K_RTOI=%g\n",K_RTOI);
}else if (!str.compare("rl_b1_iin")) {
rl_b1_iin_handle=argh;
}
}
vpi_printf("Initialization Done.\n\n");
return 0;
}
static int calc_my_runge_kutta_calltf(char* name)
{
//Verilog インターフェース変数
unsigned rst;
unsigned rst_rk_BK;
unsigned vout_BK;
unsigned rst_rk;
//ローカル変数
double tmp_r1, tmp_r2, tmp_r3, tmp_r4;
double dif_x1, dif_x2, err_x1, err_x2;
int tmp_i1, tmp_i2;
unsigned tmp32b_1;
//Verilogの値を読む
s_vpi_value value;
if (!rst_handle ||
!rst_rk_handle ||
!rl_b1_iin_handle) {
vpi_printf("VPI Programming Error. Handle Error.%x %x %x\n",rst_handle,rst_rk_handle,rl_b1_iin_handle);
vpi_sim_control(vpiFinish, 1);
return 0;
}
//rst
value.format = vpiScalarVal;
vpi_get_value(rst_handle, &value);
rst=value.value.scalar & 0x01;
//rst_rk
value.format = vpiScalarVal;
vpi_get_value(rst_rk_handle, &value);
rst_rk=value.value.scalar & 0x01;
//rl_b1_iin
value.format=vpiRealVal;
vpi_get_value(rl_b1_iin_handle, &value);
rl_b1_iin=value.value.real;
//読み込み終了
//本体始まり
//vpi_printf("rst==%d \n",rst);
if(rst==1) {
rl_x1=0;
rl_x2=0;
//ルンゲクッタ用
rl_b1_iin=0.0;
rst_rk_BK /*<*/= 1;//TODO
value.format=vpiScalarVal;
value.value.scalar=rst_rk_BK;
//vpi_printf("rst_rt_BK_handle=%x\n",rst_rk_BK_handle);
vpi_put_value(rst_rk_BK_handle, &value, NULL, vpiNoDelay);//;
h_n=h_n0;
// vpi_printf("h_n=%d h_n0=%d\n",h_n,h_n0);
} else {
//ルンゲクッタ: 2次と3次の埋め込み式
if(rst_rk==1) {
tmp_i1=h_n-cnt_dwn_rk;
tmp_i2=(tmp_i1 < 1)? 1: tmp_i1;
tmp_r1=h_n;
tmp_r2=tmp_i2;
tmp_r3=tmp_r2/tmp_r1;
// vpi_printf(" k2a=%g tmp_r1=%g h_n=%d\n",k2a,tmp_r1,h_n);
rl_x1 = rl_x1 +tmp_r3*k2a;//状態値の更新。
rl_x2 = rl_x2 +tmp_r3*k2b;//状態値の更新。
h_n=h_n0;
cnt_dwn_rk=h_n0;
cal_rk=1;
} else {
if(cnt_dwn_rk==0) {
rl_x1 = rl_x1 +k2a;//状態値の更新。
rl_x2 = rl_x2 +k2b;//状態値の更新。
h_n = (h_n << 2);
cnt_dwn_rk=h_n;
cal_rk=1;
}else
cal_rk=0;
}
if(cal_rk==1) {
while (cal_rk==1) {
//ルンゲクッタ計算のコア部。
tmp_r3=h_n;
// vpi_printf(" tmp_r3=%g rl_b1_iin=%g rl_x2=%g\n",tmp_r3,rl_b1_iin,rl_x2);
k1a=(a11*rl_x1 +a12*rl_x2 +rl_b1_iin)*tmp_r3;
k1b=(a21*rl_x1 +a22*rl_x2)*tmp_r3;
//vpi_sim_control(vpiStop, 1);
tmp_r1=rl_x1 +k1a*0.5;
tmp_r2=rl_x2 +k1b*0.5;
k2a=(a11*tmp_r1 +a12*tmp_r2 +rl_b1_iin)*tmp_r3;
k2b=(a21*tmp_r1 +a22*tmp_r2)*tmp_r3;
tmp_r1=rl_x1 -k1a +k2a*2;
tmp_r2=rl_x2 -k1b +k2b*2;
k3a=(a11*tmp_r1 +a12*tmp_r2 +rl_b1_iin)*tmp_r3;
k3b=(a21*tmp_r1 +a22*tmp_r2)*tmp_r3;
dif_x1=(-k1a +k2a*2.0 -k3a)/6.0;
dif_x2=(-k1b +k2b*2.0 -k3b)/6.0;
tmp_r3 = rl_x1 +(k1a +k2a*4 +k3a)/6.0;
tmp_r4 = rl_x2 +(k1b +k2b*4 +k3b)/6.0;
tmp_r1=(tmp_r3 > 0)? tmp_r3:-tmp_r3;
tmp_r2=(tmp_r4 > 0)? tmp_r4:-tmp_r4;
err_x1=tmp_r1*rl_relerr + rl_abserr;
err_x2=tmp_r2*rl_relerr + rl_abserr;
tmp_r1=(dif_x1 > 0)? dif_x1:-dif_x1;
tmp_r2=(dif_x2 > 0)? dif_x2:-dif_x2;
good_err=((err_x1 >= tmp_r1) && (err_x2 >= tmp_r2))? 1:0;
if((good_err==1 ) || (h_n==1)) {
rst_rk_BK /*<*/= 0;//TODO 初期化を解除。
value.format=vpiScalarVal;
value.value.scalar=rst_rk_BK;
//vpi_printf("rst_rt_BK_handle=%x\n",rst_rk_BK_handle);
vpi_put_value(rst_rk_BK_handle, &value, NULL, vpiNoDelay);//;
cal_rk = 0;//ルンゲクッタ計算ループから出る。
} else {
tmp_i1 = h_n >> 2;
h_n=(tmp_i1 < 1)? 1: tmp_i1;
hit_min_h=(tmp_i1 < 1)? (hit_min_h+1) : hit_min_h;
value.format=vpiIntVal;
value.value.integer=hit_min_h;
vpi_put_value(hit_min_h_handle, &value, NULL, vpiNoDelay);//
cnt_dwn_rk=h_n;
}
}
}
cnt_dwn_rk=cnt_dwn_rk-1;//ダウンカウンタのデクリメント。
}
tmp_r3=rl_x1*K_RTOI;
tmp32b_1=/*$rtoi( */tmp_r3;
if(tmp32b_1 >>31 /*[31]*/==0) //TODO
vout_BK /*<*/= (tmp32b_1 > tmp32b_lmtH)? tmp32b_lmtH /*[23:0]*/ : tmp32b_1 /*[23:0] */ ; //リミッタ。
else
vout_BK /*<*/ = (tmp32b_1 < tmp32b_lmtL)? tmp32b_lmtL/*[23:0] */ : tmp32b_1 /*[23:0] */;//リミッタ。
//本体終わり
//Verilogに値を戻す。ブロッキングアサインになるので、ノンブロッキングアサインは、Verilogで行う
value.format=vpiIntVal;
value.value.integer=vout_BK;
vpi_put_value(vout_BK_handle, &value, NULL, vpiNoDelay);//
return 0;
}
以上で、主要なルーチンは終わりです。$で呼び出す関数の登録をする部分です。
extern "C" void vco_entry()//VPI call/callback register routine
{
s_vpi_systf_data tf_data;
tf_data.type = vpiSysTask;//
tf_data.tfname = "$init_my_runge_kutta";
tf_data.user_data = 0;
tf_data.calltf = init_my_runge_kutta_calltf;
tf_data.compiletf = 0;
vpi_register_systf(&tf_data);
tf_data.type = vpiSysTask;//
tf_data.tfname = "$calc_my_runge_kutta";
tf_data.user_data = 0;
tf_data.calltf = calc_my_runge_kutta_calltf;
tf_data.compiletf = 0;
vpi_register_systf(&tf_data);
tf_data.type = vpiSysTask;//
tf_data.tfname = "$init_my_vco";
tf_data.user_data = 0;
tf_data.calltf = init_my_vco_calltf;
tf_data.compiletf = 0;
vpi_register_systf(&tf_data);
tf_data.type = vpiSysTask;//
tf_data.tfname = "$calc_my_vco";
tf_data.user_data = 0;
tf_data.calltf = calc_my_vco_calltf;
tf_data.compiletf = 0;
vpi_register_systf(&tf_data);
}
最後にこのエントリ関数をスタートアップ部で呼び出す形にして完成です。
# include "vpi_user.h"
extern void vco_entry(void);
__declspec(dllexport) void (*vlog_startup_routines[])() = {
vco_entry,
0
};
結果
VPIを用いた場合の比較結果です。
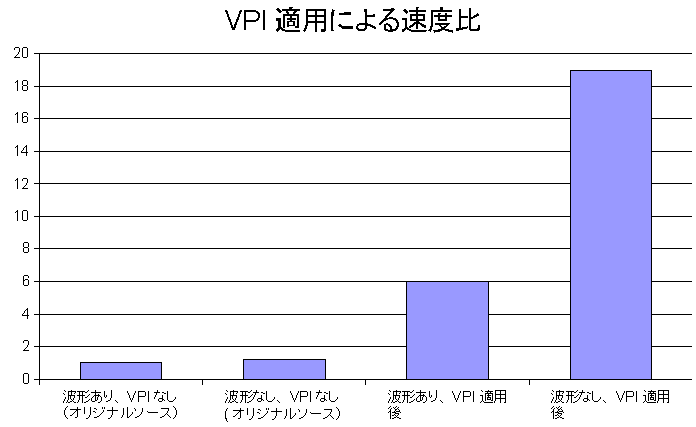
波形なしでは、18倍速になりました。(マシンはAthlon3800+DUAL 2GB Memory、Veritak.3.21B) 5分かかっていた処理が19secになりました。
C++への書き換えとデバッグ作業に約12時間程かかりましたが、一度雛形ができると、類似のプロジェクトでも利用できるために、利用価値は高いと言えます。
VPIは、Verilog-2001の規格ですが、SystemVerilogにおいても同じです。従い、折角書いたルーチンが無駄になる心配はありません。また、特にVendor毎に記述を変える必要はありません。
アーカイブ
筆者の方から許可をいただきました。この場を借りて厚く御礼申し上げます。
オリジナルソースとVPI適用後Verilog HDLソース/Veritak プロジェクト、 Project,VC++ソース/プロジェクトのアーカイブです。VPI有り・無し二つのプロジェクトが入っているので、簡単に差を体感できます。
vco.vtakprj VPIを使用しないVertak Projectです。
vco_tak.vtakprj VPIを使用したVeritak Projectです。(高速化Version)