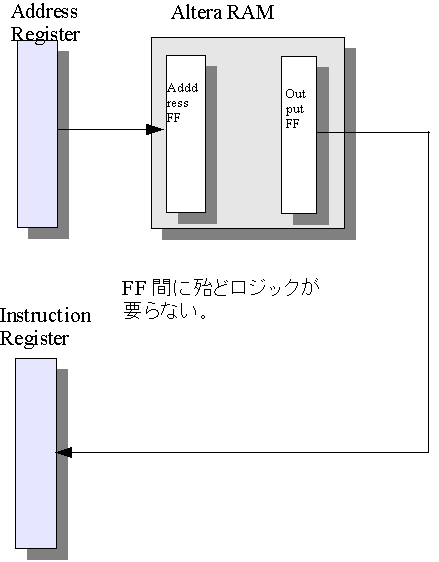
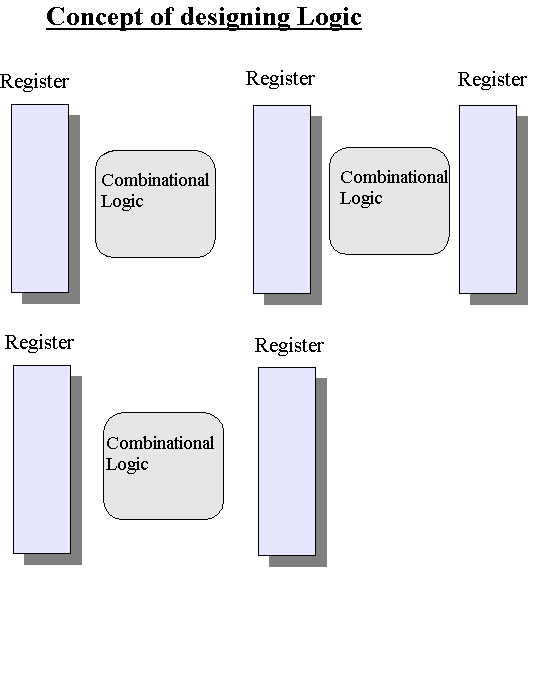
//May.16.2004
//ram偑擖偄傞偐専徹
//M-RAM偼丄MAX侾俁屄丂4KBitx13=53248偑幚幙偺忋尷偵側傞丅
//3port 偱偼丄256偱偼丄OK偩偑丄512偵側傞偲13屄埲忋梫傞偲尵傢傟NG
module h8_ram_module(clock,address,in_data,out_data_a,out_data_b,xout,wren,maddress,aclr);
input clock;
input [8:0] address,maddress;
input [7:0] in_data;
output [7:0] out_data_a,out_data_b;
output xout;
input wren;
input aclr;
wire [7:0] qa0,qa1,qa2,qa3,qa4,qa5,qa6,qa7;
wire [7:0] qb0,qb1,qb2,qb3,qb4,qb5,qb6,qb7;
wire [39:0] xq,data_w;
ram512x8 u0(.data_a(in_data),.data_b(in_data+1),.address_a(address),.address_b(address+1),
.wren_a(wren),.wren_b(!wren),.clock(clock),.q_a(qa0),.q_b(qb0));
ram512x8 u1(.data_a(in_data),.data_b(in_data+1),.address_a(address+1),.address_b(address+2),
.wren_a(wren),.wren_b(!wren),.clock(clock),.q_a(qa1),.q_b(qb1));
ram512x8 u2(.data_a(in_data),.data_b(in_data+1),.address_a(address+2),.address_b(address+3),
.wren_a(wren),.wren_b(!wren),.clock(clock),.q_a(qa2),.q_b(qb2));
ram512x8 u3(.data_a(in_data),.data_b(in_data+1),.address_a(address+3),.address_b(address+4),
.wren_a(wren),.wren_b(!wren),.clock(clock),.q_a(qa3),.q_b(qb3));
ram512x8 u4(.data_a(in_data),.data_b(in_data+1),.address_a(address+4),.address_b(address+5),
.wren_a(wren),.wren_b(!wren),.clock(clock),.q_a(qa4),.q_b(qb4));
ram512x8 u5(.data_a(in_data),.data_b(in_data+1),.address_a(address+5),.address_b(address+6),
.wren_a(wren),.wren_b(!wren),.clock(clock),.q_a(qa5),.q_b(qb5));
ram512x8 u6(.data_a(in_data),.data_b(in_data+1),.address_a(address+6),.address_b(address+7),
.wren_a(wren),.wren_b(!wren),.clock(clock),.q_a(qa6),.q_b(qb6));
ram512x8 u7(.data_a(in_data),.data_b(in_data+1),.address_a(address+7),.address_b(address+8),
.wren_a(wren),.wren_b(!wren),.clock(clock),.q_a(qa7),.q_b(qb7));
ram512x40 u8(.address(maddress),.clock(clock),.data(data_w),.wren(wren),.q(xq),.aclr(aclr));
assign data_w={in_data,in_data,in_data,in_data,in_data};
assign xout=^xq;
assign out_data_a=address%8==0 ? qa0 :
address%8==1 ? qa1 :
address%8==2 ? qa2 :
address%8==3 ? qa3 :
address%8==4 ? qa4 :
address%8==5 ? qa5 :
address%8==7 ? qa6 : qa7;
assign out_data_b=address%8==0 ? qb0 :
address%8==1 ? qb1 :
address%8==2 ? qb2 :
address%8==3 ? qb3 :
address%8==4 ? qb4 :
address%8==5 ? qb5 :
address%8==7 ? qb6 : qb7;
endmodule
|